性能改进的代码重构¶
https://blueprints.launchpad.net/tacker/+spec/system-performance-management
问题描述¶
商业系统,作为 Tacker 的主要目标之一,需要高性能软件。然而,使用同时进行的生命周期管理 (LCM) 操作进行评估表明,Tacker 的性能存在一些问题。因此,将 Tacker 进一步引入商业管理和编排 (MANO) 系统需要性能改进,例如更高的并发性、更高的吞吐量和更短的周转时间。
本规范提出以下代码重构。
减少获取 OpenStack 资源的事务 (针对 Tacker v2 API)
支持订阅过滤器 (vnfdId) (针对 Tacker v1 API)
重构 Tacker 输出日志 (针对 Tacker v1/v2 API)
提议的变更¶
1. 减少获取 OpenStack 资源的事务 (针对 Tacker v2 API)¶
在执行 VNF LCM 操作,例如 实例化、终止、伸缩 和 修复 时,当前实现使用 “查找堆栈” API [1] 来检查堆栈资源的状态。
由于 “查找堆栈” API 需要重定向,它可能会给 HEAT 带来沉重的负载。
本规范建议使用 “显示堆栈详情” API 代替 “查找堆栈” API。由于 “显示堆栈详情” API 不需要重定向,因此它可以减少 Tacker 和 HEAT 之间的事务数量,从两次减少到一次。
查找堆栈 (带重定向)
[GET] /v1/{tenant_id}/stacks/{stack_identity}注意
“stack_identity” 是堆栈的 UUID 或名称。由于 http 相关的库 (Python 库) 会自动发送包含
