为 Watcher 提供评分模块¶
https://blueprints.launchpad.net/watcher/+spec/scoring-module
Watcher 决策引擎 目前允许定义多个 目标 并实施几种 策略 来实现它们。然而,在一些更高级的场景中,策略 可能会使用机器学习模型,这些模型可以使用外部机器学习引擎进行训练和评估。
此蓝图旨在提供一个通用的评分引擎模块,它将通过通用的 API 标准化与评分引擎的交互。此外,不同的 策略 也可以使用评分引擎,这将提高代码和数据模型的重用性。
评分模块将是独立的和可选的。任何 策略 都不需要使用它。
问题描述¶
目前,策略 实现可以自由使用任何算法或任何外部框架来实现给定的 目标。没有标准的接口或 API 可以帮助在不同的 策略 之间共享这些算法或框架。
应该能够独立于 策略 实现评分引擎。一旦实现了预测或分类器,就可以共享和重用它们,从而实现更高级的 策略,这些策略甚至可以使用多个评分引擎。
用例¶
作为开发者,我希望能够列出可用的评分引擎。这样我就可以快速识别它们并在我的策略中重用可用的预测结果,例如虚拟机能量消耗的预测、虚拟机的预测 CPU 等。
作为开发者,我希望能够在优化 策略 中创建和使用评分引擎。这样我就可以快速切换评分引擎或实现同一评分引擎的多个版本(例如,使用不同的数据集进行学习)。
作为开发者,我希望能够在无需升级 Watcher 的情况下配置多个评分引擎。
作为开发者,我希望能够在单个插件中提供一个动态的评分引擎列表。这样我就可以在不重新启动任何 Watcher 服务的情况下注册/注销类似类型的评分引擎。
作为开发者,在实现新的 策略 时,我希望以类似的方式使用不同的评分引擎(可能来自不同的供应商),使用类似的 API。
作为开发者,我希望获取有关给定评分引擎的元数据信息。元数据可能包含有关如何使用特定评分引擎的重要信息,例如:输入参数的数量(例如,特征数量)、响应格式(例如,分类器使用的标签顺序)。
项目优先级¶
不相关,因为 Watcher 目前不在大型帐篷内。
提议的变更¶
建议在 决策引擎 中定义一个抽象层,它将提供一个抽象的 ScoringEngine 类,所有评分引擎都必须实现该类,以及一个 ScoringFactory 类,策略 实现将使用该类来选择要使用的评分引擎。
使用场景¶
以下图表展示了最基本的场景
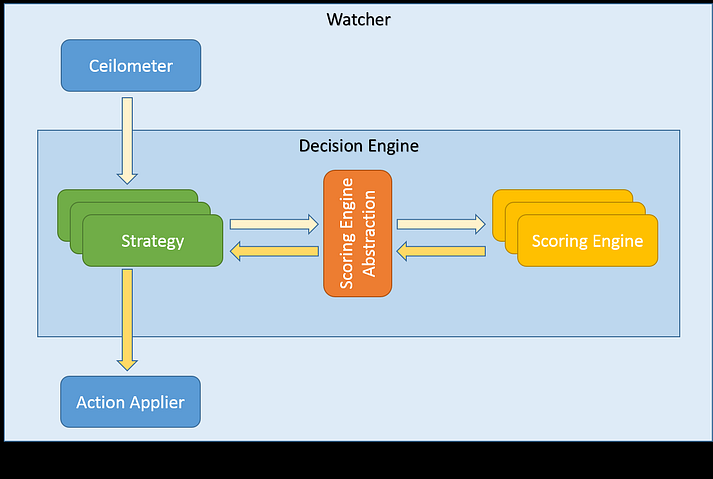
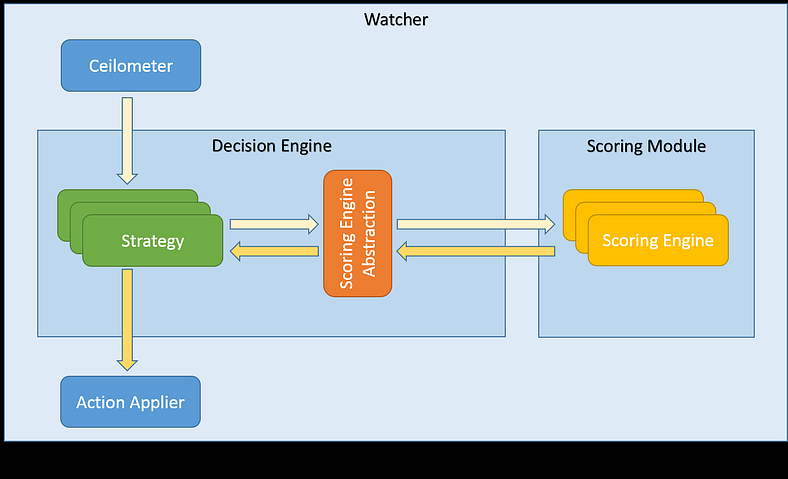
重要的是要注意,评分引擎可能具有不同的要求,并且实现可能有所不同。其中一些可能被实现为纯 Python 类,执行(可能很繁重)的计算。在这种情况下,委托给 Watcher 评分模块是有意义的,它将是一个新的 Watcher 服务,类似于 Watcher 决策引擎 或 Watcher Applier
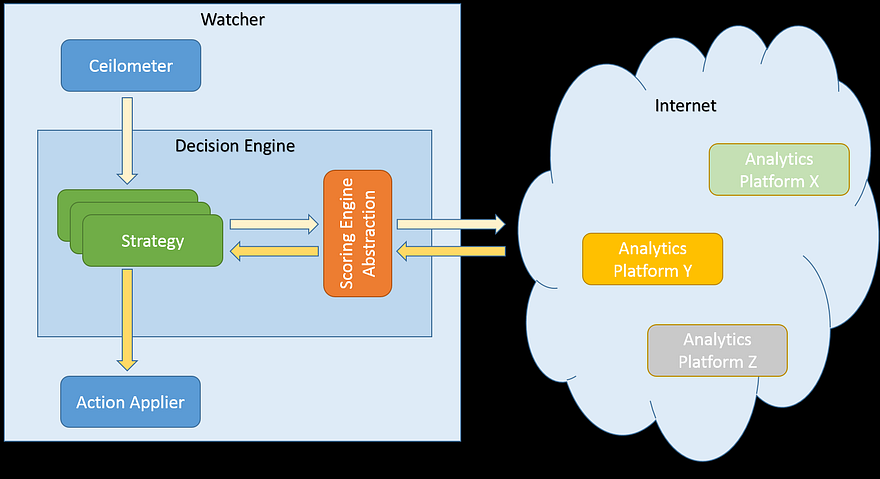
