增强部署流程¶
本规范支持 VNF 实例的部署功能,并增强了 Tacker 在各种系统中的适用性。
问题描述¶
部署约束在 ETSI NFV-SOL 003 v3.3.1 [1] 中定义,VNFM 将其发送给 NFVO 以进行资源部署决策。在 VNF 生命周期管理 (LCM) 中,有些情况下由于部署约束或可用区资源不足而导致 VNF 未部署。从高可用性的角度来看,Tacker 需要在 Grant Request 和可用区重新选择功能中实现一个 fallbackBestEffort 选项。
提议的变更¶
1. 添加 fallbackBestEffort 参数¶
fallbackBestEffort 用于查找指定资源无法根据指定的部署约束分配时的替代最佳努力部署,定义在 ETSI NFV-SOL 003 v3.3.1 [1] 中。在本规范中,Tacker 将在 Grant Request (PlacementConstrains) 和 Tacker 配置文件中支持额外的参数 fallbackBestEffort。我们将修改 Tacker conductor 和 tacker.conf。添加定义的详细信息在 3. 向配置文件添加定义 中描述。
GrantRequest.PlacementConstrains
属性名称
数据类型
基数
描述
fallbackBestEffort
布尔值
0..1
指示是否以回退最佳努力方式处理约束。默认值为“false”。
注意
如果 placement constraints 中存在 fallbackBestEffort 且设置为“true”,则 NFVO 应以最佳努力方式处理 Affinity/Anti-Affinity 约束,在这种情况下,如果无法根据指定的部署约束分配指定的资源,则 NFVO 会为指定的资源查找替代最佳努力部署。
2. 可用区重新选择¶
VNFLCM v2 API (VNF 的 instantiate/heal/scale) 流程可以在必要时更改 NFVO 通知的使用可用区。如果 NFVO 通知到的可用区资源不足,则 VNF 将在不同的可用区中重新创建/更新。重新选择可用区并重新创建/更新 VNF,直到没有更多候选区为止。
注意
可用区重新选择仅在为用户数据类指定 StandardUserData 时有效。
1) 可用区重新选择流程图¶
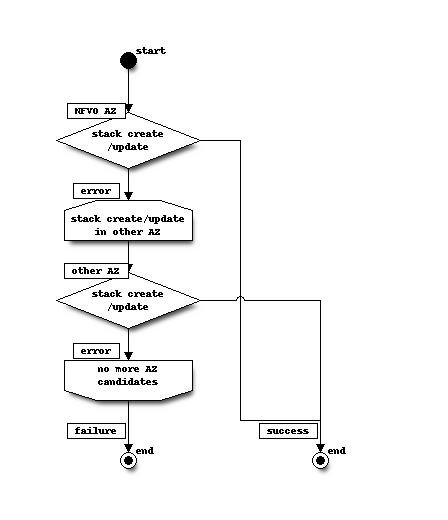
该过程包括以下步骤,如图所示
在 NFVO 通知到的可用区中执行“stack create/update”。
如果在 1 中发生资源不足错误,则获取可用区列表。可用区列表的详细信息在 2) 获取和管理可用区列表 中描述。
从 2 中获取的可用区列表中选择一个可用区(排除发生错误的可用区),并重新执行“stack create/update”。重新选择策略的详细信息在 3) 可用区重新选择策略 中描述。
如果 3 中重新选择的可用区中的“stack create/update”变为资源不足错误,则重新选择可用区并重复,直到“stack create/update”成功或所有可用区候选区都失败。
注意
检测错误详情在 4) 检测资源不足错误的的方法 中描述。如果错误不是资源不足错误,则流程结束(失败),而不重新选择可用区。
2) 获取和管理可用区列表¶
获取 可用 区 列表
提取所有可用区作为重新选择的候选区,而不限制要重新选择的可用区。虽然可以仅提取 Grant 允许的可用区作为重新选择的候选区,但由于这取决于 NFVO 产品规范,因此本规范不采用这种方法。
可用区的概念存在于 Compute/Volume/Network,但本规范仅针对 Compute。原因是 SOL(SOL003 v3.3.1 Type: GrantInfo [1]) 指定了 GrantInfo 的 zoneId,这是 addResources 等数据类型的类型,通常指定为 COMPUTE 资源。
注意
SOL003 v3.3.1 Type: GrantInfo对“Grant”结构中定义的资源区域的标识符的引用,该资源区域是将此资源放置到的区域。如果适用,对于新资源,应存在该标识符(通常,Compute 资源),并且对于已经分配的资源,则应不存在该标识符。如果适用,对于新资源,应存在该标识符(通常,Compute 资源),并且对于已经分配的资源,则应不存在该标识符。
调用 Compute-API “GetDetailedAvailabilityZoneInformation” [2] 以从与“nova-compute”关联的“hosts”响应中获取可用区。
Compute 端点以以下方式获取。
管理 可用 区 列表