“stack_id”参数的重定向请求,因此 Tacker-conductor 在发送重定向时无法识别“stack_id”。显示堆栈详情 (不带重定向)
[GET] /v1/{tenant_id}/stacks/{stack_name}/{stack_id}
在当前实现中,“stack_id” 未存储在 Tacker 数据库中,因为 ETSI NFV 标准 [2]、[3] 中没有相应的数据模型。
为了直接使用 “显示堆栈详情”,Tacker 需要处理 “stack_id”。
以下显示处理 “stack_id” 的两种选项。
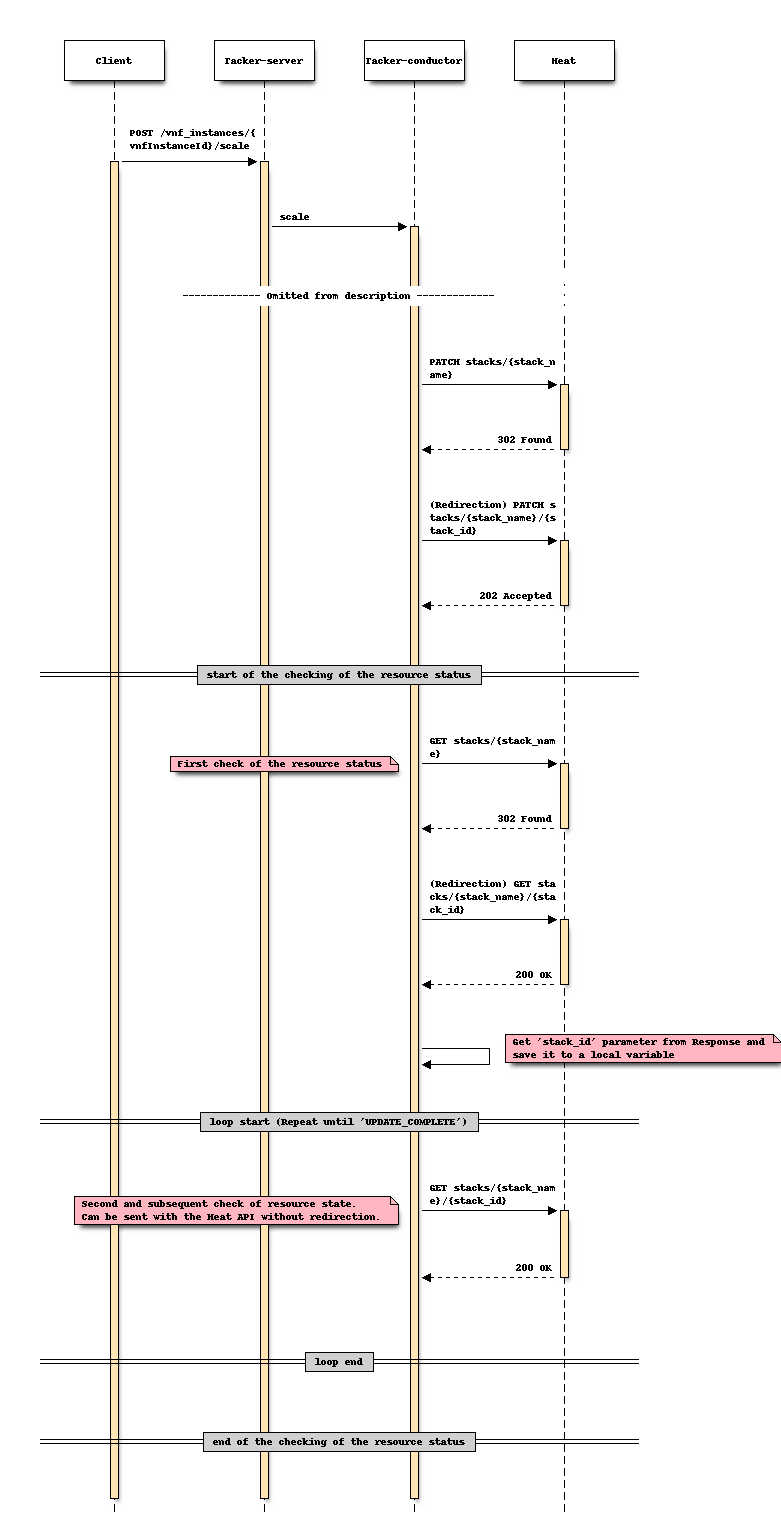
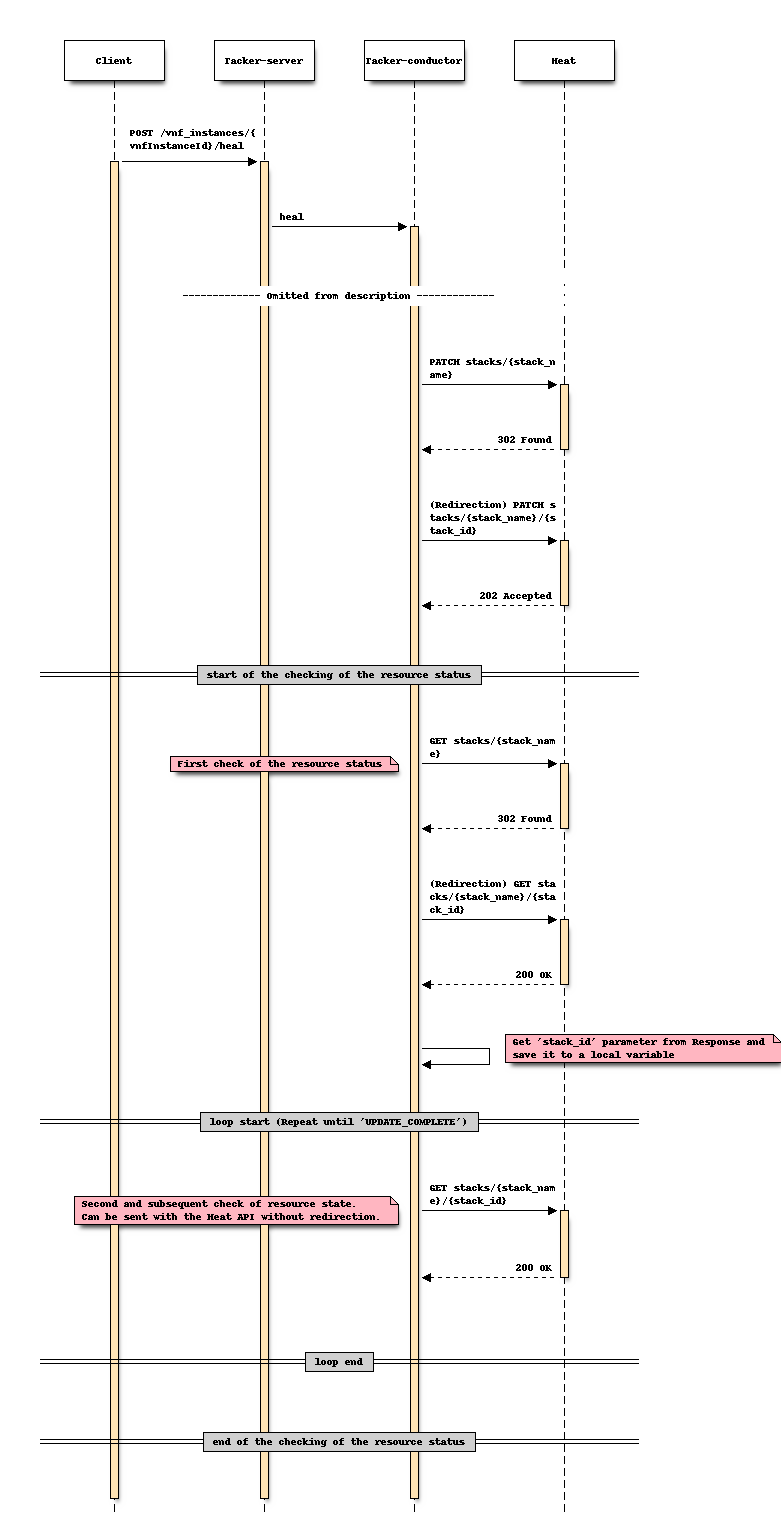
选项 1:使用在每次 LCM 执行中获得的 “stack_id”¶
此选项是通过传递在每个 LCM 操作过程中获得的 “stack_id” 来直接调用 “显示堆栈详情”。
“stack_id” 可以在以下步骤中获得。
实例化在使用 “创建堆栈” API 时。
终止/伸缩/修复在第一次使用 “查找堆栈” API 时。
对于实例化
更改前序列 (实例化)
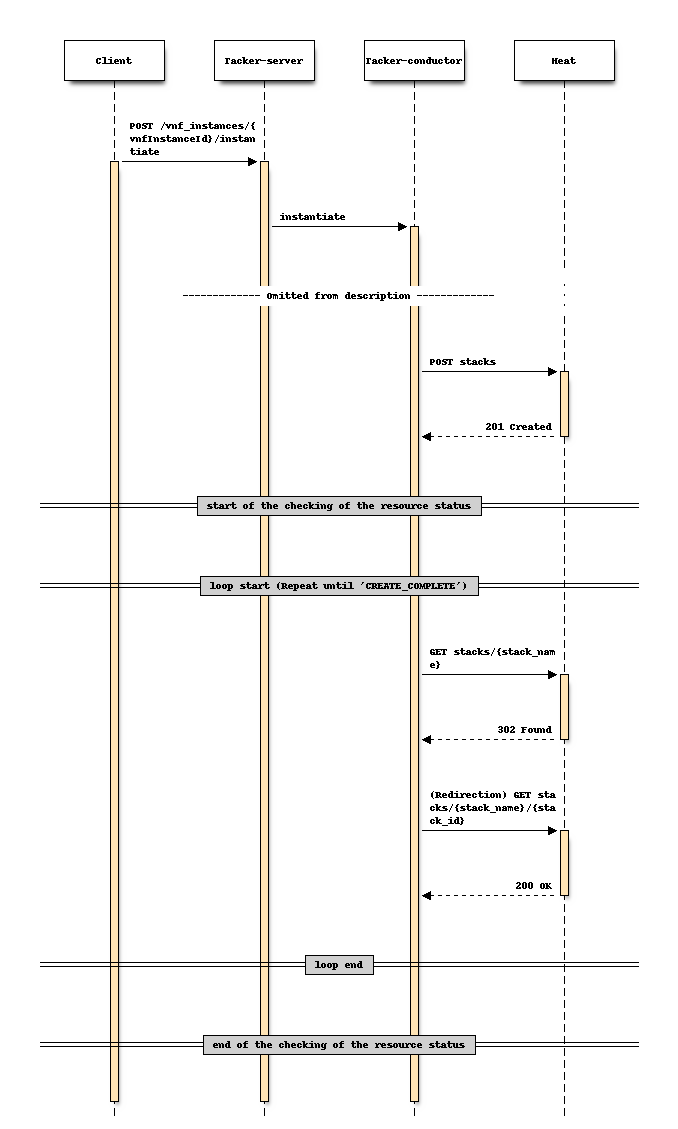
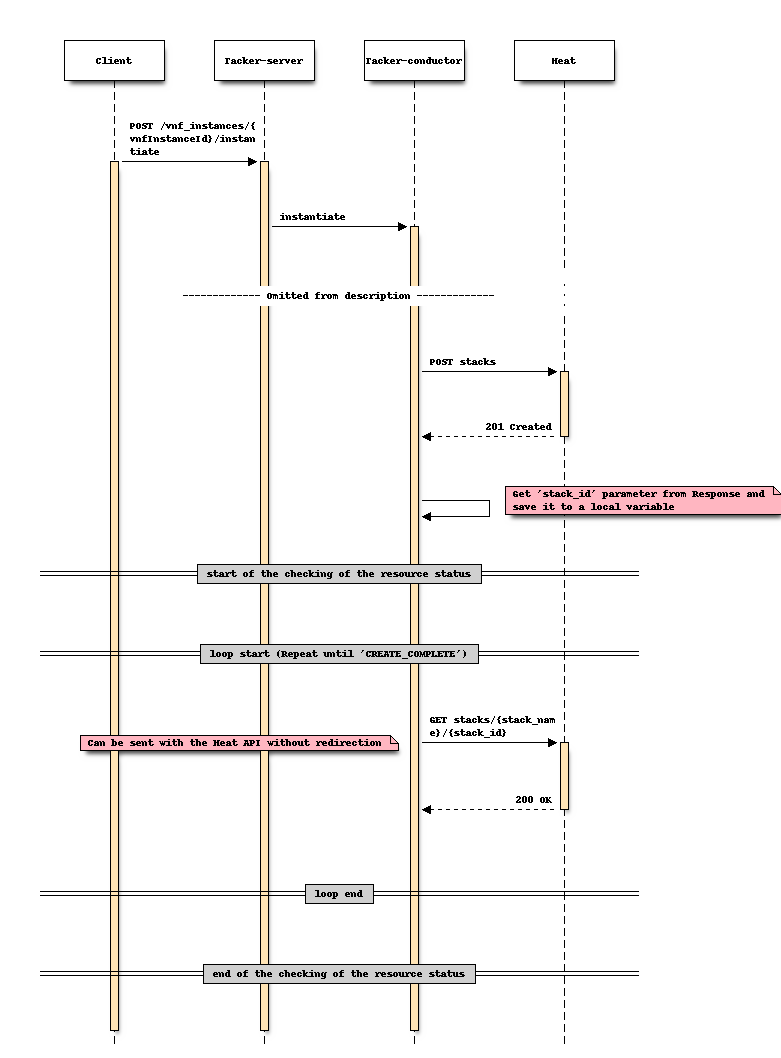
更改后序列 (实例化)
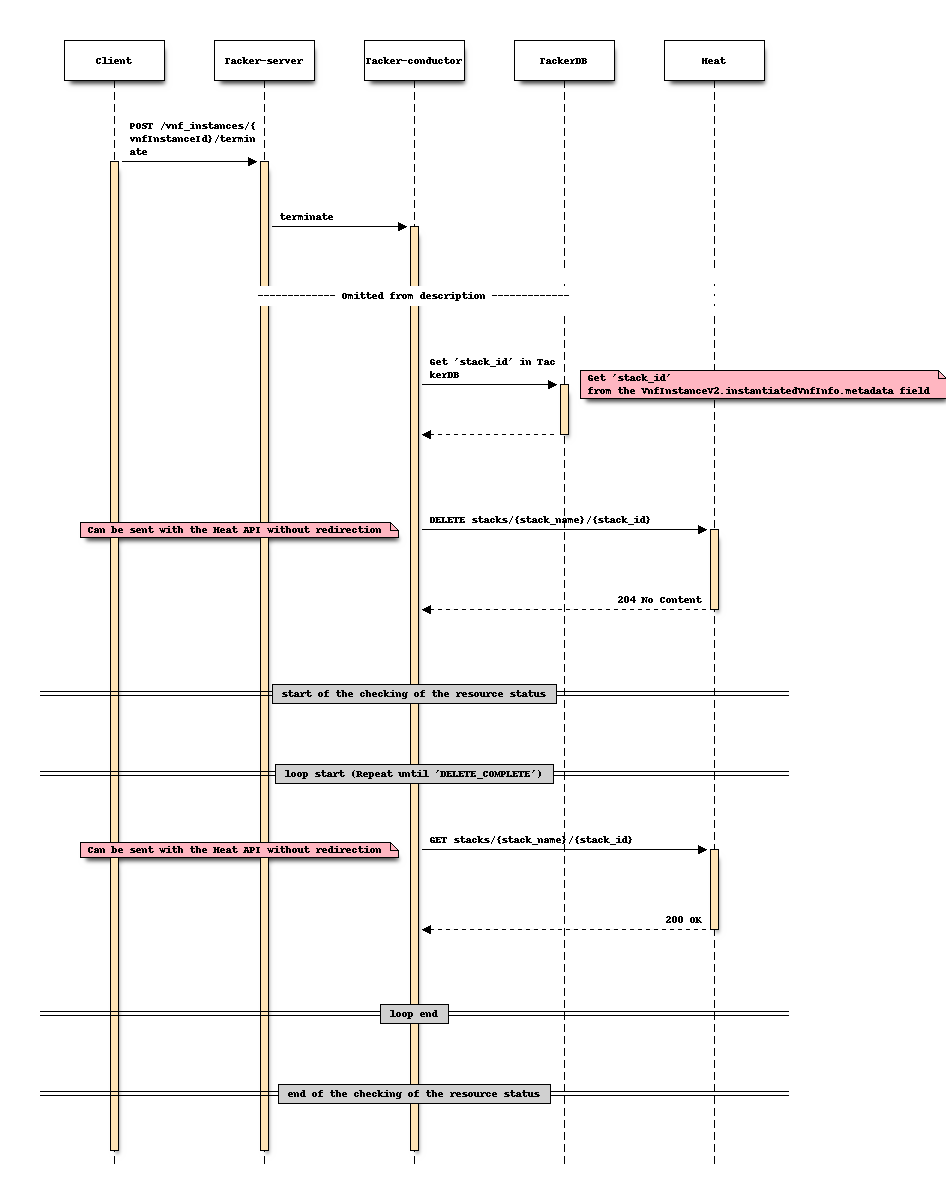
对于终止
更改前序列 (终止)
