支持使用外部监控工具进行自动修复和自动伸缩的 VNFM¶
https://blueprints.launchpad.net/tacker/+spec/support-auto-lcm
问题描述¶
Zed 版本支持故障管理/性能管理 (FM/PM) 接口,以及使用外部监控工具进行自动修复和自动伸缩 [1]。但是,修复或伸缩的执行必须由 NFVO 触发。
本规范提供了一些实现,用于支持接收来自外部监控工具的告警,以及 VNFM (tacker) 驱动的自动修复和自动伸缩,无需 NFVO。此实现仅支持通过 Tacker 的 v2 API 实例化的 VNF 和 CNF。
提议的变更¶
需要进行以下更改
添加 AutoHeal RESTful API 以接收来自外部监控工具发送的告警。
POST /alert/auto_healing
修改 AutoScale RESTful API 以接收来自外部监控工具发送的告警。
POST /alert/auto_scaling
在配置文件中添加字段以确定是否应触发自动修复。
注意
外部监控工具是一种监控服务,不包含在 Tacker 中。运营商实施外部监控工具。外部监控工具使用指标服务,例如 Prometheus,并使用 Prometheus 插件接口触发自动修复和自动伸缩事件。
Prometheus 插件¶
Prometheus 插件是针对 Prometheus 特定功能的一种示例实现。在本规范中,Prometheus 插件有两个 API,用于接收 Prometheus 发送的请求,然后调用 Tacker 的修复或伸缩接口。
Prometheus 插件是一项可选功能。AutoHeal 和 AutoScale API 可以在 tacker.conf 中启用。
[prometheus_plugin]
auto_healing = True
auto_scaling = True
触发自动修复¶
当外部监控工具检测到 VNF 或 CNF 资源故障或问题时,它会将告警消息发送到 Tacker。Tacker 接收告警并对其进行验证。然后 Tacker 调用资源的内部修复功能。使用此修复方法来修复 VNF 或 CNF 资源的故障和问题。
修复操作的设计¶
以下是修复的示意图
+--------------------------------------------------------------------------+
| VNFM |
| +------------------------+ +----------------------------+ |
| | Tacker | | Tacker | |
| | Server | | Conductor | |
+----------------+ | | | | | |
| External | 2. POST | | 3. Check parameters and confirm vnfc_info_id | |
| Monitoring | alert | | +------------+ | | | +--------+ |
| Tool +----------------> Prometheus +-------------------------------------------> Tacker | |
| (based on | | | | Plugin | | | | | DB | |
| Prometheus) | | | +------+-----+ | | | +--------+ |
+--+-------------+ | | | 4. Heal | | | |
| 1. Collect metrics | | | | | | |
| | | +------v-----+ | | +---------------+ | |
| | | | Vnflcm +--------------> Vnflcm Driver +--+ | |
| | | | Controller | | | +---------------+ | | |
| | | +------------+ | | +---------v--+ | |
| | | | | | Infra +--------------+ |
| | | | | | Driver | | | |
| | | | | +------------+ | | |
| | +------------------------+ +----------------------------+ | |
| +----------------------------------------------------------------------|---+
| |
| +-----------------------------------------------------------------+ |
| | Kubernetes | |
| | +---------------+-----------------------------------+
| | 5. Delete failed | | 6. Create new Pod | |
| | Pod | | | |
| | +--------v----+ +------v------+ +-------------+ | |
| | | +--------+ | | +--------+ | | | | |
+----------------------------------> | Pod | | | | Pod | | | | | |