在可用区重新选择迭代完成之前将其保存在内存中,并在完成后丢弃(不在 DB 中存储)。
注意
错误处理 重试 考虑由于可用区列表未保存并再次检索,因此无法保证在重试执行时以相同的顺序重新选择可用区。
3) 可用区重新选择策略¶
排除发生错误的可用区,并考虑 PlacementConstraint 的 Anti-Affinity 重新选择候选区。
注意
在重新选择期间不考虑可用区的资源状态。
可以通过以下方式识别发生错误的可用区。
在“stack create/update”发生错误后调用 Heat-API “Show stack details”。
通过 1 的响应中的 stack_status_reason 识别由于资源不足而发生的 VDU。
通过 2 识别的 VDU 识别可用区。
注意
在重新选择尝试期间,一旦发生资源不足的可用区可能会解决,但这些可用区将不会被重新选择。在 Scale/Heal 操作中,已经部署的 VDU 将不会被重新创建。
每个 VNFLCM v2 API (VNF 的 instantiate/heal/scale) 的可用区重新选择如下。
先决条件:可用区 AZ-1/AZ-2/AZ-3/AZ-4/AZ-5 存在,并且 VNF VDU1-0/VDU1-1/VDU2-0/VDU2-1 已部署
注意
VNF 在 VDU1 中位于同一可用区(Affinity),VNF 在 VDU2 和 VDU1/VDU2 中位于不同的可用区(Anti-Affinity)。
Instantiate
在重新选择之前,以下尝试部署失败(AZ-1 和 AZ-2 资源不足)
VDU1-0: AZ-1
VDU1-1: AZ-1
VDU2-0: AZ-2
VDU2-1: AZ-3
VDU1-0/1: 重新选择以下(排除 AZ-1/AZ-2/AZ-3,选择 AZ-4 或 AZ-5)
VDU1-0: AZ-4
VDU1-1: AZ-4
VDU2-0: AZ-2
VDU2-1: AZ-3
VDU2-0: 重新选择以下(排除 AZ-2/AZ-3/AZ-4,选择 AZ-1 或 AZ-5)
VDU1-0: AZ-4
VDU1-1: AZ-4
VDU2-0: AZ-5
VDU2-1: AZ-3
注意
以上只是一个示例,重新选择目标是从可用区候选区中随机选择的。
Heal(VDU1-1/VDU2-0)
在重新选择之前,以下尝试部署失败(AZ-1 和 AZ-2 资源不足)
VDU1-0: AZ-1
VDU1-1: AZ-1
VDU2-0: AZ-2
VDU2-1: AZ-3
VDU1-1: 重新选择以下(排除 AZ-1/AZ-2/AZ-3,选择 AZ-4 或 AZ-5)
VDU1-0: AZ-1
VDU1-1: AZ-4
VDU2-0: AZ-2
VDU2-1: AZ-3
注意
仅针对 Heal 目标 VNF 进行可用区重新选择。因此,由于重新选择操作,可能无法满足 Affinity。
VDU2-0: 重新选择以下(排除 AZ-1/AZ-2/AZ-3/AZ-4,选择 AZ-5)
VDU1-0: AZ-1
VDU1-1: AZ-4
VDU2-0: AZ-5
VDU2-1: AZ-3
Scale out(添加 VDU1-2/VDU1-3)
在重新选择之前,VDU1-3 部署失败(AZ-1 资源不足)
VDU1-0: AZ-1
VDU1-1: AZ-1
VDU1-2: AZ-1
VDU1-3: AZ-1
VDU2-0: AZ-2
VDU2-1: AZ-3
VDU1-2/3: 重新选择以下(排除 AZ-1/AZ-2/AZ-3,选择 AZ-4 或 AZ-5)
VDU1-0: AZ-1
VDU1-1: AZ-1
VDU1-2: AZ-4
VDU1-3: AZ-4
VDU2-0: AZ-2
VDU2-1: AZ-3
注意
在 Affinity 的情况下,即使 VDU1-2 已成功部署,VDU1-2/VDU1-3 可用区也将被重新选择。现有的 VDU1-0/VDU1-1 将不会被重新选择,因此即使在 Affinity 的情况下,所有 VDU 可能不会位于同一可用区。
Scale out(添加 VDU2-2/VDU2-3)
在重新选择之前,VDU2-3 部署失败(AZ-5 资源不足)
VDU1-0: AZ-1
VDU1-1: AZ-1
VDU2-0: AZ-2
VDU2-1: AZ-3
VDU2-2: AZ-4
VDU2-3: AZ-5
VDU2-3: 重新选择以下(排除 AZ-5,选择 AZ-1 或 AZ-2 或 AZ-3 或 AZ-4)
VDU1-0: AZ-1
VDU1-1: AZ-1
VDU2-0: AZ-2
VDU2-1: AZ-3
VDU2-2: AZ-4
VDU2-3: AZ-1
注意