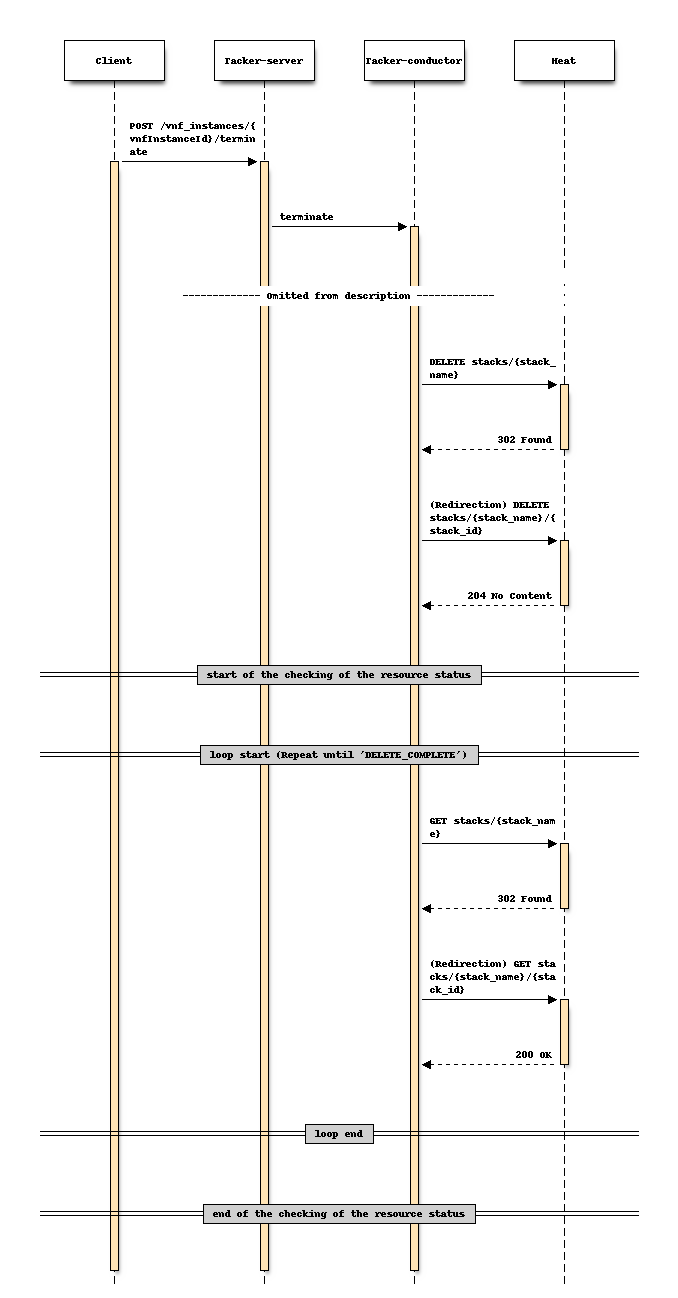
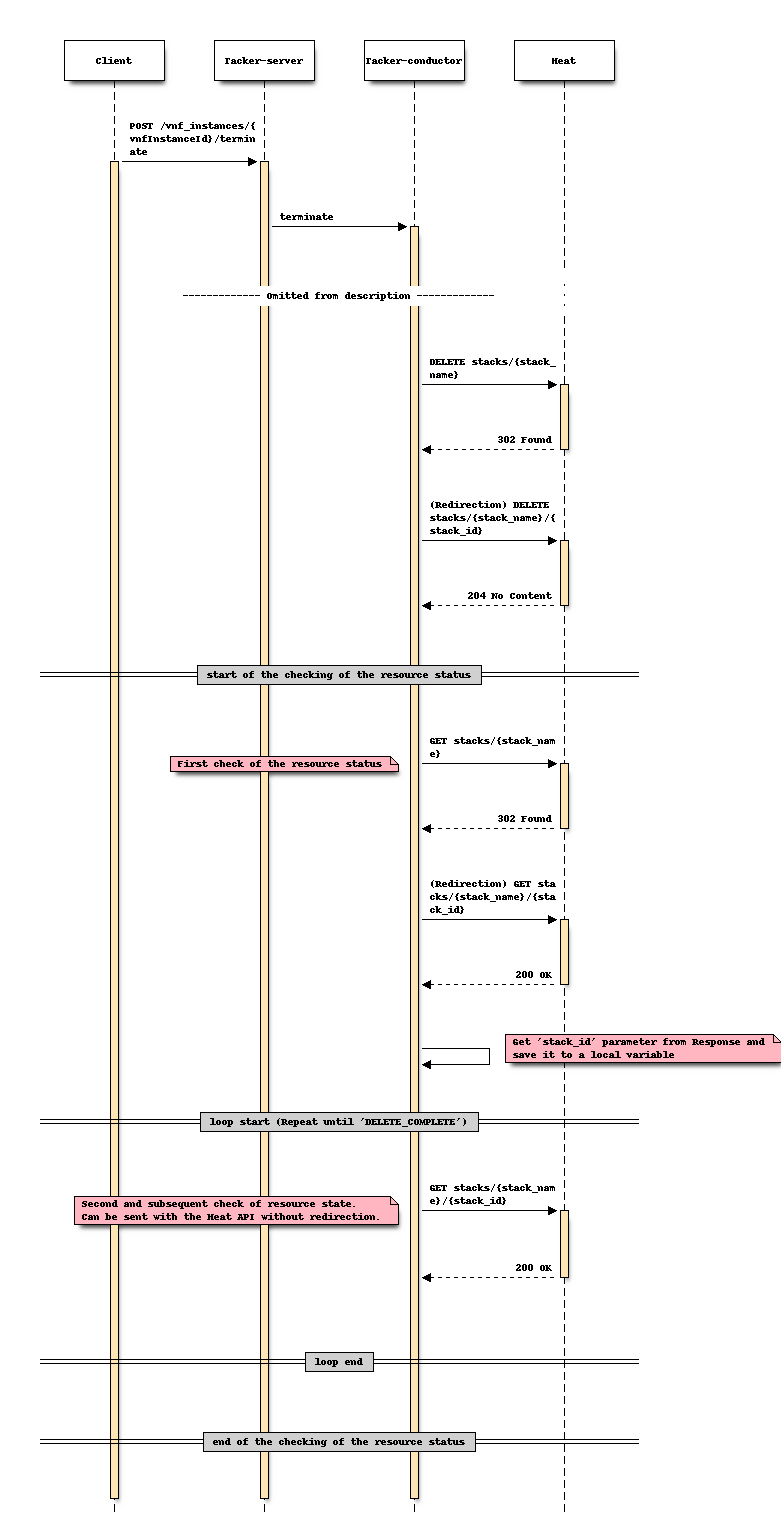
更改后序列 (终止)
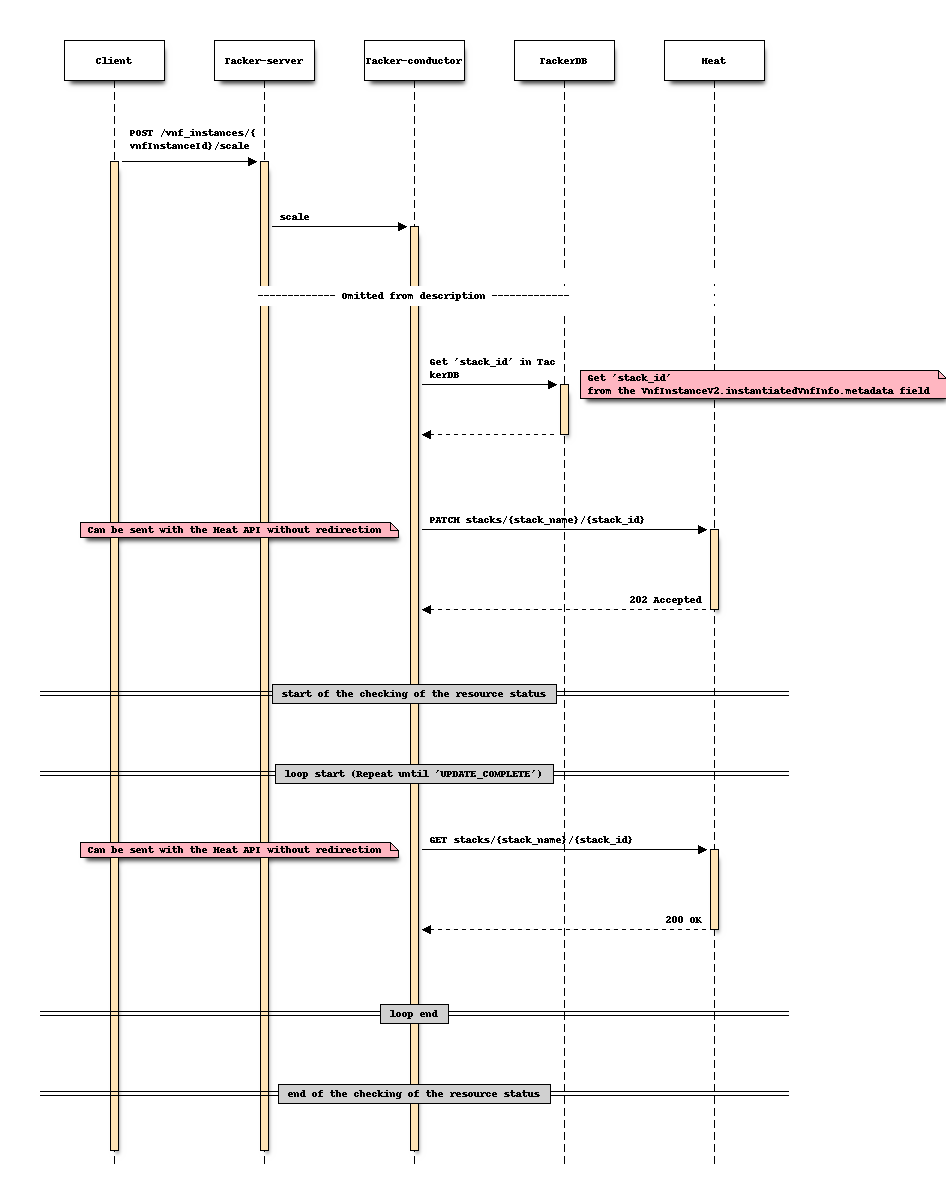
对于伸缩
更改前序列 (伸缩)
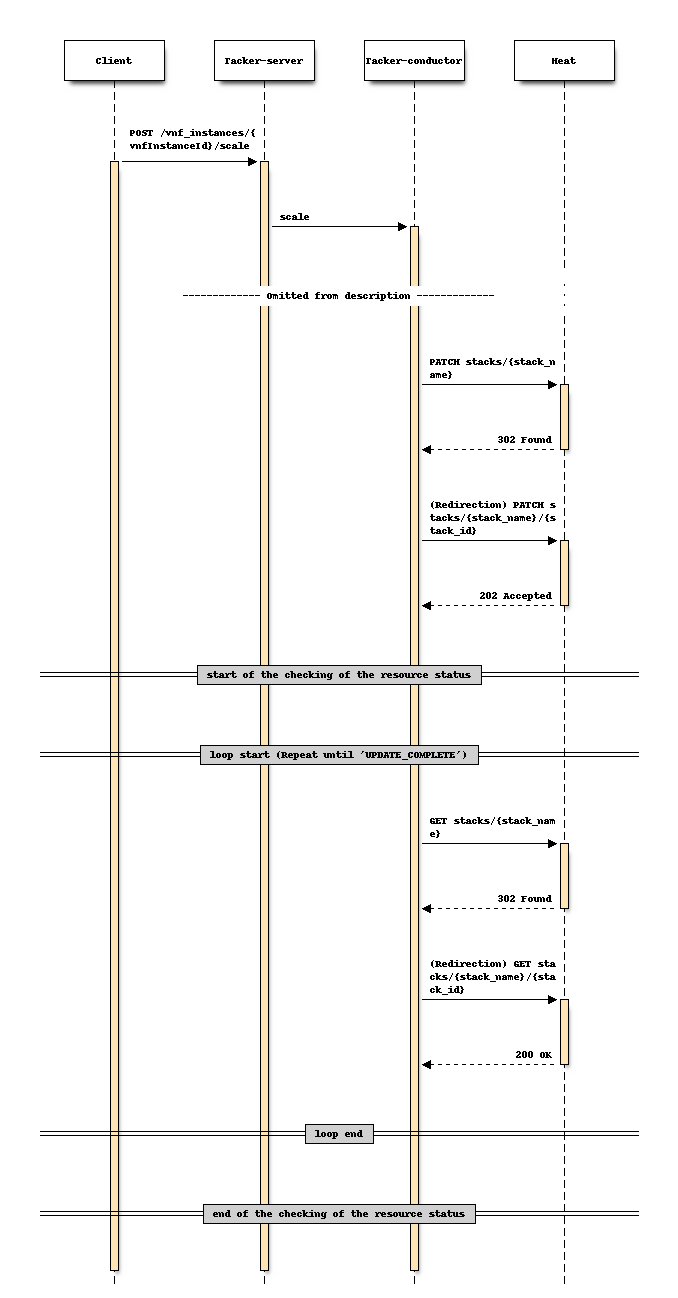
更改后序列 (伸缩)
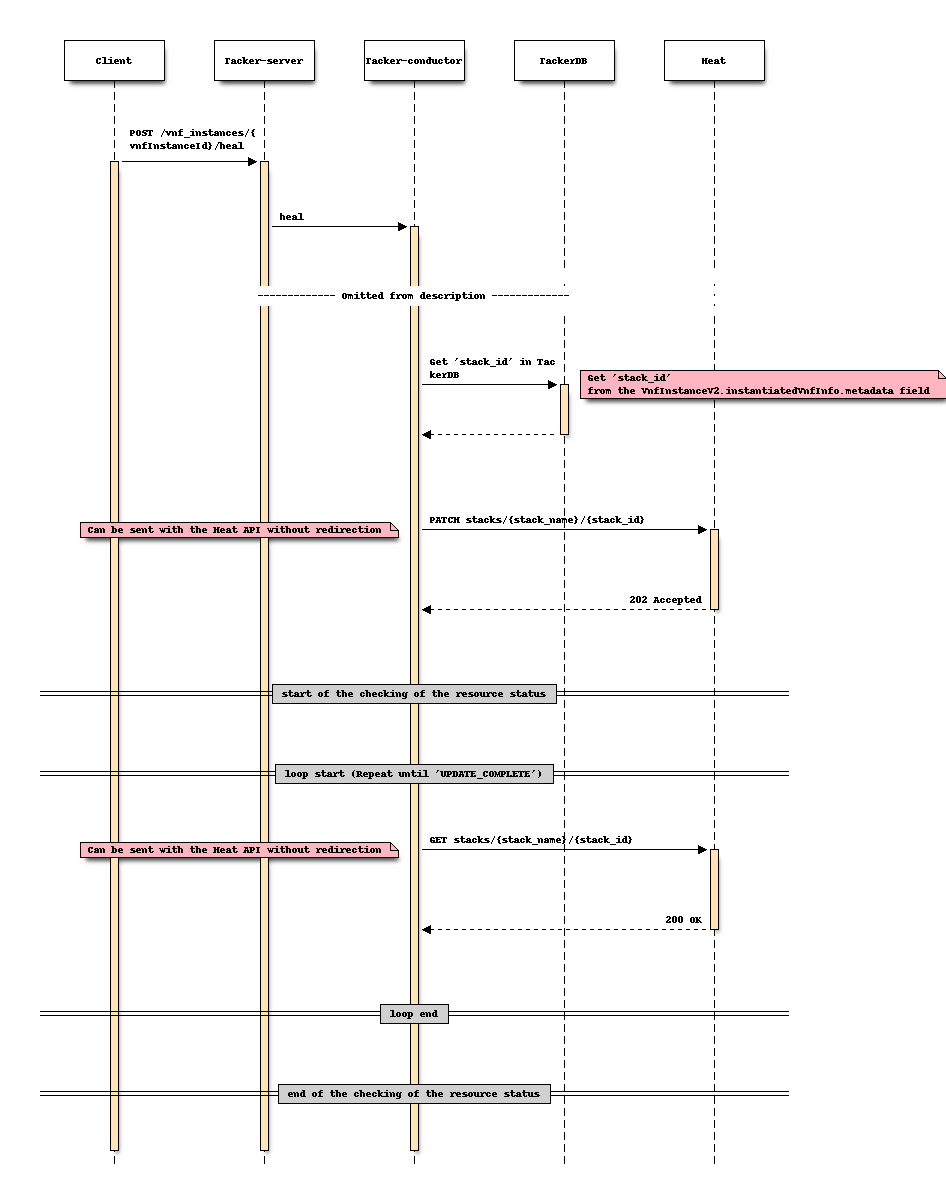
对于修复
更改前序列 (修复)
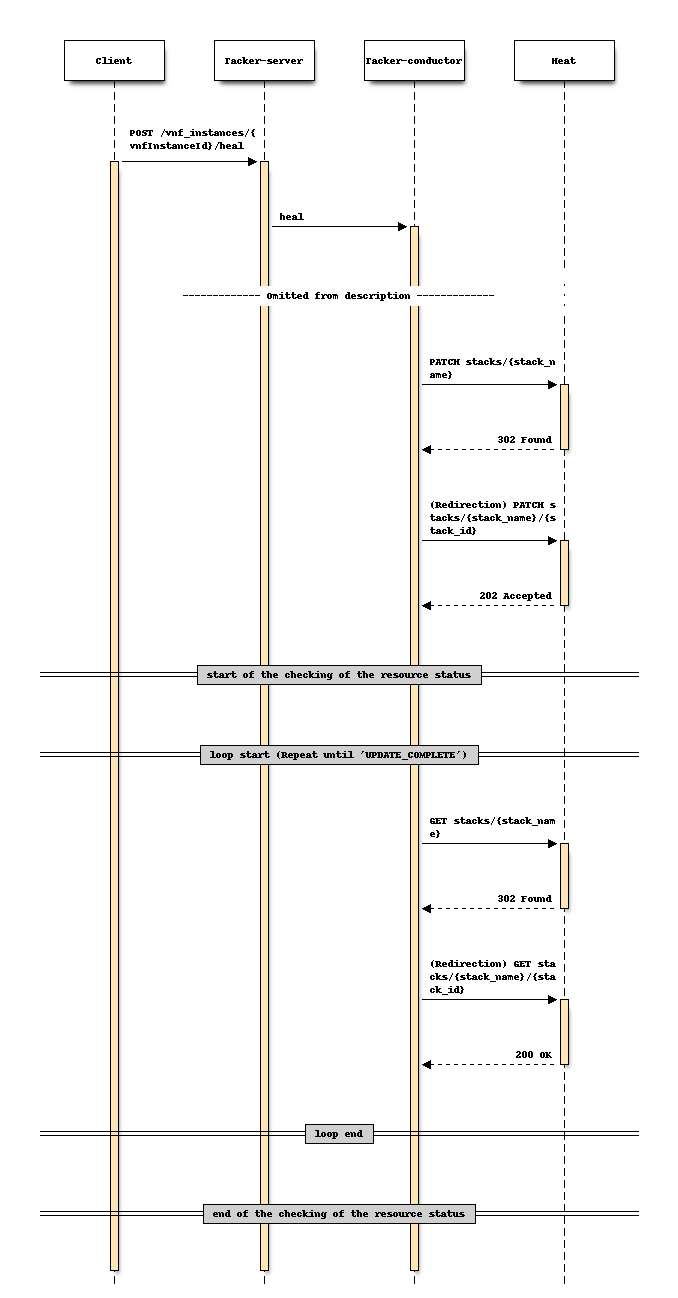
更改后序列 (修复)
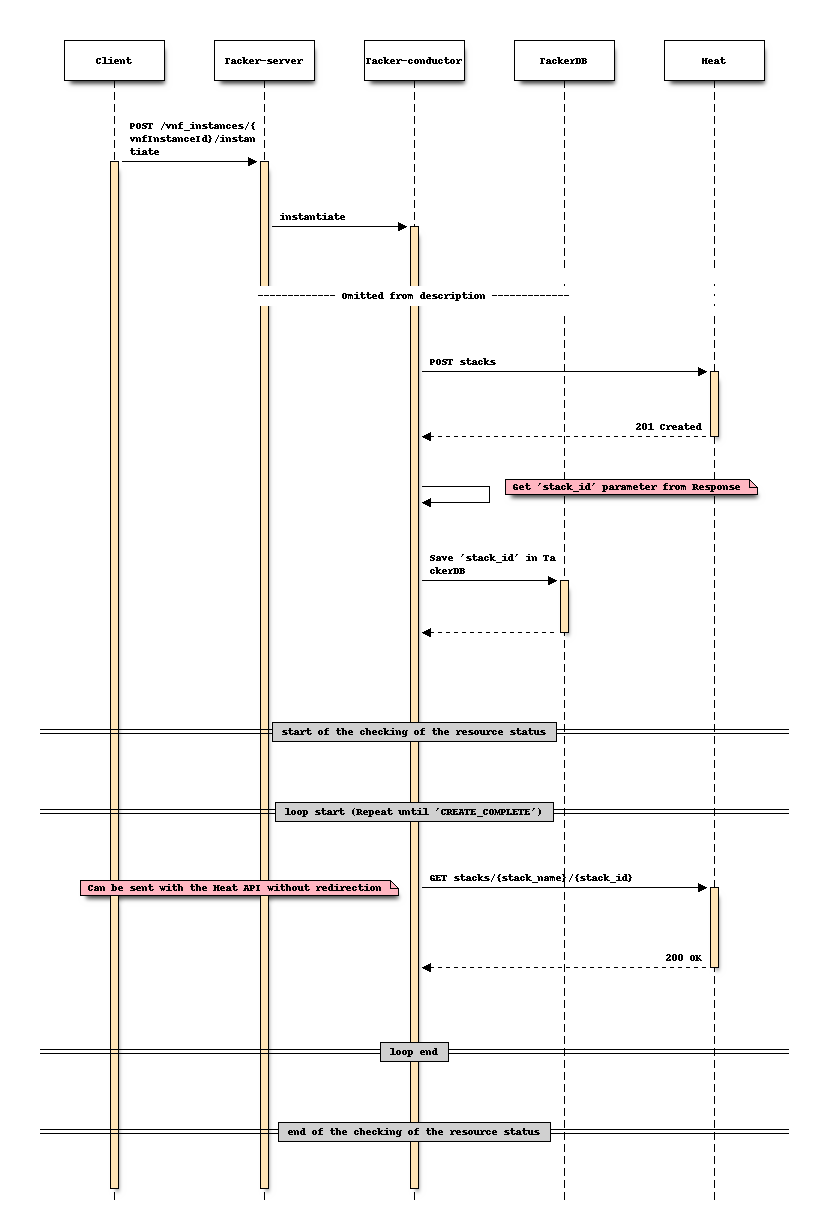
选项 2:在实例化过程中获得的 “stack_id” 存储在 Tacker 数据库中¶
此选项是通过在执行 创建堆栈 时,使用在实例化过程中获得的并存储在 Tacker 数据库中的 “stack_id” 来直接调用 “显示堆栈详情”。将 “stack_id” 存储在 VnfInstanceV2.instantiatedVnfInfo.metadata 字段中是合适的。
更改前序列 (实例化、终止、伸缩、修复)
与
选项 1中的更改前序列相同。更改后序列 (实例化)
更改后序列 (终止)
更改后序列 (伸缩)
更改后序列 (修复)
- 在其他 LCM 操作期间也可以进行类似的性能改进。例如,在实例化的 “回滚” 过程中,可以使用上述 “stack_id” 来使用 “删除堆栈” 以提高性能。
注意
对于选项 1 和 2,如果 “stack_id” 意外丢失,将使用重定向 API 再次检索信息。