| | | +--------+ | | +--------+ | | | | |
| | | Worker | | Worker | | Master | | |
| | +-------------+ +-------------+ +-------------+ | |
| +-----------------------------------------------------------------+ |
| |
| +-----------------------------------------------------------------+ |
| | OpenStack | |
| | +---------------+-----------------------------------+
| | 5. Delete failed | | 6. Create new VM |
| | VM | | |
| | +--------v----+ +------v------+ +-------------+ |
| | | +--------+ | | +--------+ | | | |
+----------------------------------> | VM | | | | VM | | | | |
| | +--------+ | | +--------+ | | | |
| | Compute | | Compute | | Controller | |
| +-------------+ +-------------+ +-------------+ |
+-----------------------------------------------------------------+
外部监控工具收集指标并决定是否需要触发告警。
外部监控工具向
/alert/auto_healing发送 POST 请求。Prometheus 插件接收告警请求并验证其内容。然后,它确认告警请求中的
vnfc_info_id是否存在于数据库中。触发修复操作。
指定的 VM 或 Pod 被删除。
创建新的 VM 或 Pod。
操作请求参数¶
API 详细信息在 REST API 影响 中描述。
操作顺序¶
以下描述了外部监控工具发送告警后 Tacker 的处理流程。
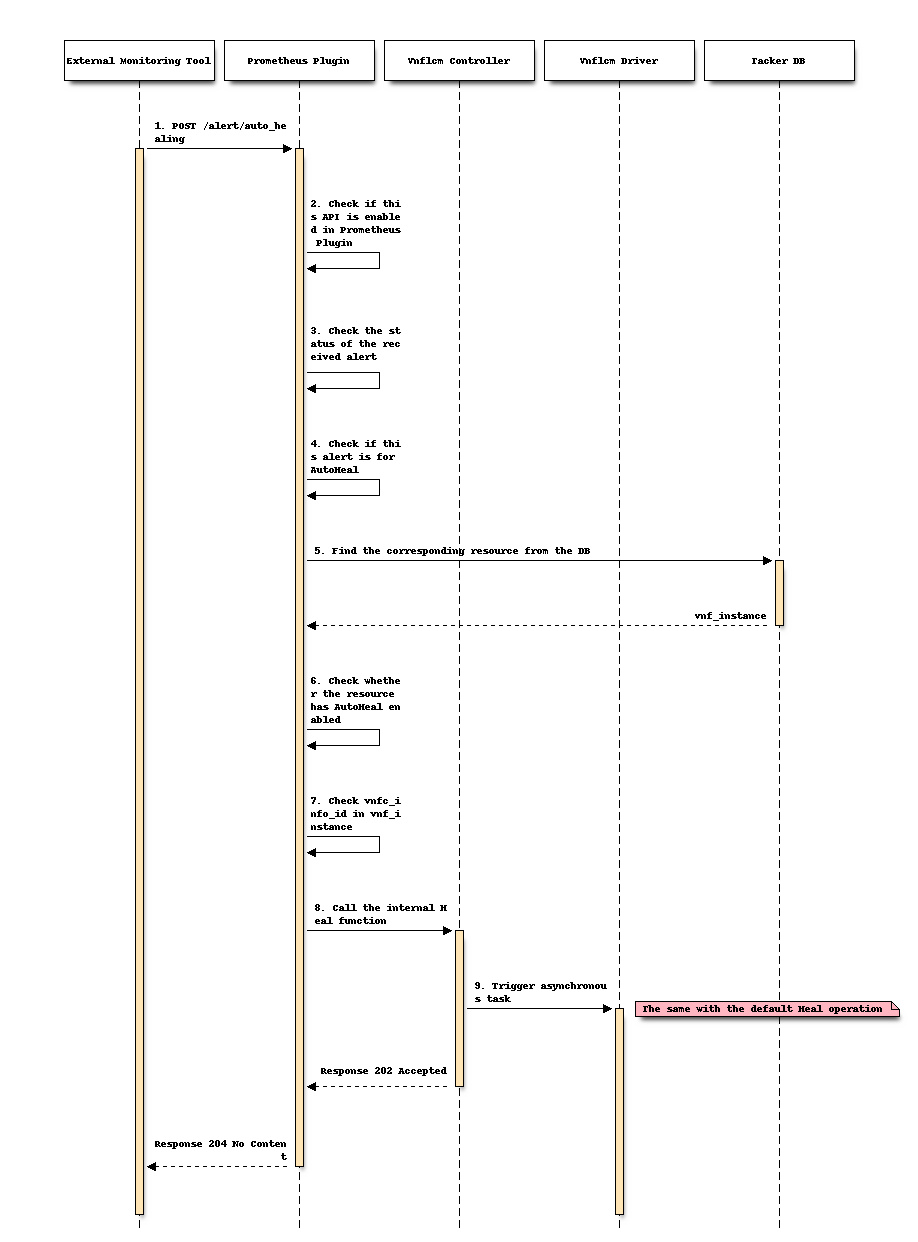
作为外部监控工具,Prometheus 通过用户定义的规则监控指定的资源。当 Prometheus 监控的数据与规则的条件匹配时,Prometheus 会向 Tacker 发送告警。
Tacker 接收到告警后,Prometheus 插件首先检查
tacker.conf中auto_healing字段的值是否为 True。如果不是,则终止该过程。Prometheus 插件检查告警中
status字段的值是否为firing。如果不是,则终止该过程。Prometheus 插件检查告警中
function_type字段的值是否为auto_heal。如果不是,则终止该过程。根据告警标签中
vnf_instance_id的值,Prometheus 插件从数据库中获取相应的vnf_instance。Prometheus 插件检查
vnf_instance.vnfConfigurableProperties中是否存在isAutohealEnabled键,并且其值为 True。如果不是,则终止该过程。Prometheus 插件检查告警请求中的
vnfc_info_id值是否存在于vnf_instance.vnfc_info中。根据
vnf_instance_id和vnfc_info_id的值,Prometheus 插件调用 vnflcm 的内部修复功能。从这一步开始,它与默认的修复操作完全相同。
注意
默认的修复操作是 all = False,并且修复了指定的 VNFC 实例。当设置 all = True 时,将修复指定的 VNFC 实例和存储资源。
注意
当发生多个告警时,应聚合或过滤告警。此实现将防止重复的修复操作。
触发自动伸缩¶
当外部监控工具检测到 VNF 或 CNF 的 CPU、内存、磁盘和其他资源欠载或超载时,它会将告警消息发送到 Tacker。Tacker 接收告警并对其进行验证。然后 Tacker 调用资源的内部伸缩功能。使用此伸缩方法来平衡欠载或超载的 VNF 或 CNF 资源。
伸缩操作的设计¶
以下是伸缩的示意图
+--------------------------------------------------------------------------+
| VNFM |
| +------------------------+ +----------------------------+ |
| | Tacker | | Tacker | |
| | Server | | Conductor | |
+----------------+ | | | | | |
| External | 2. POST | | 3. Check parameters and confirm aspect_id | |
| Monitoring | alert | | +------------+ | | | +--------+ |
| Tool +----------------> Prometheus +-------------------------------------------> Tacker | |
