支持 CNF 的 Heal 操作¶
https://blueprints.launchpad.net/tacker/+spec/support-cnf-heal
本文档描述了 Tacker 中容器化网络功能 (CNF) 的 VNF 生命周期管理中的“Heal VNF”操作。
问题描述¶
在 Victoria 版本中,spec ETSI NFV-SOL003 v2.6.1 中定义的 VNF 生命周期管理中的实例化和终止 VNF 操作,已在 spec container-network-function 中得到支持。也需要实现符合 ETSI 规范的 CNF heal 操作。但是,当前的 ETSI NFV-SOL 文档尚未定义基于 OS 容器的 VNF 的详细规范。本文档提供了 Tacker 中 CNF heal 操作的定义以及要实现的设计。
根据 ETSI NFV-SOL 文档,定义了两种不同类型的 heal 操作
使用 SOL003 Heal VNF 实例
使用 SOL002 Heal VNFC
提议的变更¶
本文档提出了 heal 操作及其设计的定义。
CNF healing 的定义¶
对于“使用 SOL003 Heal VNF 实例”,heal 操作被定义为 VNF 的终止和实例化。
对于“使用 SOL002 Heal VNFC”,Pod 映射到 VNFC。Pod 可以是单例,也可以使用 Kubernetes 中的控制器资源(例如 Deployment、DaemonSet、StatefulSet 或 ReplicaSet)创建。heal 操作被定义为删除 Pod。当 Pod 是单例时,需要创建一个新的 Pod,而对于控制器资源,则不需要 Pod 的重生,因为 Kubernetes 会自动创建一个新的 Pod。
注意
以下是在 Kubernetes 中定义为控制器资源
Deployment
DaemonSet
StatefulSet
ReplicaSet
Job
CronJob
Tacker 将支持单例 Pod 或使用 Deployment、DaemonSet、StatefulSet 和 ReplicaSet 创建的 Pod 的 heal 操作。使用 Job 和 CronJob 创建的 Pod 超出范围,因为不需要 heal 操作。
当用户执行“使用 SOL003 Heal VNF 实例”时,VNF 包中描述的所有 Kubernetes 资源将被重新创建,但是对于 StatefulSet 的情况,Kubernetes 自动创建的 PersistentVolumeClaim 分配的 PersistentVolume 不会被删除。此外,在“使用 SOL002 Heal VNFC”中,只有使用提供的 VNFC ID 指定的 Pod 会被重新创建,其他相关资源不会被删除。
heal 操作的设计¶
在执行 heal 操作之前,需要实例化包含资源的 CNF。Kubernetes Infra Driver 需要以下更改
验证目标 Kubernetes 资源以支持 heal 操作
通过重新创建单例 Pod 来 heal VNFC。
通过删除使用以下 Kubernetes 控制器资源创建的 Pod 来 heal VNFC
Deployment
DaemonSet
StatefulSet
ReplicaSet
存储和更新 VNFC 资源信息以进行 heal 操作
注意
使用 SOL003 的 VNF 实例 heal 操作已经实现为 VNF 的终止和实例化。
下图显示了已实例化的 CNF 的 CNF heal 操作
+--------------------+
| Heal Request with |
| additional Params |
+--------+-----------+
| 1. Request heal
| CNF
