支持使用 Mgmtdriver 修复 Kubernetes Master/Worker 节点¶
https://blueprints.launchpad.net/tacker/+spec/mgmt-driver-for-k8s-heal
本规范描述了包含 Kubernetes 集群的 VNF 的 Heal 操作的增强。
问题描述¶
符合 ETSI 标准的 VNF Heal 操作已在 Ussuri 版本中实现,并在 Victoria 版本中更新以支持 Notification 和 Grant 操作。对于基于 OS 容器的 VNF,且包含 Kubernetes 集群的使用场景,支持集群管理至关重要。在本规范中,我们提出了当 VNF 由具有 mgmt-driver-for-k8s-cluster 规范的 Kubernetes 集群组成时,Kubernetes Master 或 Worker 节点的 Heal 操作。
为了支持修复 Kubernetes 集群节点,需要扩展 MgmtDriver。在使用 MgmtDriver 作为 VNF 生命周期管理接口,符合 ETSI NFV-SOL 003 [2] 部署 Kubernetes 集群后,需要相关的 heal 操作。在修复 Master 或 Worker 节点时,您不仅需要默认的 Heal 操作,还需要 heal_end 操作才能将节点注册到现有的 Kubernetes 集群。如果您想修复 Master 节点,则需要配置 etcd 和 HA 代理。另外,在修复 Worker 节点时,您需要应用所需的配置,并使其以与 scale-in 和 scale-out 相同的方式离开并加入集群。
提议的变更¶
支持两种 Heal 操作模式
基于 ETSI NFV-SOL002 [1] 修复 Kubernetes 集群中的单个节点(Master / Worker)。
修复 Kubernetes 集群的 Master 节点
删除失败的 Master 节点,创建一个新的 VM,并将新的 Master 节点合并到现有的 Kubernetes 集群中。MgmtDriver 还会修复配置为 Master 节点的 etcd 集群和负载均衡器。
修复 Kubernetes 集群的 Worker 节点
删除失败的 Worker 节点,创建一个新的 VM,并将新的 Worker 节点合并到现有的 Kubernetes 集群中。
基于 ETSI NFV-SOL003 [2] 修复整个 Kubernetes 集群。
注意
Kubernetes 集群中 Pod 的 Healing 超出了本规范的范围。
注意
故障检测也超出范围。假设用户对已知失败的节点执行 Heal 操作。
注意
Kubernetes v1.16.0和Kubernetes python客户端v11.0支持Kubernetes VIM。
用于 Healing 操作的 VNFD¶
VNFD 需要在接口中定义 heal_start 和 heal_end 定义,如下所示
node_templates:
VNF:
...
interfaces:
Vnflcm:
...
heal_start:
implementation: mgmt-drivers-kubernetes
heal_end:
implementation: mgmt-drivers-kubernetes
artifacts:
mgmt-drivers-kubernetes:
description: Management driver for kubernetes cluster
type: tosca.artifacts.Implementation.Python
file: /.../mgmt_drivers/kubernetes_mgmt.py
MasterVDU:
type: tosca.nodes.nfv.Vdu.Compute
...
WorkerVDU:
type: tosca.nodes.nfv.Vdu.Compute
...