注意
选项 1 和 2 的优缺点如下所示。
选项 1
优点:对现有的 Tacker 数据库没有影响。
缺点:HEAT 请求的频率高于选项 2。
选项 2
优点:HEAT 请求的数量少于选项 1。
缺点:Tacker 数据库必须存储 NFV 标准中未定义的数据。
2. 支持订阅过滤器 (vnfdId) (针对 Tacker v1 API)¶
Tacker v1 API 尚未支持 vnfdId 的订阅过滤器。这会导致 Tacker 数据库中注册的所有订阅发送通知,从而导致日志大小增大和通信延迟。
为了解决这些问题,本规范建议支持 vnfdId 的订阅过滤器。
vnfdId 订阅过滤器的设计¶
此提案使 Tacker v1 API 能够发送与特定 vnfdId 相关的通知。
以下显示了通过 vnfdId 订阅过滤器进行通知通信处理的流程。
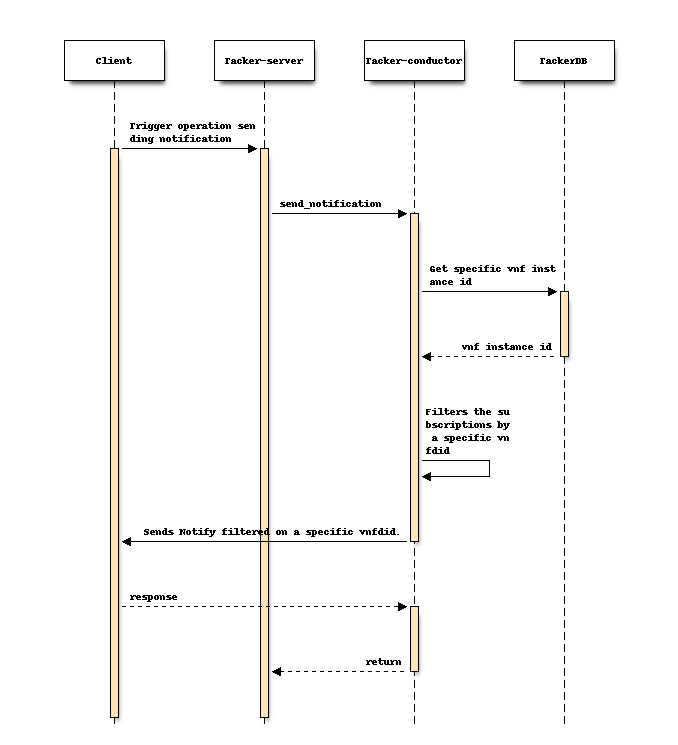
3. 重构 Tacker 输出日志 (针对 Tacker v1/v2 API)¶
本规范建议重构当前的 Tacker 输出日志,以解决以下问题。
双重循环中的信息级别日志¶
当前实现的双重循环中存在信息级别日志,导致输出日志过大并影响性能。
以下显示了具体示例。
def send_notification(self, context, notification):
:
for line in vnf_lcm_subscriptions:
notification['subscriptionId'] = line.id