+--------+----------------+
| v |
| +-------------------+ |
| | Tacker-server | |
| +-----+-------------+ |
| | |
| v |
| +--------------------+ |
2. Heal CNF | | +--------------+ | |
+--------+-+--| Kubernetes | | |
+------------------+ 3. Re-create | | | | Infra Driver | | |
| | VNF or VNFC v | | +--------------+ | |
| +-----+ +-----+ | +------------+ | | | |
| | Pod | | Pod |<-+-------------| Kubernetes | | | | |
| +-----+ +-----+ | | cluster | | | | |
| | | (Master) | | | | |
| Kubernetes | +------------+ | | Tacker conductor | |
| cluster (Worker) | | +--------------------+ |
+------------------+ +-------------------------+
Tacker-server 接收来自用户的 heal 请求
Kubernetes Infra Driver 调用 Kubernetes 客户端 API 进行 heal(删除 Pod 或删除并创建 Kubernetes 资源)
Kubernetes Master 节点在 worker 节点上重新创建 Pod
示例 VNFD 文件
VNFD 需要将 VDU 定义为资源名称。以下是 Deployment 的示例。
tosca_definitions_version: tosca_simple_yaml_1_2
description: Deployment flavour for Kubernetes Cluster with
"pre_installed" flavour ID
imports:
- etsi_nfv_sol001_common_types.yaml
- etsi_nfv_sol001_vnfd_types.yaml
topology_template:
inputs:
descriptor_id:
type: string
descriptor_version:
type: string
provider:
type: string
product_name:
type: string
software_version:
type: string
vnfm_info:
type: list
entry_schema:
type: string
flavour_id:
type: string
flavour_description:
type: string
substitution_mappings:
node_type: Company.Tacker.KubernetesCluster
properties:
flavour_id: pre_installed
node_templates:
VNF:
type: Company.Tacker.Kubernetes
properties:
flavour_description: The pre_installed flavour
curry-test001:
type: tosca.nodes.nfv.Vdu.Compute
properties:
name: curry-test001