Healing 操作的请求数据¶
用户将以下 heal 参数作为 HealVnfRequest 数据类型发送到“POST /vnf_instances/{id}/heal”。它与 SOL002 和 SOL003 不同。
在 ETSI NFV-SOL002 v2.6.1 [1]
属性名称
参数描述
vnfcInstanceId
用户指定 heal 目标,可以通过“GET /vnf_instances/{id}”响应中包含的
InstantiatedVnfInfo.vnfcResourceInfo来获取 “vnfcInstanceId”。cause
不需要
additionalParams
不需要
healScript
不需要
在 ETSI NFV-SOL003 v2.6.1 [2]
属性名称
参数描述
cause
不需要
additionalParams
不需要
Tacker 在 Ussuri 版本中,vnfcInstanceId、cause 和 additionalParams 均支持 SOL002 和 SOL003。
如果 vnfcInstanceId 参数为 null,则表示需要对整个 Kubernetes 集群进行 healing 操作,这是 SOL003 的情况。
以下是 SOL002 的 healing 请求体的示例
{
"vnfcInstanceId": "311485f3-45df-41fe-85d9-306154ff4c8d"
}
使用 SOL002 在 Kubernetes 集群中 Healing 节点¶
Healing Master 节点¶
需要进行以下更改
扩展 MgmtDriver 以支持
heal_start和heal_end在
heal_start中,目标节点通过从 etcd 集群中删除它并在 HA 代理中禁用负载均衡来从 Kubernetes 集群中移除。这些操作在 MgmtDriver 中调用的示例脚本中执行。在
heal_end中,MgmtDriver 调用一个示例脚本来安装和配置新的 Master 节点,将其添加到 etcd 集群,并注册到 HA 代理进行负载均衡。
注意
假设 Heal 操作所需的 MgmtDriver 中的信息存储在 Instantiate 和/或 Heal 请求的附加参数中。MgmtDriver 将它们传递给示例脚本。
下图显示了 Master 节点的 VNF Heal 操作
+---------------+
| Heal |
| Request with |
| Additional |
| Params |
+---+-----------+
|
+----------------+-----------+
| v VNFM |
| +-------------------+ |
| | Tacker-server | |
| +---------+---------+ |
| | |
4. heal_end | v |
Kubernetes cluster | +----------------------+ |
(Master) | | +-------------+ | |
+----------------------+--+----| MgmtDriver | | |
| | | +-----------+-+ | |
| | | | | |
