支持k8s集群中pod的硬件感知亲和性¶
https://blueprints.launchpad.net/tacker/+spec/hardware-aware-pod-affinity
问题描述¶
在部署具有“CNF支持ETSI NFV规范”蓝图的Kubernetes集群的VNF的情况下[1],Pod可能会被调度到同一个物理计算服务器上,而它们被标记了反亲和性规则[2]。反亲和性规则可以将Pod部署到不同的worker节点上,但这些worker节点可能在同一服务器上。在本规范中,我们提出了一种针对Pod的硬件感知亲和性。
提议的变更¶
本规范提出了具有硬件感知亲和性的pod部署操作的设计。假设在Worker节点部署为VNF-A进程时会提供一个标签,并且基于此标签,在VNF-B进程中确定部署pod的Worker节点。需要进行以下更改。
VNF-A:创建一个VM,设置Kubernetes集群并为Worker节点设置标签。
MgmtDriver设置
label,基于新创建的Worker节点部署在哪个计算服务器上,通过在VNF-A实例化过程的instantiate_end中调用一个shell脚本。
此外,本规范假设每个Worker节点都部署到不同的计算服务器,这可以使用反亲和性机制来完成。但是,由于Heat-translator不支持此参数,因此在TOSCA文件中使用反亲和性设置部署VM不受支持,而TOSCA v1.2具有定义。因此,需要进行以下修改。
Heat-translator将TOSCA文件中定义的反亲和性设置转换为Heat模板。
VnflcmDriver基于Heat模板中指定的反亲和性设置,将Worker节点部署到不同的计算服务器上。
注意
另一方面,使用在BaseHOT中描述的实例化中的UserData方法,无需更改现有的Tacker实现。LCM-operation-with-user-data
VNF-B:在VNF-A内部的Kubernetes集群上部署CNF,并且VNFC(Pod)在由标签选择的Worker节点上创建。
无需更改VNF-B的现有Tacker实现。CNF的实例化操作与CNF-with-VNFM-and-CISM规范中描述的相同。请注意,Kubernetes对象文件必须包含反亲和性机制的定义,以满足此具有硬件感知亲和性的pod部署操作的规范。
注意
Kubernetes v1.16.0和Kubernetes python客户端v11.0支持Kubernetes VIM。
VNF-A:创建一个VM,设置Kubernetes集群并设置标签¶
基本上,该规范基于mgmt-driver-for-k8s-cluster。作为一项额外的更改,我们建议通过标记Worker节点来支持硬件感知亲和性的pod部署操作。
下图显示了为新创建的Worker节点分配标签
+-----------+ +-----------+ +---------+ +--------+
| Heat | | LCM | | Cluster | | |
| Template | | operation | | Install | | VNFD |
| (BaseHOT) | | UserData | | Script | | |
+-----+-----+ +-----+-----+ +-------+-+ +-+------+
| | | |
| | v v +---------------+
| | +----------+ | Instantiation |
| +----------->| | | Request with |
| | CSAR | | Additional |
-------------------------->| | | Params |
+----+-----+ +--------+------+
| |
+----------+ |
| |
| |1.Instantiate
| | VNF
+--+--------+------------+
| v v |
+-------------------+ | +------------------+ |
| | | | Tacker-server | |
| +-----+ | | +------------------+ |
| | Pod | | | | |
| +-----+ | | +----------+ |
| |<----+ | +------------------+ | |
| Kubernetes | | +------------+ | | +--------------+ | | |
| cluster(Worker02) |<-+ | | Kubernetes | | | | Kubernetes | | | |
+-------------------+ | | | cluster | | | | InfraDriver | | | |