其他一些评分引擎可能使用外部框架实现,甚至完全存在于云中,仅公开一些 API 来与其交互。在这种情况下,抽象层将简单地将工作委托给这些外部系统(例如,使用一些 HTTP 客户端库),如图所示
实现细节¶
这会对评分模块的设计和实现产生影响。上述抽象层的目标是允许两者
任何 策略 简单地使用任何评分引擎。
实现自由:如果评分引擎执行一些繁重的计算,其实现可以移动到外部进程,这不会影响 Watcher 决策引擎 模块。
也就是说,将实施以下更改
在 watcher/common 包中
ScoringEngine 类定义了所有评分引擎实现的基础抽象类。抽象类将包括以下抽象方法
- get_engine_id:
方法将返回评分引擎的唯一字符串标识符。此 ID 将由工厂类和希望使用特定评分引擎的 策略 使用
- 输入:
无
- 结果:
唯一的字符串 ID(必须在所有评分引擎中唯一)
- get_model_metadata:
方法将返回一个包含数据模型元数据的映射。这可能包括有关所用算法的信息、数据返回标签(对于解释结果很有用)
- 输入:
无
- 结果:
字典,键和值均为字符串
例如,元数据可以包含以下信息(实际示例)
评分引擎是一个分类器,它基于具有这些列标签的学习数据(最后一列是用于学习的结果):[MEM_USAGE, PROC_USAGE, PCI_USAGE, POWER_CONSUMPTION, CLASSIFICATION_ID]
在学习过程中,机器学习决定它实际上只需要这些列来计算预期的 CLASSIFICATION_ID:[MEM_USAGE, PROC_USAGE]
因为评分结果是双精度数字列表,我们需要知道它的含义,例如:0.0 == CLASSIFICATION_ID_2,1.0 == CLASSIFICATION_ID_1 等。
无法保证输入/输出列表中的列的顺序甚至存在性
此信息必须作为元数据传递,以便评分引擎的用户能够“理解”结果
此外,元数据可能提供一些见解,例如用于学习的算法或用于训练的记录数量
- calculate_score:
负责执行实际评分的方法,例如对数据进行分类或预测
- 输入:
浮点数列表(例如,特征值)
- 结果:
浮点数列表(例如,分类值、预测结果)
在 Watcher 决策引擎 中
在 Watcher API 中
新的 REST 资源 URL 以暴露评分引擎列表及其元数据(只读)
GET /v1/scoring_engines/
GET /v1/scoring_engines/(scoring_engine_uuid)
在 Watcher CLI 中
在命令行中公开新的 API
新的 Watcher 评分模块
新的顶级 scoring_engine 目录位于 Watcher 源代码中的 watcher 目录中。
一个新的服务:watcher-scoring。
一个示例评分引擎(不使用任何外部依赖项)。
部署¶
评分引擎实现的部署模型将使用 Stevedore 插件模型。将为抽象层和 Watcher 评分模块定义入口点。抽象层部分需要实现,而 Watcher 评分模块部分是可选的(例如,当使用在云中运行的外部分析平台时,不需要它)。

