集群模型对象包装器¶
https://blueprints.launchpad.net/watcher/+spec/cluster-model-objects-wrapper
当前,每次执行策略时都会构建一个集群模型,这在生产环境或更大环境中将无法扩展。如果 Watcher 打算被更大的环境使用,它需要一种更可靠的方式来构建和维护集群模型。可以通过来自感兴趣服务的通知以及定期同步逻辑来构建并保持这个模型的内存缓存。
问题描述¶
如上所述,Watcher 当前通过 get_latest_cluster_data_model() 方法在每次执行策略时构建集群模型。 截至今天,Watcher 只有一个模型收集器定义 (NovaClusterModelCollector)。 该方法然后使用 nova API 从 Nova 获取所有超visor,然后为每个超visor 获取该超visor 上的所有服务器。 对于这些超visor 和服务器中的每一个,都会创建一个 Watcher 模型对象来表示 API JSON 响应中的实体。 这些对象被放置在一个集合中(集群数据模型),然后传递给策略的 execute() 方法。 然后策略使用此模型做出某些决策。
不幸的是,在规模合理的产品环境中,以这种方式构建集群模型将无法扩展。 考虑一个具有数百个计算节点和数万个服务器的环境。 如果 Watcher 需要每次用户想要运行审计时都构建此表示,那么运行审计可能会非常慢。 此外,考虑一个繁忙的环境,在短时间内请求了大量的审计 - Watcher 需要通过 API 请求向每个感兴趣的服务构建最新的集群模型,这对整个系统造成了很大的压力,几乎没有收益,假设环境在每次审计请求之间几乎没有变化。
理想情况下,策略可以使用集群模型的内存缓存来立即做出明智的决策,而无需 Watcher 查询每个服务以获取其最新的表示。 这在实施连续审计时将特别重要,这将需要定期且频繁地做出决策。
用例¶
主要用例是解决可扩展性问题。 由于构建集群模型的延迟最小,策略可以执行得更快,从而更快地向 Watcher 的最终用户交付审计。 它还将减少对整个 OpenStack 部署的负载,因为消除了冗余 API 请求。
对于 Watcher 的开发人员来说,这将创建一个方便的方式来获取和使用当前的集群模型。
项目优先级¶
高
提议的变更¶
Watcher 应该提供多个集群模型收集器(重用 BaseClusterModelCollector 类),这些收集器负责维护其关联集群的内存缓存。 例如,NovaClusterModelCollector 类将维护所有超visor 和每个超visor 上服务器的缓存。 在未来,这可能会扩展到例如 CinderClusterModelCollector 类,它将维护所有存储提供程序和块设备(例如,卷)的缓存。