| (based on | | | | Plugin | | | | | DB | |
| Prometheus) | | | +------+-----+ | | | +--------+ |
+--+-------------+ | | | 4. Scale | | | |
| 1. Collect metrics | | | | | | |
| | | +------v-----+ | | +---------------+ | |
| | | | Vnflcm +--------------> Vnflcm Driver +--+ | |
| | | | Controller | | | +---------------+ | | |
| | | +------------+ | | +---------v--+ | |
| | | | | | Infra +--------------+ |
| | | | | | Driver | | | |
| | | | | +------------+ | | |
| | +------------------------+ +----------------------------+ | |
| +----------------------------------------------------------------------|---+
| |
| +-----------------------------------------------------------------+ |
| | Kubernetes | |
| | +---------------+-----------------------------------+
| | | | 5. Create or Delete Pod | |
| | | | | |
| | +--------v----+ +------v------+ +-------------+ | |
| | | +--------+ | | +--------+ | | | | |
+----------------------------------> | Pod | | | | Pod | | | | | |
| | | +--------+ | | +--------+ | | | | |
| | | Worker | | Worker | | Master | | |
| | +-------------+ +-------------+ +-------------+ | |
| +-----------------------------------------------------------------+ |
| |
| +-----------------------------------------------------------------+ |
| | OpenStack | |
| | +---------------+-----------------------------------+
| | | | 5. Create or Delete VM |
| | | | |
| | +--------v----+ +------v------+ +-------------+ |
| | | +--------+ | | +--------+ | | | |
+----------------------------------> | VM | | | | VM | | | | |
| | +--------+ | | +--------+ | | | |
| | Compute | | Compute | | Controller | |
| +-------------+ +-------------+ +-------------+ |
+-----------------------------------------------------------------+
外部监控工具收集指标并决定是否需要触发告警。
外部监控工具向
/alert/auto_scaling发送 POST 请求。Prometheus 插件接收告警请求并验证其内容。然后,它确认告警请求中的
aspect_id是否存在于数据库中。触发伸缩操作。
有两种类型的伸缩处理
如果触发了伸缩操作,则在相应的 VDU 中创建 VM 或 Pod。
如果触发了缩减操作,则在相应的 VDU 中删除 VM 或 Pod。
操作请求参数¶
API 详细信息在 REST API 影响 中描述。
操作顺序¶
以下描述了外部监控工具发送告警后 Tacker 的处理流程。

作为外部监控工具,Prometheus 通过用户定义的规则监控指定的资源。当 Prometheus 监控的数据与规则的条件匹配时,Prometheus 会向 Tacker 发送告警。
Tacker 接收到告警后,Prometheus 插件首先检查
tacker.conf中auto_scaling字段的值是否为 True。如果不是,则终止该过程。Prometheus 插件检查告警中
status字段的值是否为firing。如果不是,则终止该过程。Prometheus 插件检查告警中
function_type字段的值是否为auto_scale。如果不是,则终止该过程。Prometheus 插件检查告警中
auto_scale_type字段的值必须是SCALE_OUT或SCALE_IN。如果不是,则终止该过程。根据告警标签中