+-------------------+ | | | (Master) |<--+ | | | | | | |
| Compute02 | | | +------------+ | | | +--------------+ | | |
+-------------------+ | | 3.Setup new | | | | | |
| | Worker-node | | | +-------------+ | | |
| | and set label | | | | MgmtDriver | | | |
+-------------------+ | | during k8s cluster | | | +-----+-------+ | | |
| | | | installation | | | | |<+ |
| +-----+ |<-|--+----------------------+--+-+--------+ | |
| | Pod | | | | | | +-------------+ | |
| +-----+ | | | | | |OpenStack | | |
| |<-+ | | | |InfraDriver | | |
| Kubernetes | | | | | +-----+-------+ | |
| cluster(Worker01) | | 2. Create VMs | | | | | |
+-------------------+ +-------------------------+--+-+--------+ | |
+-------------------+ | | Tacker conductor | |
| Compute01 | | +------------------+ |
+-------------------+ +------------------------+
该图显示了本规范提案的相关组件以及以下处理的概述
Tacker-server接收用户发起的VNF实例化请求。
OpenStackInfraDriver在构建初始Kubernetes集群时创建新的VM。
MgmtDriver在新的VM上设置新的Worker节点,并通过调用shell脚本来设置
label,基于新创建的Worker节点部署在哪个计算服务器上。这些过程与mgmt-driver-for-k8s-cluster规范中描述的相同,除了设置label的过程之外。
注意
使用Kubernetes AntiAffinity机制可以满足本规范的要求。Worker节点可以使用以下类型的拓扑键进行标记:hostname、zone等。当,例如,引用hostname时,可以从多个worker节点中选择一个特定的节点。基于此标签,可以通过AntiAffinity的逻辑确定部署pod的节点。但是,该规范要求您控制pod部署到哪个计算服务器的哪个节点上,因此需要使用zone的拓扑键。
注意
上图假设新生成的Worker节点基于硬件服务器的主机名,为zone的拓扑键进行标记。
如果Worker节点在Computer01中创建,则标记如下
kubernetes.io/zone=Compute01
如果Worker节点在Computer02中创建,则标记如下
kubernetes.io/zone=Compute02
实例化CSAR包的所需组件¶
假设本规范可以通过两种方式满足。一种是UserData方法,需要在BaseHOT中定义相关设置,另一种是SOL 001中指定的TOSCA方法。
BaseHOT:此UserData方法不需要任何Tacker实现更改。BaseHOT需要配置包含反亲和性策略定义的
srvgroup。TOSCA:此方法需要在“HeatTranslator”的翻译过程中为
AntiAffinityRule和PlacementGroup参数提供新的支持。
VNFD & BaseHOT定义
VNFD
VNFD与mgmt-driver-for-k8s-cluster规范的“VNFD for Kube-adm with TOSCA template”章节中描述的相同。
Heat模板
需要定义如下所示的
srvgroup。parameters: ... srvgroup_name: type: string description: Name of the ServerGroup default: ServerGroup resources: srvgroup: type: OS::Nova::ServerGroup properties: name: { get_param: srvgroup_name } policies: [ 'anti-affinity' ] masterNode: type: OS::Heat::AutoScalingGroup properties: desired_capacity: 3 max_size: 5 min_size: 3 ... scheduler_hints: group: { get_resource: srvgroup } workerNode: type: OS::Heat::AutoScalingGroup properties: desired_capacity: 3 max_size: 5 min_size: 3 ... scheduler_hints: group: { get_resource: srvgroup }