这些集群模型收集器将由现有的 CollectorManager 类管理,该类需要更新以维护对每个收集器类实例的引用,而不是在每次调用 get_cluster_model_collector() 时实例化一个新的收集器。 还应添加方法以允许获取可用收集器的列表和获取特定收集器。
BaseClusterModelCollector 的每个实现将继续提供类似于当前 get_latest_cluster_data_model 的方法,但它将从其内部缓存中获取模型,而不是从服务本身获取模型。
以下是描述检索所有集群数据模型工作流程的序列图
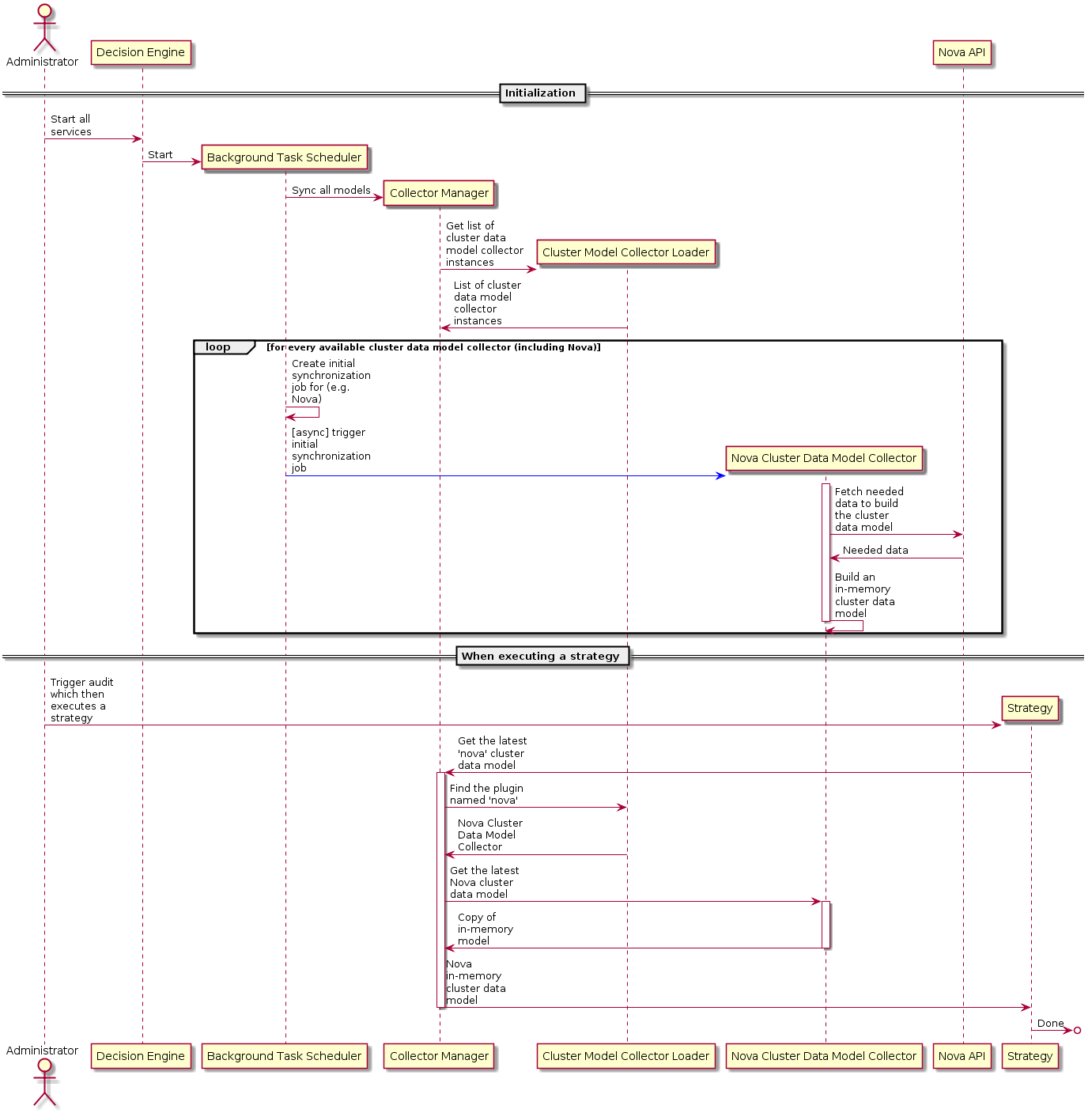
BaseClusterModelCollector 的每个实现应在实例化时开始填充其内存缓存,最好不要阻塞其他代码执行以快速启动服务。 这些实现还应定义定期任务,这些任务负责(最好通过使用线程异步方式)与服务同步缓存。 例如,对于 NovaClusterModelCollector,此定期任务将负责向 Nova 发出 API 请求以获取所有超visor 和服务器。 根据该 API 请求的响应,将相应地更新缓存。 这些同步任务的运行速率应该是可配置的,但一个合理的默认值可能在每 60 分钟左右。
以下是描述定期同步所有集群数据模型的流程的序列图
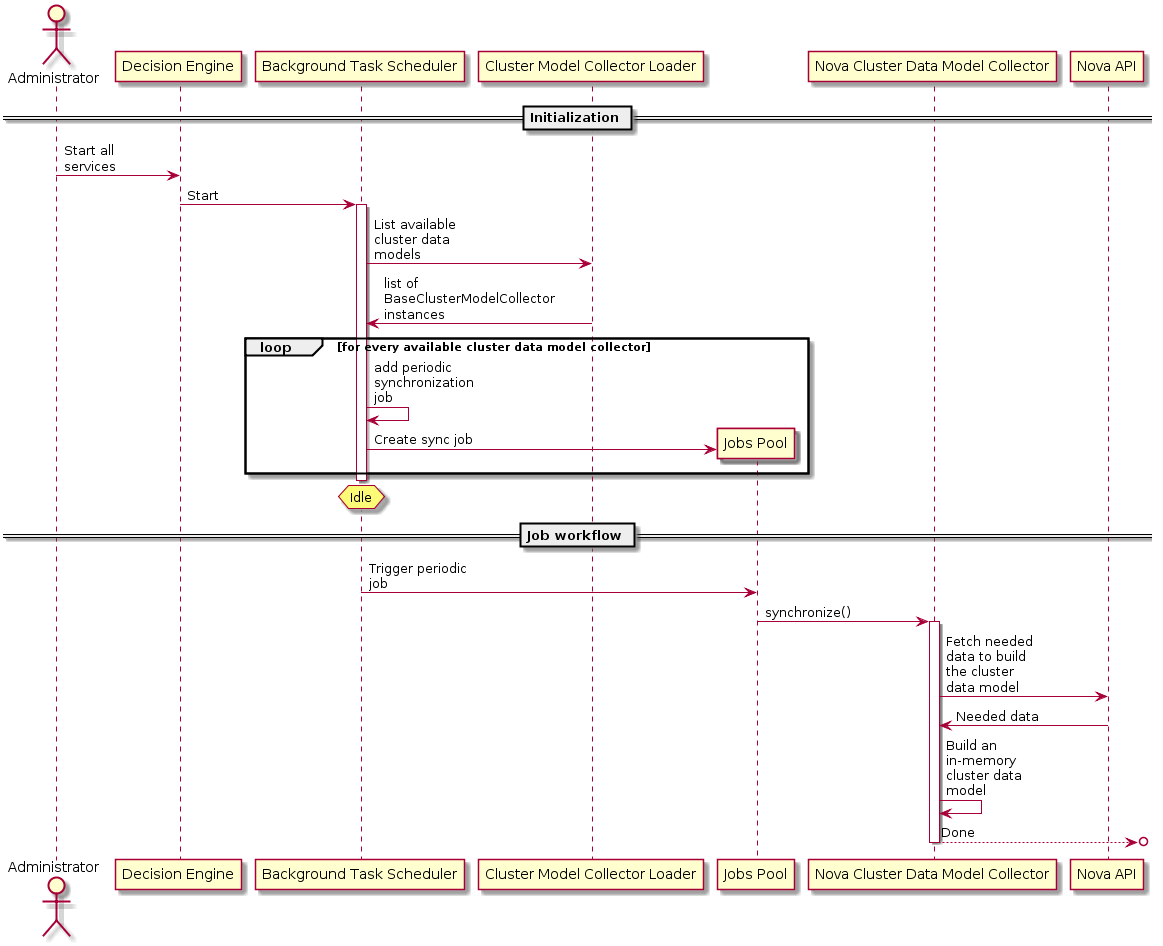
如果定期同步任务是更新缓存的唯一方法,那么缓存显然会很快变得陈旧。 为了解决这个问题,需要放置一个通知处理程序来异步处理来自 AMQP 消息总线上的不同服务的通知。 通知处理程序应该能够配置它感兴趣的通知,以便它可以忽略总线上的任何其他通知。 通知处理程序将确定它正在处理的通知类型,然后基于该类型,它将生成一个线程来调用特定模型收集器中的方法,这些收集器配置为对该类型的通知感兴趣。 通知(包括有效负载)将传递给该方法,该方法将负责适当地更新其收集器的缓存。 通知处理程序能够通过线程异步处理通知非常重要,这样它就不会在通知速率很高时陷入困境。 例如,在 Nova 的情况下,通知处理程序能够接收到如下通知
“compute.instance.create.end” 表示正在创建的实例
“compute.instance.delete.end” 表示正在删除的实例
“compute.instance.live_migration._post.end” 表示正在迁移的实例