| | | 1. heal_start | | |
| | | Kubernetes | | |
+--------------------+----------+ | | cluster | | |
| | | | | (Master)| | |
| | | | | | | |
| | | | | | | |
| +----------+ +---+------+ | | | | | |
| | | | v | | 3. Create | | +-----------+ | | |
| | +------+ | | +------+ | | new VM | | |OpenStack | | | |
| | |Worker| | | |Master| |<--------------+--+-|InfraDriver| | | |
| | +------+ | | +------+ | | | | +------+----+ | | |
| | VM | | VM | | | | | | | |
| +----------+ +----------+ | | | | | | |
| +----------+ +----------+ | 2. Delete | | | | | |
| | +------+ | | +------+ | | failed VM | | | | | |
| | |Worker| | | |Master| |<--+-----------+--+--------+ | | |
| | +------+ | | +------+ | | | | | | |
| | VM | | VM |<--+-----------+--+----------------+ | |
| +----------+ +----------+ | | | | |
+-------------------------------+ | | Tacker-conductor| |
+-------------------------------+ | +----------------------+ |
| Hardware Resources | | |
+-------------------------------+ +----------------------------+
该图显示了本规范提案的相关组件以及以下处理的概述
MgmtDriver 在删除失败的 VM 之前,在
heal_start中预处理以从现有的 etcd 集群中移除 Master 节点。通过通知其他活动的 Master 节点来从 etcd 集群中移除失败的 Master 节点。
通过更改 HA 代理设置从负载均衡目标中移除失败的 VM。
OpenStackInfraDriver 删除失败的 VM。
OpenStackInfraDriver 创建一个新的 VM 作为失败 VM 的替代品。
MgmtDriver 在
heal_end中修复 Kubernetes 集群。MgmtDriver 在新的 VM 上设置新的 Master 节点。此设置过程可以使用 shell 脚本或包含安装和配置任务的 python 脚本来实现。
如果 Heal 目标是 Master 节点,则调用脚本来修复 etcd 集群。
调用脚本来更改 HA 代理配置。