description: Deployment of Kubernetes resource
vdu_profile:
min_number_of_instances: 1
max_number_of_instances: 3
注意
对于 Heal 操作,用户需要在他们的 VNFD 中描述 tosca.nodes.nfv.Vdu.Compute,因为 Tacker 将 VnfcResourceInfo 存储在 VnfInstance.InstantiatedVnfInfo 中,数据类型为此。
示例 Kubernetes 对象文件
这是一个 Deployment 的示例。
apiVersion: apps/v1
kind: Deployment
metadata:
name: curry-test001
namespace: curryns
spec:
replicas: 2
selector:
matchLabels:
app: webserver
template:
metadata:
labels:
app: webserver
scaling_name: SP1
spec:
containers:
- env:
- name: param0
valueFrom:
configMapKeyRef:
key: param0
name: curry-test001
- name: param1
valueFrom:
configMapKeyRef:
key: param1
name: curry-test001
image: celebdor/kuryr-demo
imagePullPolicy: IfNotPresent
name: web-server
ports:
- containerPort: 8080
resources:
limits:
cpu: 500m
memory: 512M
requests:
cpu: 500m
memory: 512M
volumeMounts:
- name: curry-claim-volume
mountPath: /data
volumes:
- name: curry-claim-volume
persistentVolumeClaim:
claimName: curry-pv-claim
terminationGracePeriodSeconds: 0
以下 heal 参数用于“POST /vnf_instances/{id}/heal”,需要作为 HealVnfRequest 数据类型定义在 ETSI NFV-SOL002 v2.6.1 中
属性名称
参数描述
vnfcInstanceId
指示 Kubernetes 资源的 target,用户可以在“GET /vnf_instances/{id}”提供的
InstantiatedVnfInfo.vnfcResourceInfo中找到“vnfcInstanceId”。cause
不需要。
additionalParams
不需要。
healScript
不需要。
需要在 CNF 实例化操作期间将 Kubernetes 资源信息存储为“vnfcResourceInfo”在 InstantiatedVnfInfo 中。类型“vnfcResourceInfo”在 ETSI NFV-SOL003 v2.6.1 中定义。Kubernetes 资源信息将按以下方式存储在“vnfcResourceInfo”中
属性名称
基数
参数描述
id
1
vnfc 的 UUID
vduId
1
VNFD 中定义的 VDU 名称
computeResource
1
存储 Pod 信息
> vimConnectionId
0..1
不需要
> resourceProviderId
0..1
不需要
> resourceId
1
Pod 名称,在 Pod 创建后从 Kubernetes 集群获取信息