带有TOSCA模板的VNFD
它基本上与mgmt-driver-for-k8s-cluster规范的“VNFD for Kube-adm with TOSCA template”章节中描述的相同,但需要添加以下设置。
targets的min_number_of_instances必须设置为2或更高。需要添加
PlacementGroup和AntiAffinityRule。
node_template: ... masterNode: type: tosca.nodes.nfv.Vdu.Compute ... workerNode: type: tosca.nodes.nfv.Vdu.Compute properties: name: workerNode description: workerNode vdu_profile: max_number_of_instances: 5 min_number_of_instances: 3 groups: antiAffinityGroup: type: tosca.groups.nfv.PlacementGroup members: [ masterNode, workerNode ] policies: policy_antiaffinity_group: type: tosca.policies.nfv.AntiAffinityRule targets: [ antiAffinityGroup ] properties: scope: nfvi_node scaling_aspects: type: tosca.policies.nfv.ScalingAspects properties: aspects: worker_instance: name: worker_instance_aspect description: worker_instance scaling aspect max_scale_level: 2 step_deltas: - delta_1 masterNode_initial_delta: type: tosca.policies.nfv.VduInitialDelta properties: initial_delta: number_of_instances: 1 targets: [ masterNode ] masterNode_scaling_aspect_deltas: type: tosca.policies.nfv.VduScalingAspectDeltas properties: aspect: worker_instance deltas: delta_1: number_of_instances: 1 targets: [ workerNode ] workerNode_initial_delta: type: tosca.policies.nfv.VduInitialDelta properties: initial_delta: number_of_instances: 1 targets: [ workerNode ] workerNode_scaling_aspect_deltas: type: tosca.policies.nfv.VduScalingAspectDeltas properties: aspect: worker_instance deltas: delta_1: number_of_instances: 1 targets: [ workerNode ]
请求数据(BaseHOT/TOSCA)¶
BaseHOT
以下是VNF实例化请求POST /vnflcm/v1/vnf_instances/{vnfInstanceId}/instantiate中提供的body示例
{ "flavourId": "cluster_install", "additionalParams": { "lcm-operation-user-data": "UserData/base_user_data.py", "lcm-operation-user-data-class": "BaseUserData", "input_params":"" }, "vimConnectionInfo": [ { "id": "8a3adb69-0784-43c7-833e-aab0b6ab4470", "vimId": "7dc3c839-bf15-45ac-8dff-fc5b95c2940e", "vimType": "openstack" } ] }