vnf_instance_id的值,Prometheus 插件从数据库中获取相应的vnf_instance。Prometheus 插件检查
vnf_instance.vnfConfigurableProperties中是否存在isAutoscaleEnabled键,并且其值为 True。如果不是,则终止该过程。Prometheus 插件检查告警请求中的
aspect_id值是否存在于vnf_instance.scale_status中。根据
vnf_instance_id、auto_scale_type和aspect_id的值,Prometheus 插件调用 vnflcm 的内部伸缩功能。从这一步开始,它与默认的伸缩操作完全相同。
注意
默认的伸缩操作是 numberOfSteps = 1,并且伸缩一个 VNFC 实例。
备选方案¶
无
数据模型影响¶
无
REST API 影响¶
以下 RESTful API 是 Tacker 特定的接口,用于 Tacker 和外部监控工具之间的自动修复。
- 名称:发送自动修复告警事件描述:接收来自外部监控工具发送的自动修复告警方法类型: POST资源的 URL:/alert/auto_healing请求:
数据类型
基数
描述
AutoHealAlertEvent
1
来自外部监控工具发送的自动修复告警
属性名称 (AutoHealAlertEvent)
数据类型
基数
描述
alerts
结构
1..N
此组中所有警报对象的列表。
>status
字符串
1
定义警报是 resolved 还是当前 firing。
>labels
结构
1
要附加到警报的一组标签。
>>receiver_type
字符串
1
接收器类型:tacker
>>function_type
字符串
1
功能类型:auto_heal
>>vnfInstanceId
标识符
1
vnf 实例的标识符。
>>vnfcInfoId
字符串
1
vnfc 信息的标识符。
>startsAt
DateTime
1
警报开始触发的时间。
>endsAt
DateTime
0..1
警报的结束时间。
>fingerprint
字符串
1
可用于标识警报的指纹。
响应:数据类型
基数
响应代码
描述
n/a
成功:204
当请求已成功读取时,应返回。
ProblemDetails
请参阅 [2] 的 6.4 条。
错误: 4xx/5xx
除了上述定义的响应代码外,ETSI GS NFV-SOL 013 [2] 的 6.4 条中定义的任何常见错误响应代码也可能返回。
以下 RESTful API 是 Tacker 特定的接口,用于 Tacker 和外部监控工具之间的自动伸缩。
- 名称:发送自动伸缩告警事件描述:接收来自外部监控工具发送的自动伸缩告警方法类型: POST资源的 URL:/alert/auto_scaling请求:
数据类型
基数
描述
AutoScaleAlertEvent
1
来自外部监控工具发送的自动伸缩告警
属性名称 (AutoScaleAlertEvent)
数据类型
基数
描述
alerts
结构
1..N
此组中所有警报对象的列表。
>status
字符串
1
定义警报是 resolved 还是当前 firing。
>labels
结构
1
要附加到警报的一组标签。
>>receiver_type
字符串
1
接收器类型:tacker
>>function_type
字符串
1
功能类型:auto_scale
>>auto_scale_type
字符串
1
伸缩类型:SCALE_OUT 或 SCALE_IN
>>vnfInstanceId
标识符
1
vnf 实例的标识符。
>>aspectId
字符串
1
要伸缩的目标 VDU。
>startsAt
DateTime
1
警报开始触发的时间。
>endsAt
DateTime
0..1
警报的结束时间。
>fingerprint
字符串
1
可用于标识警报的指纹。
响应:数据类型
基数
响应代码
描述
n/a
成功:204
当请求已成功读取时,应返回。
ProblemDetails
请参阅 [2] 的 6.4 条。
错误: 4xx/5xx
除了上述定义的响应代码外,ETSI GS NFV-SOL 013 [2] 的 6.4 条中定义的任何常见错误响应代码也可能返回。
安全影响¶
无
通知影响¶
无
其他最终用户影响¶
无
性能影响¶
无
其他部署者影响¶
无
开发人员影响¶
无
实现¶
负责人¶
- 主要负责人
Kenta Fukaya <kenta.fukaya.xv@hco.ntt.co.jp>
Yuta Kazato <yuta.kazato.nw@hco.ntt.co.jp>
- 其他贡献者
Koji Shimizu <shimizu.koji@fujitsu.com>
Yoshiyuki Katada <katada.yoshiyuk@fujitsu.com>
Ayumu Ueha <ueha.ayumu@fujitsu.com>
工作项¶
实现 Tacker 以支持
外部监控接口
添加新的 Rest API
POST /alert/auto_healing以接收来自外部监控工具发送的自动修复告警。修改 Rest API
POST /alert/auto_scaling以接收来自外部监控工具发送的自动伸缩告警。
添加新的单元和功能测试。
依赖项¶
无
测试¶
将添加单元和功能测试,以涵盖规范所需的用例。
文档影响¶
将添加完整的用户指南,以说明如何通过外部监控工具进行自动修复和自动伸缩。
更新 API 文档,以说明 REST API 影响 中提到的 API 添加项。