注意
预计通过检查 Heal 请求中的 vnfcInstanceId 参数来识别失败的 VM。如果此参数为 null,则表示需要完全重建。这些过程在 etsi-nfv-sol-rest-api-for-VNF-deployment 规范中定义 [3]。
注意
为了识别新创建的 VM,假设需要引用诸如 Heal 之前的 Worker 节点 VM 数量以及每个 VM 的创建时间等信息。
以下序列图描述了涉及的组件以及 Healing Master 节点操作的流程
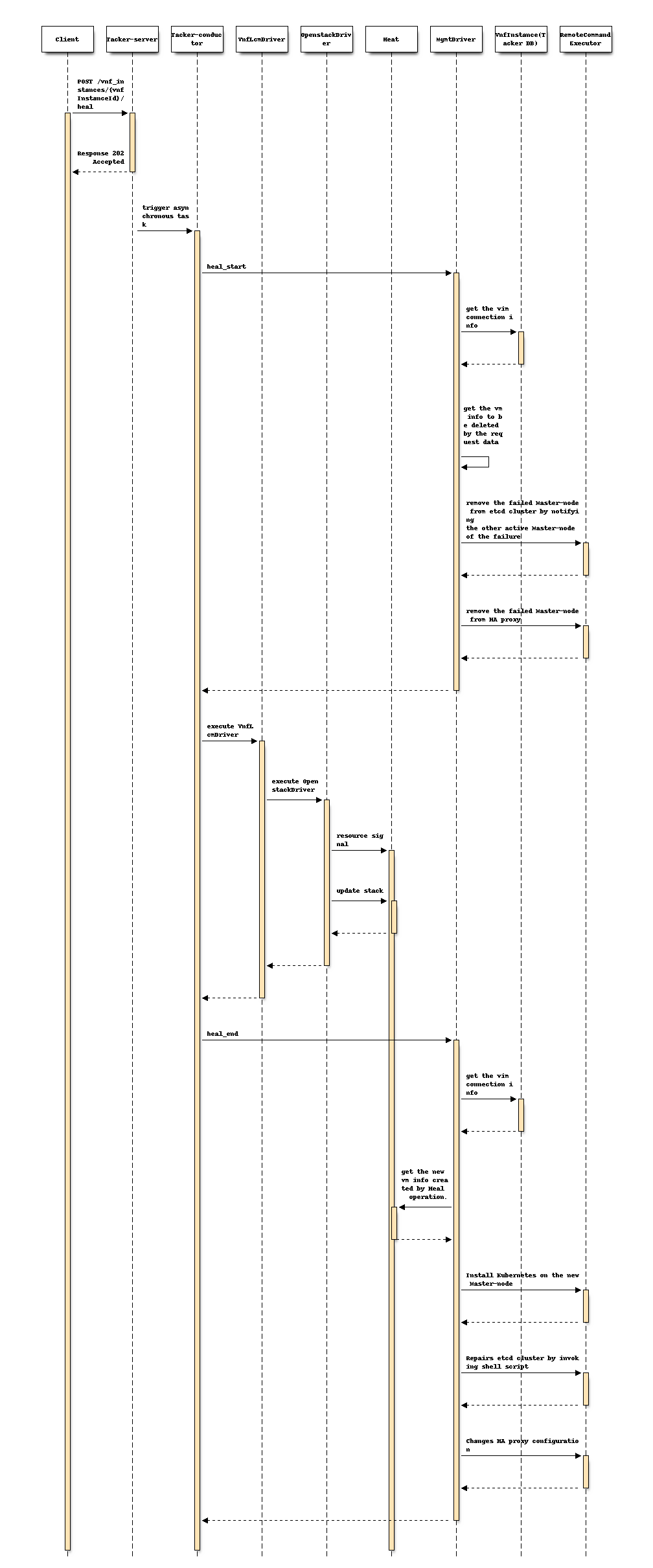
该过程包括以下步骤,如图所示
客户端向 Heal VNF Instance 资源发送 POST 请求。
基本上与 spec etsi-nfv-sol-rest-api-for-VNF-deployment 的“3) VNF 实例 Heal 流程”章节中描述的序列相同,除了 MgmtDriver 之外。
以下过程在
heal_start中执行。MgmtDriver 获取 Vim 连接信息,以便获取失败的 Kubernetes 集群信息,例如 auth_url。
MgmtDriver 通过检查 Heal 请求中的 vnfcInstanceId 参数来获取失败的 VM 信息。
MgmtDriver 通过通知其他活动的 Master 节点来从 etcd 集群中移除失败的 Master 节点。
MgmtDriver 通过更改 HA 代理设置从负载均衡目标中移除失败的 VM。
OpenStack Driver 使用 Heat 删除失败的 VM。
OpenStack Driver 使用 Heat 创建一个新的 VM。
以下流程在
heal_end中执行。MgmtDriver 获取 Vim 连接信息,以便获取现有的 Kubernetes 集群信息,例如 auth_url。
MgmtDriver 从 Heat 中的堆栈资源获取新的 VM 信息。
MgmtDriver 通过使用 RemoteCommandExecutor 调用 shell 脚本来安装和配置 VM 上的 Master 节点。
MgmtDriver 通过使用 RemoteCommandExecutor 调用 shell 脚本将新的 Master 节点添加到 etcd 集群。
MgmtDriver 通过使用 RemoteCommandExecutor 调用 shell 脚本来更改 HA 代理配置。
Healing Worker 节点¶
需要进行以下更改
扩展 MgmtDriver 以支持
heal_start和heal_end在
heal_start中尝试将正在失败的 VM 上运行的 pod 迁移到另一个 worker 节点。
通过通知现有的 Master 节点来移除失败的 Worker 节点。
在
heal_end中与 spec mgmt-driver-for-k8s-scale 中描述的
scale_end相同。MgmtDriver 在
heal_end中在新的 VM 上设置新的 Worker 节点。此设置过程可以使用 shell 脚本或包含安装和配置任务的 python 脚本来实现。
注意
假设 Heal 操作所需的 MgmtDriver 中的信息存储在 Instantiate 和/或 Heal 请求的附加参数中。MgmtDriver 将它们传递给示例脚本。