…以及数十个更多
以下是描述在接收到通知后更新集群数据模型工作流程的序列图
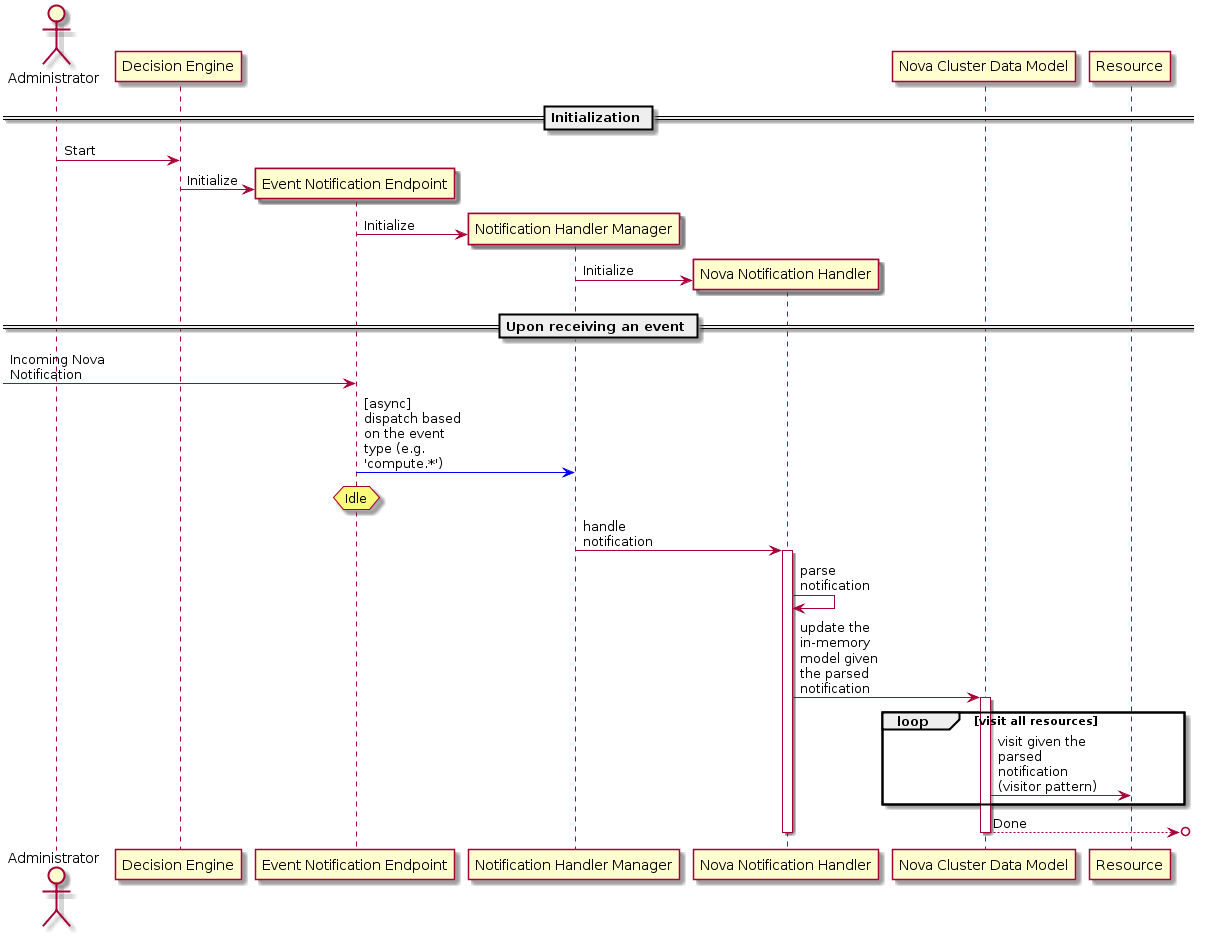
请注意,单个通知不会提示刷新整个集群模型 - 只有缓存中的相关项目将被刷新。
通知处理程序最好有一种方法让 Watcher 的使用者能够通过某种插件机制来处理其他通知。
这个想法是通知处理程序将允许收集器保持其缓存主要保持最新。 如果通知处理程序未能接收到服务通过 AMQP 消息总线发送的任何通知,那么定期同步任务将用于纠正缓存的任何陈旧性。 这归结为以下想法:Watcher 可以接受最终一致性。
备选方案¶
不进行任何缓存,就像今天一样。 如上所述详细讨论的那样,这仅对最小的云环境而言是可以接受的。
与其使用内存缓存,可以将缓存数据存储在 Watcher 数据库表中。 这最终意味着复制大量的潜在数据,这是一个非常大的缺点。
数据模型影响¶
这不应该影响数据库,因为数据保存在内存缓存中。
REST API 影响¶
没有,除非我们打算公开 Watcher 当前的集群表示,但这可能超出本文档的范围。
安全影响¶
无
通知影响¶
Watcher 不会生成任何新的通知,但它会消耗更多的通知。
其他最终用户影响¶
除了更好的性能和对最终一致性的理解之外,没有其他影响。
性能影响¶
这在“提议的更改”部分中描述,但作为概述
由于无需在每次审计请求中重新构建集群模型,因此在可扩展的环境中提高了性能。
定期任务以同步集群模型数据可能非常慢。 因此,它们应该以异步方式执行,最好是这样。
通知处理程序需要处理来自 AMQP 消息总线的大量通知。 生成线程到集群模型收集器以执行实际的缓存更新应该允许控制快速返回到处理程序以处理下一个通知。
其他部署者影响¶
需要添加一组关于定期同步任务速率的基本配置选项。 意图是默认值应该在实际部署中工作良好。
此更改将在合并后立即生效 - 它将成为 Watcher 核心架构的一部分。
开发人员影响¶
策略可能需要进行一些重构才能处理新的集群数据模型。
实现¶
负责人¶
- 主要负责人
Vincent Françoise <Vincent.FRANCOISE@b-com.com>
- 其他贡献者
Taylor Peoples <tpeoples@us.ibm.com>
工作项¶
第一部分¶
增强
BaseClusterModelCollector以允许创建插件使
BaseClusterModelCollector继承自Loadable抽象类。
实现一个
