增强 CLI 以处理大型查询结果¶
https://blueprints.launchpad.net/tacker/+spec/paging-query-result
本提案旨在增强 CLI 以处理大型查询结果。
问题描述¶
Tacker 已经支持根据 ETSI NFV SOL013 [2] 处理大型查询结果 [1]。通过此支持,当查询记录数超过某个值时,记录列表将默认分页。因此,如果存在下一页,Tacker 的客户端需要逐页查询。此外,Tacker 能够通过将查询参数“all_records=yes”添加到要查询的 API 的 URL 中,一次性获取所有记录。Yoga 版本中现有的客户端命令以及 Tacker 中对应的目标 API 如下。
openstack vnflcm list
openstack vnflcm op list
openstack vnf package list
由于客户端没有获取下一页的方法,目前这些命令无法处理分页。从用户角度来看,存在用户需要通过单个操作获取所有记录的情况。但是,一次性处理大型查询结果会影响服务器的性能。因此,需要在客户端设计分页功能,同时缓解对服务器性能的影响。
提议的变更¶
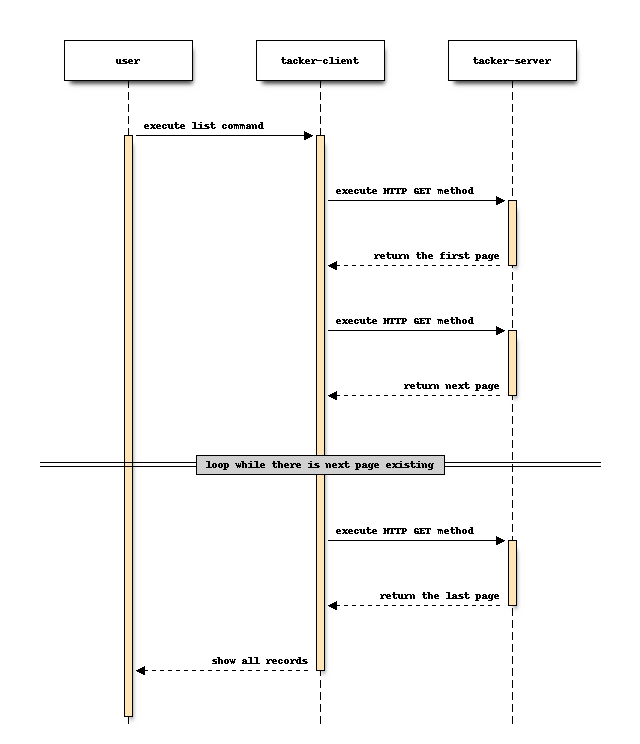
为了解决上述问题,我们引入以下流程作为默认的目标 CLI 功能,以处理大型查询结果。
当用户执行 CLI 请求时,Tacker 服务器对记录进行分页,并将第一页记录响应给客户端。
当客户端接收到响应并识别到其中包含下一页的链接时,它会在内部保留响应中的记录,并查询服务器的下一页。
直到服务器中不存在下一页,客户端才会逐页查询并保留记录。
在从服务器接收到所有分页记录后,客户端会将保留的记录组装起来,然后将其显示为 CLI 响应。
数据模型影响¶
无
REST API 影响¶
无
安全影响¶
无
通知影响¶
无
其他最终用户影响¶
无
性能影响¶
无
IPv6 影响¶
无
其他部署者影响¶
无
开发人员影响¶
无
社区影响¶
无
备选方案¶
无
实现¶
负责人¶
- 主要负责人
Koichi Edagawa <edagawa.kc@nec.com>
工作项¶
客户端需要执行以下项目:
添加检查,以查看来自 Tacker 服务器的响应头中是否存在下一页记录的链接。
添加一个过程,以保留来自 Tacker 服务器的记录并查询下一页。
添加一个过程,以组装所有保留的记录并将其显示为单个 CLI 响应。
依赖项¶
无
测试¶
将添加此增强功能的单元测试。
文档影响¶
无