下图显示了 Worker 节点的 VNF Heal 操作
+---------------+
| Heal |
| Request with |
| Additional |
| Params |
+---+-----------+
|
+----------------+-----------+
| v VNFM |
| +-------------------+ |
| | Tacker-server | |
| +---------+---------+ |
| | |
4. heal_end | v |
Kubernetes cluster | +----------------------+ |
(Worker) | | +-------------+ | |
+----------------------+--+----| MgmtDriver | | |
| | | +-----------+-+ | |
| | | | | |
| | | 1. heal_start | | |
| | | Kubernetes | | |
+--------------------+----------+ | | cluster | | |
| | | | | (Worker)| | |
| | | | | | | |
| | | | | | | |
| +----------+ +---+------+ | | | | | |
| | | | v | | 3. Create | | +-----------+ | | |
| | +------+ | | +------+ | | new VM | | |OpenStack | | | |
| | |Master| | | |Worker| |<--------------+--+-|InfraDriver| | | |
| | +------+ | | +------+ | | | | +------+----+ | | |
| | VM | | VM | | | | | | | |
| +----------+ +----------+ | | | | | | |
| +----------+ +----------+ | 2. Delete | | | | | |
| | +------+ | | +------+ | | failed VM | | | | | |
| | |Master| | | |Worker| |<--+-----------+--+--------+ | | |
| | +------+ | | +------+ | | | | | | |
| | VM | | VM |<--+-----------+--+----------------+ | |
| +----------+ +----------+ | | | | |
+-------------------------------+ | | Tacker-conductor| |
+-------------------------------+ | +----------------------+ |
| Hardware Resources | | |
+-------------------------------+ +----------------------------+