ClusterModelCollectorLoader,它扩展了DefaultLoader类,以便我们可以动态加载用户定义的集群数据模型收集器。使
CollectorManager能够加载入口点/插件,这些插件将是各种集群模型收集器(例如,目前仅为NovaClusterModelCollector,但以后也可能是CinderClusterModelCollector)。添加一个
loader属性,它将是一个ClusterModelCollectorLoader实例。调整所有现有策略以现在明确使用 Nova 集群模型收集器。
添加一个
get_collectors()方法,该方法返回所有入口点名称及其关联的BaseClusterModelCollector实例的映射。
第二部分¶
增强
BaseClusterModelCollector以允许内存模型同步使其继承自
oslo_service.service.Singleton,以便我们只维护每种类型的一个模型。添加一个
cluster_data_model抽象属性,该属性必须返回一个ModelRoot实例,该实例必须是线程安全的。修改抽象方法
get_latest_cluster_data_model(),使其现在成为一个纯方法,该方法必须返回其内存cluster_data_model的深拷贝。添加一个抽象方法
synchronize(),该方法负责获取给定集群数据模型的完整表示。 这个新的集群数据模型应该是一个直接的替换。 注意:此synchronize()方法应该以异步方式执行。为
NovaClusterModelCollector实现cluster_data_model属性。为
NovaClusterModelCollector实现synchronize()方法。
使用 apscheduler 实现一个
BackgroundTaskScheduler后台调度服务,该服务将负责定期触发每个集群数据模型的作业以同步它们。 此调度服务应作为Watcher 决策引擎守护程序的一部分启动。它应该同时继承自
oslo_service.service.ServiceBase和apscheduler.schedulers.background.BackgroundScheduler。使用
oslo_service.service.Services以在同一进程中运行BackgroundTaskScheduler和主决策引擎服务。该周期必须可以通过配置文件进行配置。
还应公开关于此调度服务的一组基本配置选项。
更新
Watcher 决策引擎命令以现在启动
第三部分¶
创建一个