此外,将能够从单个插件注册多个评分引擎。评分引擎列表也将是动态的,这意味着可以在不重新启动 Watcher 服务的情况下注册和注销评分引擎。
评分引擎版本控制¶
与 API 版本控制类似的规则应适用于评分引擎版本控制。评分引擎将使用其唯一的 ID 进行标识。评分引擎的新版本应具有不同的 ID,这样就不会破坏现有的用法。当然,评分引擎开发者可以选择更新现有的评分引擎(因此更新版本的 ID 保持不变),但她/他应该为此承担全部责任,并了解这可能会改变其他用例。建议仅对小的错误修复更新评分引擎,并为使用不同的机器学习算法或使用不同的学习数据训练的评分引擎提供新的 ID。
备选方案¶
每个开发者都可以实现一个新的 策略,使用与机器学习框架的自定义集成。数据模型和评分引擎的创建相对困难且耗时,因此如果它们不能被更广泛地使用,那将是一大损失。
数据模型影响¶
无
REST API 影响¶
无
安全影响¶
将有一个新的 Watcher 评分模块服务,这意味着打开了额外的网络端口,这始终会增加安全影响。
通知影响¶
无
其他最终用户影响¶
无
性能影响¶
无
其他部署者影响¶
在交付新的评分引擎时,操作员将部署以下软件
必需
实现评分引擎的主要 Python 类
新的评分引擎实现所需的所有其他资源或类(例如,与外部服务通信的客户端代码,如果评分引擎在云中实现和托管)
可选
开发人员影响¶
无
实现¶
负责人¶
- 主要负责人
tkaczynski
工作项¶
预见的工件列表
审查此蓝图,根据收到的反馈进行改进
实现通用的 Watcher 评分模块
实现评分引擎加载器
实现一个示例评分引擎,以演示评分模块设计并提供使用指南(无外部依赖项)
实现一个示例 策略,使用上一点中的示例评分引擎
提供新评分模块的文档
使用与 Watcher 评分相关的术语更新词汇表
提供一个指南/教程,说明如何实现评分引擎插件
依赖项¶
没有直接依赖项。
但是,从长远来看,Watcher 应该提供一个灵活的插件模型,该模型允许轻松地将评分引擎、策略 和 操作 与 Watcher 集成,而无需重新安装或升级它。理想的情况是,第三方开发者将在单独的存储库中提供实现,然后可以将这些实现包含在 Watcher 的一个配置文件中。解决此问题不在本文档的范围内。
测试¶
需要为新的计分模块中的代码编写单元测试。 实现此模块对现有的 Watcher 代码库是透明的,因此不会影响现有的测试或功能。
文档影响¶
需要更新文档,尤其是术语表,以便解释关于计分模块定义和计分引擎实现的新的概念。
需要更新 API 文档和 Watcher 用户指南,以演示如何获取有关可用计分引擎及其元数据的相关信息。
架构描述也需要更新,因为将提供一个新的 Watcher 组件。
关于 Watcher 安装和配置的文档也需要更新,以便解释
如何将新的计分引擎部署到 Watcher
如何将 策略 与现有的计分引擎集成
参考资料¶
无
历史¶
无