TOSCA
以下是VNF实例化请求POST /vnflcm/v1/vnf_instances/{vnfInstanceId}/instantiate中提供的body示例
{ "flavourId": "cluster_install", "additionalParams": { "input_params":"" }, "vimConnectionInfo": [ { "id": "8a3adb69-0784-43c7-833e-aab0b6ab4470", "vimId": "7dc3c839-bf15-45ac-8dff-fc5b95c2940e", "vimType": "openstack" } ] }
以下序列图描述了涉及的组件以及实例化VNF操作的流程,其中新的Worker节点设置了zone的标签
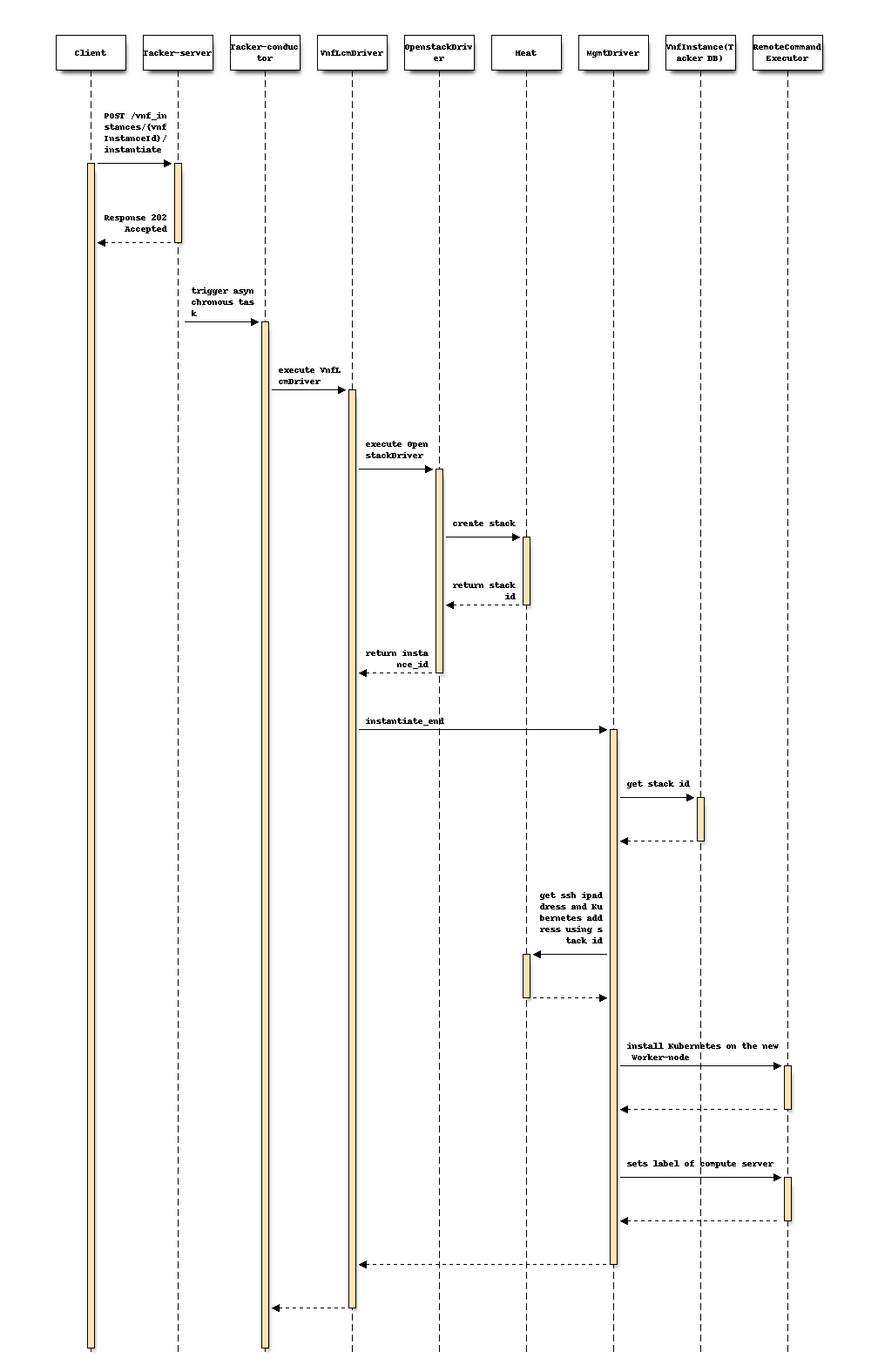
该过程由上述序列中说明的以下步骤组成。
客户端发送“instantiate”作为POST请求。
基本上与etsi-nfv-sol-rest-api-for-VNF-deployment规范的“2) VNF实例的实例化流程”章节中描述的相同序列,除了MgmtDriver之外。
以下流程在
instantiate_end中执行。MgmtDriver从Heat获取新的VM信息。
MgmtDriver通过shell脚本在新的Worker节点上安装Kubernetes,如mgmt-driver-for-k8s-cluster规范中描述的那样
注意
为了简单起见,此处省略了Master节点安装过程。
MgmtDriver通过调用shell脚本来设置
label,基于新创建的Worker节点部署在哪个计算服务器上。
注意
此标签设置过程还需要添加到scale_end和heal_end中。有关详细信息,请参阅mgmt-driver-for-k8s-scale和mgmt-driver-for-k8s-heal规范。
注意
此序列是在使用BaseHOT的前提下描述的。如果使用TOSCA方法,则需要修改“HeatTranslator”的翻译过程,如etsi-nfv-sol-rest-api-for-VNF-deployment规范的“2) VNF实例的实例化流程”章节中描述的,关于对AntiAffinityRule和PlacementGroup参数的新支持。
VNF-B:在VNF-A内部的Kubernetes集群上部署CNF¶
基本上,该规范基于CNF-with-VNFM-and-CISM。Pod在哪个Worker节点上生成是根据标签确定的。
下图显示了pod基于分配给Worker节点的标签进行部署。
+-----------+ +-----------+ +---------+ +--------+
| Heat | | LCM | | Cluster | | |
| Template | | operation | | Install | | VNFD |
| (BaseHOT )| | UserData | | Script | | |
+-----+-----+ +-----+-----+ +-------+-+ +-+------+
| | | |
| | v v +---------------+
| | +----------+ | Instantiation |
| +----------->| | | Request with |
| | CSAR | | Additional |
-------------------------->| | | Params |
+----+-----+ +--+------------+
| | 1.Instantiate
+----------+ | CNF
| |
| |
| |
+--+--+------------------+
2.Instantiate | v v |
+-------------------+ VNFC(Pod) | +------------------+ |
| | on the Worker-node | | Tacker-server | |
| +-----+ | selected by label | +---+--------------+ |
| | Pod |<----------+--------+ | | |
| +-----+ | | | v |
| | | | +------------------+ |
| Kubernetes | | +------------+ | | +--------------+ | |
| cluster(Worker02) | | | Kubernetes | | | | Kubernetes | | |