如果考虑到 Anti-Affinity 没有剩余的可用区候选区,则从其他非失败可用区中随机选择重新选择目标。在这种情况下,无法满足 Anti-Affinity。
4) 检测资源不足错误的方法¶
当“stack create/update”失败时,从 Heat-API 响应的“List resource events” [5] 中检测失败是否由于资源不足。从响应中的“resource_status_reason”参数中提取指示资源不足的错误消息。
注意
在资源不足的情况下,错误发生在“stack create/update”返回接受响应之后,因此使用“List resource events”响应来检测原因。
以下是在“resource_status_reason”中存储的资源不足错误消息的示例。
ex1) 将“OS::Nova::Server”中定义的 flavor 设置为无法部署的大值(存储不足/vCPU 不足/内存不足)。
Resource CREATE failed: ResourceInError: resources.<VDU-name>: Went to status ERROR due to “Message: No valid host was found. , Code: 500”
ex2) 指定了无法分配给“OS::Nova::Server”中定义的 flavor 的 extra-spec。
Resource CREATE failed: ResourceInError: resources.<VDU-name>: Went to status ERROR due to “Message: Exceeded maximum number of retries. Exhausted all hosts available for retrying build failures for instance <server-UUID>., Code: 500”
Tacker 检测为资源不足的错误消息由配置文件的正则表达式指定。添加定义的详细信息在 3. 向配置文件添加定义 中描述。
通过根据运营策略更改指定此正则表达式的方法,可以灵活地设置策略,以更高的误检容忍度检测更多错误消息为资源不足,或者仅检测特定的错误消息为资源不足。
ex1) 增加误分类容忍度以检测更多错误消息作为资源不足的策略的正则表达式
Resource CREATE failed:(. *)
ex2) 指定以更高的误报容忍度检测更多错误消息作为资源不足的策略的正则表达式
Resource CREATE failed: ResourceInError: resources(. *): Went to status ERROR due to “Message: No valid host was found. *): Went to status ERROR due to “Message: Exceeded maximum number of retries. Exhausted all hosts available for retrying build failures for instance(. *). , Code: 500”。
3. 向配置文件添加定义¶
将以下定义添加到 tacker.conf 文件。
“GrantRequest.PlacementConstrains.fallbackBestEffort”的布尔值
默认值:“false”
检测资源不足错误的正则表达式
默认值:资源不足错误的正则表达式
注意
考虑可以捕获 stack create 和 stack update 错误的正则表达式。
可用区重新选择的最大重试次数
默认值:无上限
注意
考虑存在大量可用区并且可用区重新选择过程花费过长的情况。
数据模型影响¶
无
REST API 影响¶
无
安全影响¶
无
通知影响¶
无
其他最终用户影响¶
无
性能影响¶
无
其他部署者影响¶
无
开发人员影响¶
无
实现¶
负责人¶
- 主要负责人
Yuta Kazato <yuta.kazato.nw@hco.ntt.co.jp>
- 其他贡献者
Hiroo Kitamura <hiroo.kitamura@ntt-at.co.jp>
Ai Hamano <ai.hamano@ntt-at.co.jp>
工作项¶
实现可用区重新选择功能。
在 GrantRequest API 中添加新的参数
fallbackBestEffort。在 Tacker 配置文件
tacker.conf中添加新的定义。添加新的单元和功能测试。
在 Tacker 用户指南中添加新的示例。
依赖项¶
测试¶
将为新的放置功能添加单元和功能测试用例。
文档影响¶
需要将新的支持功能添加到 Tacker 用户指南中。