NotificationHandlerManager类,该类将负责使用观察者模式调度任何传入的通知以更新模型。定义一个
register()方法,该方法将用于注册所有通知处理程序。实现一个
dispatch()方法,该方法将负责使用基于其关联发布者 ID 的内部注册表调用正确的通知处理程序。 此方法应以异步方式执行通知处理程序。
创建一个
NotificationHandler抽象类,该类将负责处理任何给定的通知以更新模型。实现一个
handle()方法,该方法将负责根据通知的内容调用注册的处理程序方法定义一个
get_publisher_id()类方法,该方法将用于将NotificationHandler与给定的发布者(例如“^compute.*”)关联起来。实现一个抽象类
NotificationParser,它将负责解析传入的原始通知。创建一个抽象方法
parse(),它将负责将传入的原始通知转换为一些 Watcher 通知对象,这些对象对于所有事件类型都应不同。
使用访问者模式,探索内存模型并在需要时应用相关的更改
实现一个类
NovaNotificationHandler,它继承自基础类NotificationHandler
增强
BaseClusterModelCollector,以允许收集和处理通知,以便随着时间的推移维护内存模型的一致性向
BaseClusterModelCollector添加一个抽象属性notification_handler,该属性必须被重写以返回一个NotificationHandler实例。使
NovaClusterModelCollector的notification_handler属性返回一个NovaNotificationHandler实例。
使
CollectorManager能够找到所有通知处理程序向
CollectorManager添加一个类方法get_notification_handlers(),以便它返回所有NotificationHandler实例的列表
实现一个类
EventsNotificationEndpoint,它将负责订阅给定的通知主题,以便收集和格式化它们使
CollectorManager能够通过get_collectors()及其关联的notification_handler找到所有通知处理程序。
依赖项¶
无
测试¶
现有的 tempest 测试应该提供基本的覆盖范围。大部分更改会影响更大的环境。如果无法为测试获得这些环境,则需要进行某种形式的模拟和性能分析。
文档影响¶
需要为新的配置选项提供文档。所有这些数据都由 Watcher 缓存在内存中的概念也需要记录在案。
参考资料¶
无
历史¶
无