> vimLevelResourceType
0..1
存储 Kubernetes 资源类型
单例 Pod:“Pod”
由控制器资源创建的 Pod:控制器资源类型,例如“Deployment”等
storageResourceIds
0..N
不需要
reservationId
0..1
不需要
vnfcCpInfo
0..N
不需要
>id
1
不需要
>cpdId
1
不需要
>vnfExtCpId
0..1
不需要
>cpProtocolInfo
0..N
不需要
>vnfLinkPortId
0..1
不需要
>metadata
0..1
不需要
metadata
0..1
Kubernetes 对象文件中的 metadata
“vnfcResourceInfo.metadata”数据类型设计不佳,无法存储 CNF 的信息。因此,metadata 字段需要存储 Kubernetes 对象文件中定义的 metadata 和 spec.template.metadata,以保留控制器资源和 Pod 的 metadata。
{
"metadata": {
"Deployment": {
"name": "curry-test001",
"namespace": "curryns"
}
"Pod": {
"labels": {
"app": "webserver",
"scaling_name": "SP1"
}
}
}
}
以上是 Deployment 的一个例子。
“metadata”中的“key”设置为 Kubernetes 资源类型,例如“Deployment”等。而“metadata”中的“value”设置为每个定义中的“metadata”,在本例中设置为以下内容
“Deployment”的值设置为
Deployment.metadata(json 格式)“Pod”的值设置为
Deployment.spec.template.metadata(json 格式)
注意
存储在 computeResource 中的 Pod 名称与 Kubernetes 集群中实际的 Pod 名称不同,因为当 Kubernetes 自动 healing 或自动 scaling 工作时,Pod 名称可能会更改。需要在 CNF scaling 和 healing 期间同步 DB。
在 Instantiate VNF 中存储 VNFC 资源信息
在 Instantiate CNF 的操作期间,需要存储上述 VNFC 资源信息。以下序列图描述了相关组件和 CNF 实例化操作的流程
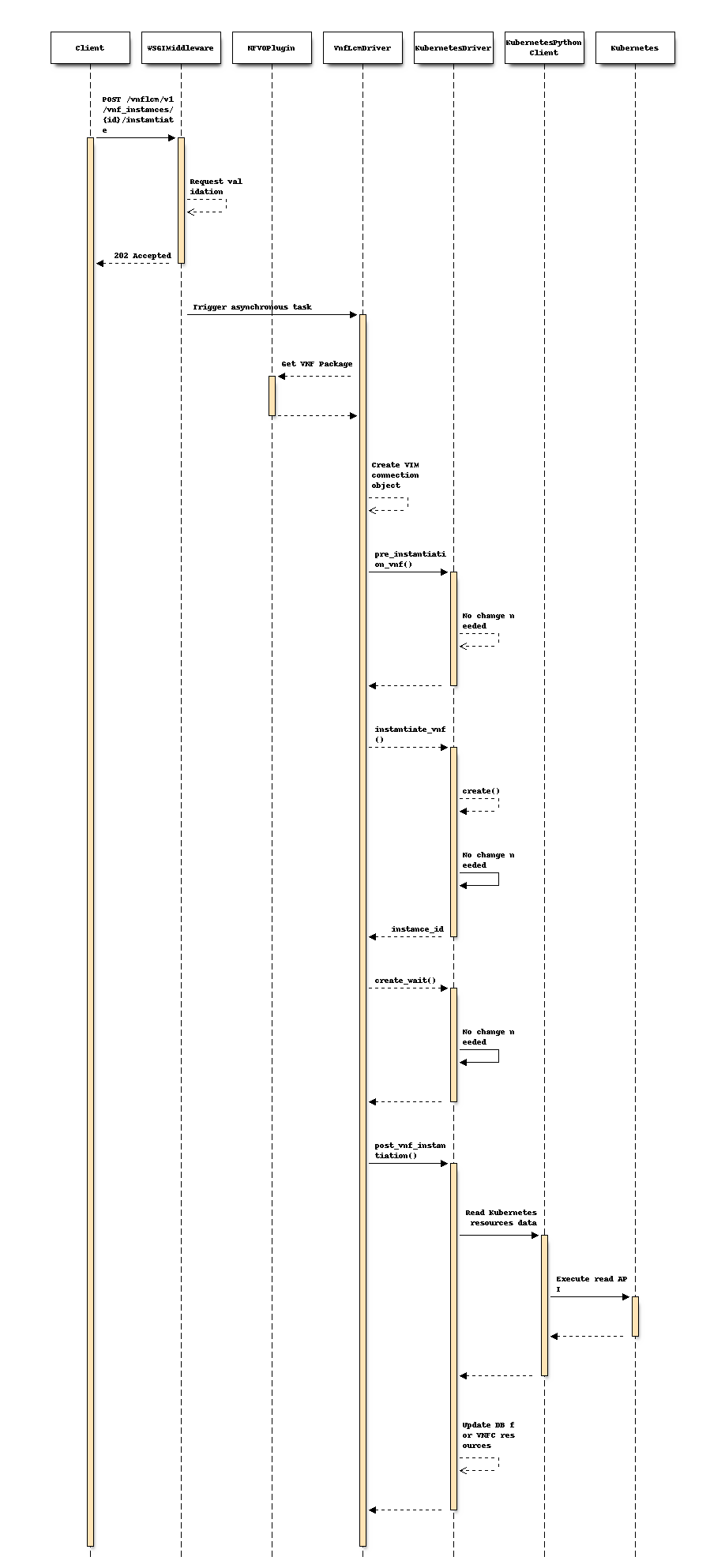
Tacker 接收用于实例化 CNF 的 POST 请求,并创建 Kubernetes 资源并验证创建,该处理在
Victoria版本中实现。在“post_vnf_instantiation()”方法中,KubernetesDriver 向 KubernetesPythonClient 发送 read API 请求,以存储有关资源(例如 pods、存储等)的信息到
vnfcResourceInfo(如果需要)。
注意
由于 Pod 名称在这些操作之后会更改,因此在 scaling 或 healing CNF 之后也需要更新 DB。
使用 SOL003 Heal VNF 实例¶
如果用户未指定任何 vnfcInstanceId,则 heal 操作运行终止和实例化操作以重新创建整个 VNF 实例。不需要从 spec etsi-nfv-sol-rest-api-for-VNF-deployment 中描述的当前实现进行更改。
注意
在 heal 操作期间实例化 CNF 时,通过读取 scaling 操作后存储的“InstantiatedVnfInfo.scale_status”来更改副本数。