if (notification.get('notificationType') ==
'VnfLcmOperationOccurrenceNotification'):
notification['_links']['subscription'] = {}
notification['_links']['subscription']['href'] = \
CONF.vnf_lcm.endpoint_url + \
"/vnflcm/v1/subscriptions/" + line.id
else:
notification['links']['subscription'] = {}
notification['links']['subscription']['href'] = \
CONF.vnf_lcm.endpoint_url + \
"/vnflcm/v1/subscriptions/" + line.id
notification['timeStamp'] = datetime.datetime.utcnow(
).isoformat()
try:
self.__set_auth_subscription(line)
for num in range(CONF.vnf_lcm.retry_num):
try:
LOG.info("send notify[%s]" %
json.dumps(notification))
auth_client = auth.auth_manager.get_auth_client(
notification['subscriptionId'])]
不适当的日志级别设置¶
Tacker 的一些实现会在调试和信息级别显示错误原因,这使得分析原因变得困难。需要调整 Tacker 的输出日志级别来解决此问题。
以下显示了具体示例。
日志显示了错误原因,但由于日志指定为信息级别,因此很难对其进行分析。此日志应指定为错误级别。
def _get_vnfd_id(context, id): try: vnf_package_vnfd = \ api.model_query(context, models.VnfPackageVnfd).\ filter_by(package_uuid=id).first() except Exception: LOG.info("select vnf_package_vnfd failed") if vnf_package_vnfd: return vnf_package_vnfd.vnfd_id else: return None
日志对于分析是必要的,但不需要日志字典。因此,此日志应指定为调试级别。
def create_vdu_image_dict(grant_info): """Create a dict containing information about VDU's image. :param grant_info: dict(Grant information format) :return: dict(VDU name, Glance-image uuid) """ vdu_image_dict = {} for vdu_name, resources in grant_info.items(): for vnf_resource in resources: vdu_image_dict[vdu_name] = vnf_resource.resource_identifier LOG.info('vdu_image_dict: %s', vdu_image_dict) return vdu_image_dict
日志级别的指标¶
以下显示了输出的日志级别的指标。
日志级别 |
描述 |
|---|---|
调试 |
有关系统活动的详细信息。 |
信息 |
通常有用的日志信息 (服务启动/停止、配置假设等)。 |
警告 |
API 的不当使用、接近错误等。任何在运行时不一定是异常但不是正常的意外问题。 |
error |
意外的运行时错误或错误原因。 |
严重 |
致命错误信息。如果发生这种情况,应解决的信息。 |
注意
适当的日志级别因情况而异。开发人员需要参考本规范中的两个示例、类似软件等,为情况指定适当的日志级别。
数据模型影响¶
修改 Tacker 数据库中的以下表。详细的相应模式如下
“减少获取 OpenStack 资源”的选项 2
VnfInstanceV2:以 json 格式将 “stack_id” 添加到 instantiatedVnfInfo.metadata 中。以下是示例数据格式。
"instantiatedVnfInfo" : { "metadata": { "stack_id": "cb9d8959-ab17-4270-a4c9-257d267ca9f1" } }
REST API 影响¶
无
安全影响¶
无
通知影响¶
无
其他最终用户影响¶
无
性能影响¶
减少获取 OpenStack 资源的事务 (针对 Tacker v2 API)