该图显示了本规范提案的相关组件以及以下处理的概述
MgmtDriver 在删除失败的 VM 之前,在
heal_start中预处理以从 Kubernetes 集群中移除 Worker 节点。尝试将正在失败的 VM 上运行的 pod 迁移到另一个 worker 节点。
通过通知现有的 Master 节点来移除失败的 Worker 节点。
OpenStackInfraDriver 删除失败的 VM。
OpenStackInfraDriver 创建一个新的 VM 作为失败 VM 的替代品。
MgmtDriver 在
heal_end中修复 Kubernetes 集群。此 Heal 过程基本上与 spec mgmt-driver-for-k8s-scale 中描述的
scale_end相同。MgmtDriver 在
heal_end中在新的 VM 上设置新的 Worker 节点。此设置过程可以使用 shell 脚本或包含安装和配置任务的 python 脚本来实现。
注意
预计通过检查 Heal 请求中的 vnfcInstanceId 参数来识别失败的 VM。如果此参数为 null,则表示需要完全重建。这些过程在 etsi-nfv-sol-rest-api-for-VNF-deployment 规范中定义 [3]。
注意
为了识别新创建的 VM,假设需要引用诸如 Heal 之前的 Worker 节点 VM 数量以及每个 VM 的创建时间等信息。
以下序列图描述了涉及的组件以及 Healing Worker 节点操作的流程
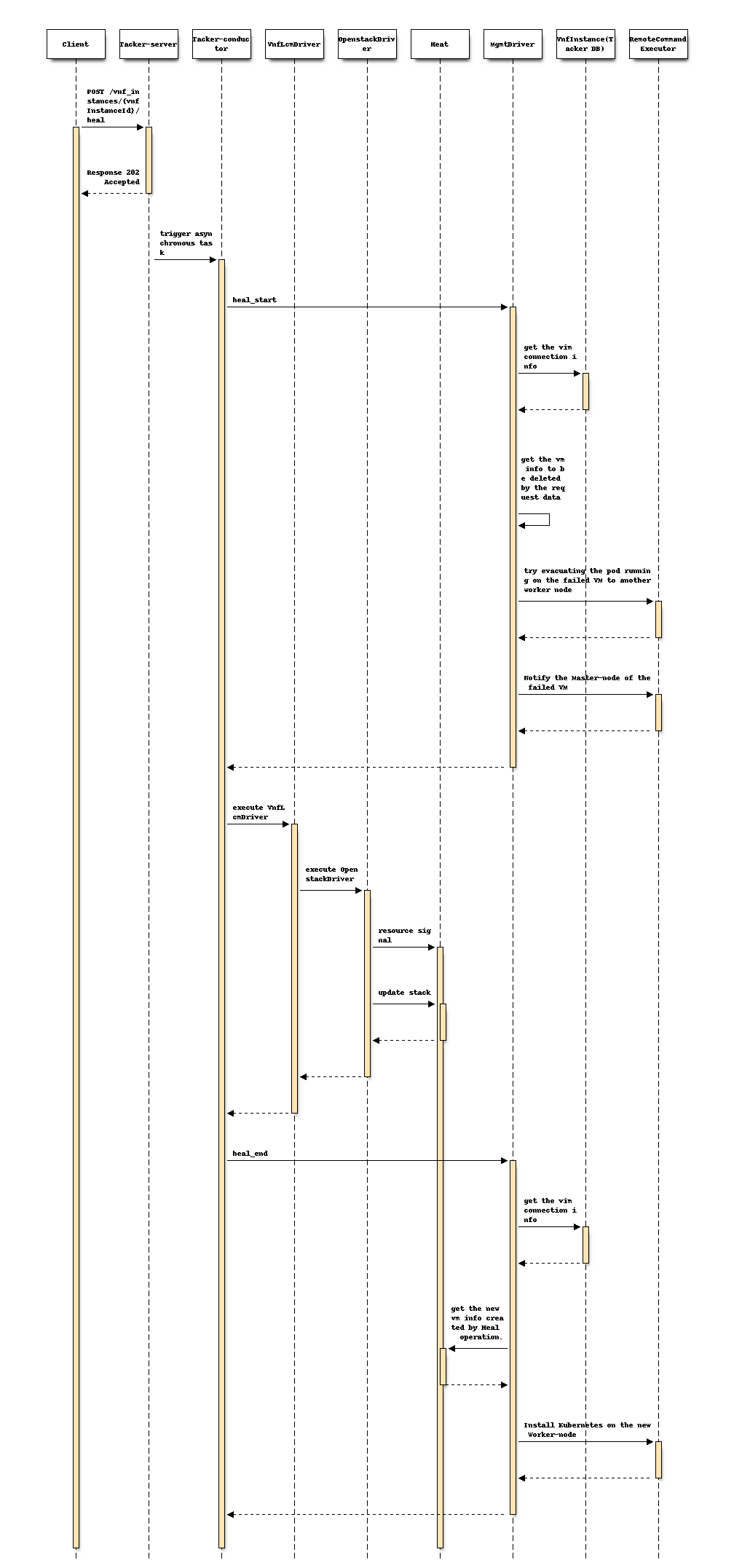
该过程包括以下步骤,如图所示
客户端向 Heal VNF Instance 资源发送 POST 请求。
基本上与 spec etsi-nfv-sol-rest-api-for-VNF-deployment 的“3) VNF 实例 Heal 流程”章节中描述的序列相同,除了 MgmtDriver 之外。
以下过程在
heal_start中执行。MgmtDriver 获取 Vim 连接信息,以便获取失败的 Kubernetes 集群信息,例如 auth_url。
MgmtDriver 通过检查 Heal 请求中的 vnfcInstanceId 参数来获取失败的 VM 信息。
尝试将正在失败的 VM 上运行的 pod 迁移到另一个 worker 节点。
通过通知现有的 Master 节点来移除失败的 Worker 节点。
OpenStack Driver 使用 Heat 删除失败的 VM。
OpenStack Driver 使用 Heat 创建一个新的 VM。
以下流程在
heal_end中执行。MgmtDriver 获取 Vim 连接信息,以便获取现有的 Kubernetes 集群信息,例如 auth_url。
MgmtDriver 从 Heat 中的堆栈资源获取新的 VM 信息。
MgmtDriver 通过使用 RemoteCommandExecutor 调用 shell 脚本在 VM 上设置 Worker 节点。
使用 SOL003 Healing Kubernetes 集群¶