+-------------------+ +--+ cluster |------+-+-| InfraDriver | | |
+-------------------+ | (Master) | | | | | | |
| Compute02 | +------------+ | | +--------------+ | |
+-------------------+ | | | |
| | +-------------+ | |
| | | Mgmt Driver | | |
+-------------------+ | | +-------------+ | |
| | | | | |
| +-----+ | | | | |
| | Pod | | | | +-------------+ | |
| +-----+ | | | |OpenStack | | |
| | | | |Infra Driver | | |
| Kubernetes | | | +-------------+ | |
| cluster(Worker01) | | | | |
+-------------------+ | | | |
+-------------------+ | | Tacker conductor | |
| Compute01 | | +------------------+ |
+-------------------+ +------------------------+
该图显示了本规范提案的相关组件以及以下处理的概述
Tacker-server接收用户发起的CNF实例化请求。
KubernetesInfraDriver调用Kubernetes客户端API进行实例化,然后Kubernetes集群在指定的计算服务器中的Worker节点上实例化pod。
VNFD - Kubernetes对象文件¶
Kubernetes对象文件需要具有以下示例中的affinity定义
apiVersion: apps/v1
kind: Deployment
metadata:
name: redis-cache
spec:
selector:
matchLabels:
app: store
replicas: 2
template:
metadata:
labels:
app: store
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- store
topologyKey: kubernetes.io/zone
containers:
- name: redis-server
image: redis:3.2-alpine
注意
以上是使用podAntiAffinity在zone(此处意味着计算服务器)上部署新pod的示例配置。需要注意的是,requirdedDirectionSchedulingIgnoredDuringExecution参数是一个表示如果不存在满足此条件的部署位置,则pod部署将不会执行的参数。另一方面,如果指定preferredDuringSchedulingIgnoredDuringExecution,则将部署pod。
实例化CNF操作的请求数据和序列与CNF-with-VNFM-and-CISM规范中描述的相同。
备选方案¶
无
数据模型影响¶
无
REST API 影响¶
无
安全影响¶
无
通知影响¶
无
其他最终用户影响¶
无
性能影响¶
无
其他部署者影响¶
无
开发人员影响¶
无
实现¶
负责人¶
- 主要负责人
- 其他贡献者
Shotaro Banno <banno.shotaro@fujitsu.com>
LiangLu <lu.liang@fujitsu.com>
Ayumu Ueha <ueha.ayumu@fujitsu.com>
工作项¶
MgmtDriver将被修改以实现
在
instantiate_end、scale_end和heal_end中识别新的worker节点部署在哪个计算服务器上。提供一个示例脚本,供MgmtDriver执行,以使用计算服务器信息在worker节点上设置zone标签。
根据方法,需要以下更改之一
BaseHOT:此UserData方法不需要任何Tacker实现更改。BaseHOT需要配置包含反亲和性策略定义的
srvgroup。TOSCA:此方法需要在“HeatTranslator”的翻译过程中为
AntiAffinityRule和PlacementGroup参数提供新的支持。
添加新的单元和功能测试。
依赖项¶
“Proposed Changes”中引用的instantiate_end与mgmt-driver-for-k8s-cluster规范相同。
测试¶
将添加单元和功能测试,以涵盖规范所需的用例。
文档影响¶
将添加完整的用户指南,以从VNF LCM API的角度解释具有硬件感知亲和性的pod部署操作。