它减少了 HEAT 请求的数量,从而提高了并发 LCM 运行时性能。
支持订阅过滤器 (vnfdId) (针对 Tacker v1 API)
它减少了发送到用户指定通知的数量,从而提高了性能。
重构 Tacker 输出日志的日志级别 (针对 Tacker v1/v2 API)
删除双重循环中的信息级别日志将防止日志膨胀并抑制重负载下的性能下降。
其他开发人员影响¶
无
开发人员影响¶
开发人员将能够使用适当的日志级别来防止日志膨胀并分析错误原因。
实现¶
负责人¶
- 主要负责人
Hirofumi Noguchi<hirofumi.noguchi.rs@hco.ntt.co.jp>
- 其他贡献者
Ayumu Ueha<ueha.ayumu@fujitsu.com>
Yoshiyuki Katada<katada.yoshiyuk@fujitsu.com>
Yusuke Niimi<niimi.yusuke@fujitsu.com>
工作项¶
“Tacker-conductor” 将被修改以实现以下功能。
减少获取 OpenStack 资源的事务 (针对 Tacker v2 API)
处理 “stack_id”。
更改 HEAT API 的使用方式。
“Tacker-server” 将被修改以实现以下功能。
在 Tacker v1 API 中添加订阅过滤器 (vnfdId)
修复 Tacker 实现的日志输出到适当的日志级别。
添加新的单元和功能测试。
依赖项¶
实例化/终止/伸缩/修复操作
依赖于 HEAT API “查找堆栈” [1]。
测试¶
将添加单元和功能测试,以涵盖规范中所需的情况。
文档影响¶
无