基本上,整个 Kubernetes 集群的 Heal 操作基于 mgmt-driver-for-k8s-cluster 规范,该规范指定了实例化和终止的操作。对于在 Heal 操作中删除现有资源,heal_start 与 terminate_end 相同,对于在 Heal 操作中生成新资源,heal_end 与 instantiate_end 相同。在 Heal 整个 VNF 实例期间,必须删除 VIM 信息,并且存储在 VNF 实例表中的 vim_connection_info 中的旧 Kubernetes 集群信息也必须清除。这些操作需要在 heal_start 和 terminate_end 中实现。
以下序列图描述了涉及的组件以及 Heal 整个 VNF 实例操作的流程
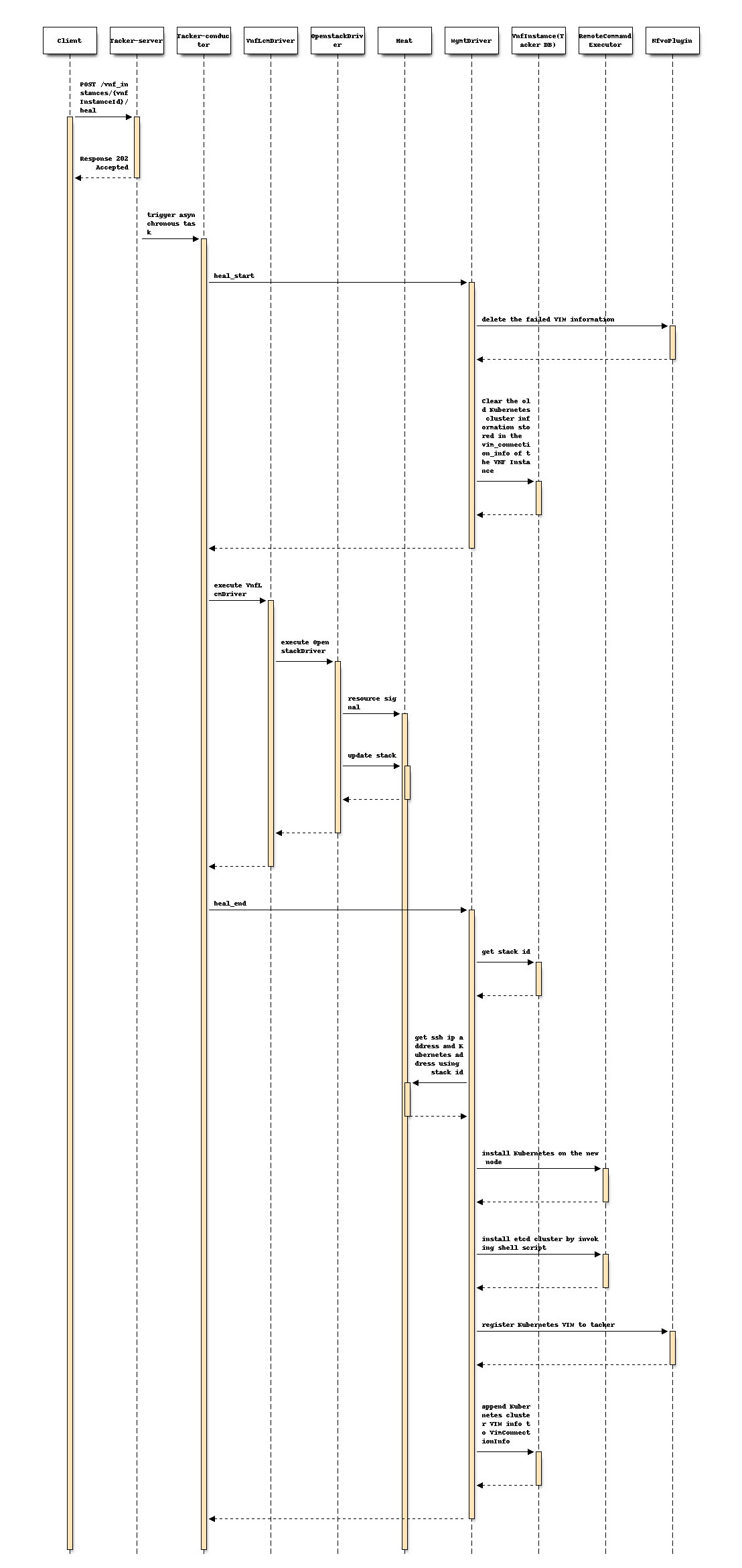
该过程包括以下步骤,如图所示
客户端向 Heal VNF Instance 资源发送 POST 请求。
基本上与 spec etsi-nfv-sol-rest-api-for-VNF-deployment 的“3) VNF 实例 Heal 流程”章节中描述的序列相同,除了 MgmtDriver 之外。
heal_start的工作方式与 mgmt-driver-for-k8s-cluster 的 terminate_end 相同。OpenStack Driver 使用 Heat 删除失败的 VM。
OpenStack Driver 使用 Heat 创建一个新的 VM。
heal_end的工作方式与 mgmt-driver-for-k8s-cluster 的 instantiate_end 相同。
备选方案¶
无
数据模型影响¶
无
REST API 影响¶
无
安全影响¶
无
通知影响¶
无
其他最终用户影响¶
无
性能影响¶
无
其他部署者影响¶
无
开发人员影响¶
无
实现¶
负责人¶
- 主要负责人
- 其他贡献者
Shotaro Banno <banno.shotaro@fujitsu.com>
Ayumu Ueha <ueha.ayumu@fujitsu.com>
陆梁 <lu.liang@fujitsu.com>
工作项¶
MgmtDriver将被修改以实现
在
heal_start和heal_end中支持 Kubernetes 节点的 Healing。MgmtDriver 执行以下示例脚本
将新的 Master 节点合并到现有的 etcd 集群中。
由于在
heal_start和heal_end过程中旧 VM 和新 VM 的替换而更改 HA 代理设置
添加新的单元和功能测试。
依赖项¶
本规范依赖于以下规范
heal_end 在“Proposed change”中引用的是 mgmt-driver-for-k8s-cluster 规范中的 instantiate_end。假设 Kubernetes 集群是 HA 配置,如 mgmt-driver-for-ha-k8s 规范中所述,对单个 Master 节点执行 Healing 操作。此外,对单个 Worker 节点执行 Healing 操作参考 mgmt-driver-for-k8s-scale 以获取 scale_start。
测试¶
将添加单元和功能测试,以涵盖规范所需的用例。
文档影响¶
将添加完整的用户指南,以从 VNF LCM API 的角度解释 Kubernetes 集群 Healing。