使用 SOL002 Heal VNFC¶
如果用户指定 vnfcInstanceId,则 VNFC(Kubernetes 中的控制器资源,例如 Deployment、DaemonSet、StatefulSet 或 ReplicaSet)是 heal 操作的目标,并且可以使 VNFC 实例重生。
以下是 healing 请求体的示例
{
"vnfcInstanceId": "311485f3-45df-41fe-85d9-306154ff4c8d"
}
以下序列图描述了相关组件和 CNF heal 操作的流程
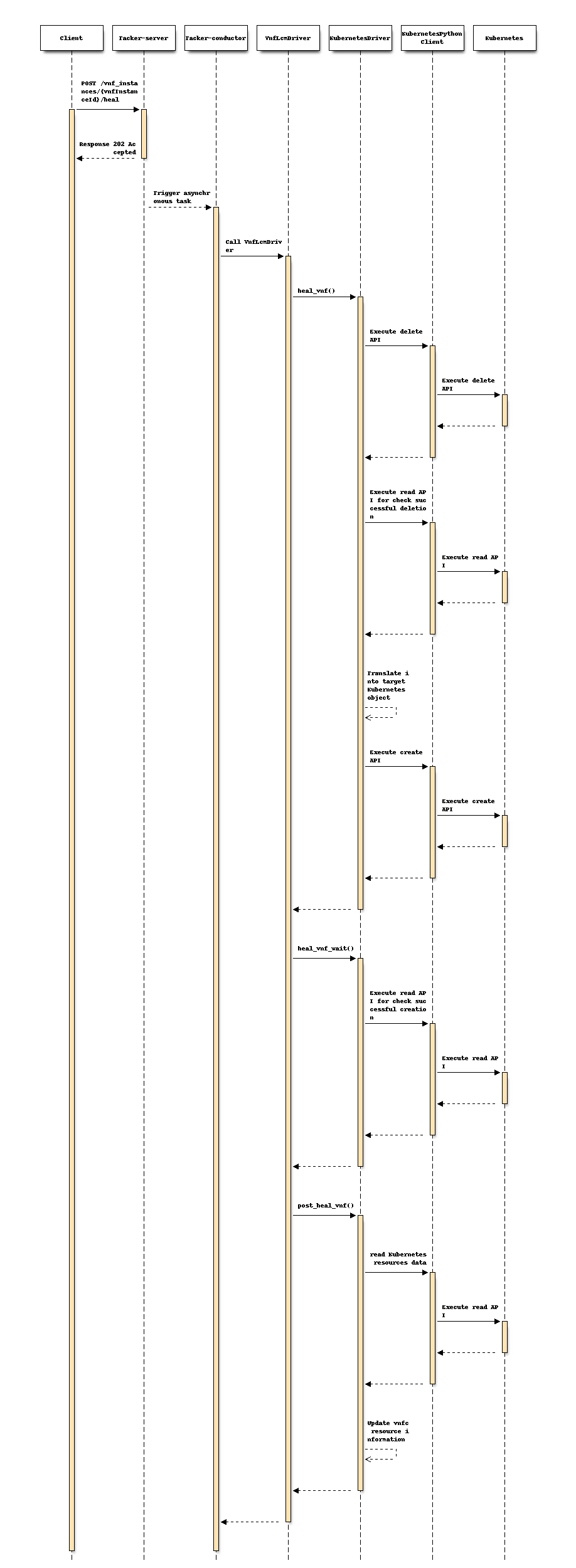
客户端向 Heal CNF 实例资源发送 POST 请求。
基本上与 spec support-notification-api-based-on-etsi-nfv-sol 中描述的相同序列,除了 Tacker-conductor 之外。在 CNF heal 操作的情况下,不需要 MgmtDriver 操作。
KubernetesDriver 使用 KubernetesPythonClient 向 Kubernetes 发送 delete 和 read API 请求,以删除 Kubernetes 资源并在 heal_vnf() 方法中检查删除是否成功。
如果删除成功,则从 Kubernetes 对象 YAML 文件中提取 heal 目标资源定义,将其转换为 Kubernetes 模型对象,然后 KubernetesDriver 使用 KubernetesPythonClient 向 Kubernetes 发送 create API 请求以重新创建 Kubernetes 资源。
注意
对于 Kubernetes 中控制器资源(例如 Deployment、DaemonSet、StatefulSet 或 ReplicaSet)创建的 Pod,不需要显式的删除过程,因为 Kubernetes 会自动重新生成 Pod。
注意
通过读取 scaling 操作后存储的“InstantiatedVnfInfo.scale_status”来更改 Kubernetes 模型对象中的副本数。
KubernetesDriver 使用 KubernetesPythonClient 向 Kubernetes 发送 read API 请求,以在 heal_vnf_wait() 方法中检查创建结果。
VnfLcmDriver 通过读取 Kubernetes 资源,在 post_heal_vnf() 方法中将 VNFC 资源信息更新到“VnfInstance.InstantiatedVnfInfo.vnfcResourceInfo”(如果创建成功)。
备选方案¶
无
数据模型影响¶
无
REST API 影响¶
无
安全影响¶
无
通知影响¶
无
其他最终用户影响¶
无
性能影响¶
无
其他部署者影响¶
无
开发人员影响¶
无
实现¶
负责人¶
- 主要负责人
- 其他贡献者
Ayumu Ueha <ueha.ayumu@fujitsu.com>
LiangLu <lu.liang@fujitsu.com>
工作项¶
验证目标 Kubernetes 资源以支持 heal 操作
Kubernetes Infra Driver 将被修改以实现
通过重新创建单例 Pod 来 Heal VNFC。
通过删除使用以下 Kubernetes 资源类型的 Pod 来 Heal VNFC
Deployment
DaemonSet
StatefulSet
ReplicaSet
存储和更新 VNFC 资源信息以进行 heal 操作
添加新的单元和功能测试。
依赖项¶
无
测试¶
将添加单元和功能测试,以涵盖规范所需的用例。
文档影响¶
将添加完整的用户指南来解释 CNF healing。
参考资料¶
无
