NUMA 感知 vSwitches¶
https://blueprints.launchpad.net/nova/+spec/numa-aware-vswitches
像 Open vSwitch (内核或 DPDK 数据路径)、Lagopus 或 Contrail DPDK vRouter 等 vSwitches 都有一定程度的 NUMA 亲和性。这可能是因为它们使用一个或多个物理网络接口,通常通过 PCIe 连接,或者它们使用绑定到给定 NUMA 节点的用户空间进程。这种 NUMA 亲和性目前在创建实例时没有被考虑在内。这可能导致性能下降高达 50% [1]。
问题描述¶
在 基于 I/O(PCIe)的 NUMA 调度 中,nova 解决了在使用 libvirt 驱动程序时 PCIe 设备的 NUMA 亲和性问题。这是通过利用 libvirt 提供的这些 PCIe 设备的 NUMA 信息来实现的。然而,使用软件交换解决方案与硬件交换相比使问题变得复杂。在这些情况下,我们不会传递整个 PCI 设备或虚拟功能,而是传递一个 VIF 对象。尽管如此,vSwitch 将使用物理硬件访问物理网络,并且基于此具有对特定 NUMA 节点的亲和性。目前没有考虑这种 NUMA 亲和性,这可能导致跨 NUMA 节点流量和显著的数据包处理性能下降。
重要
本规范仅关注实例与物理 NIC 之间的流量,或“物理到虚拟 (PV)”流量。实例之间的流量,或“虚拟到虚拟 (VV)”流量,不在本规范的范围内。
工作示例:OVS-DPDK¶
对于那些对它的工作原理感兴趣的人,让我们使用一种可能的 vSwitch 解决方案 OVS-DPDK 作为示例。考虑以下网络拓扑
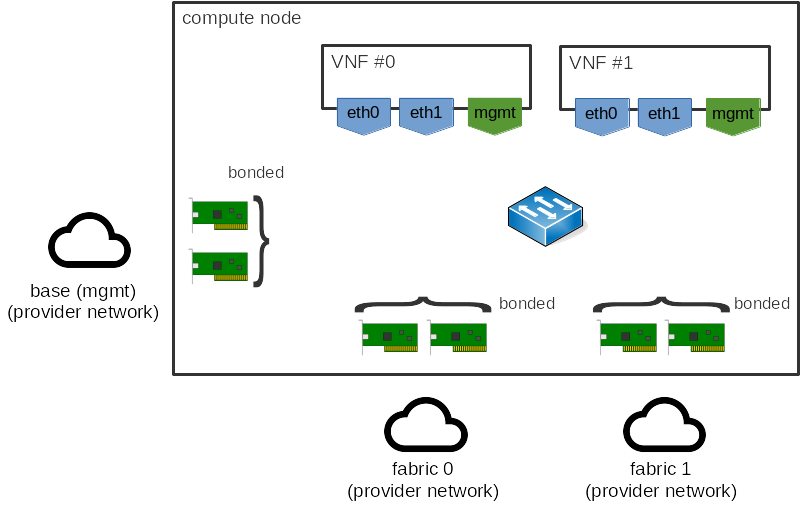
在上述示例中,我们有两个虚拟机,每个虚拟机都有多个接口,以及多个主机接口。使用 OVS-DPDK 时,虚拟机接口通常是 dpdkvhostuser 或 dpdkvhostuserclient 端口 [2],而主机中的物理网络接口将是 dpdk 端口 [3]。每个端口都有多个传输 (Tx) 和接收 (Rx) 队列,以实际地在每个接口之间移动数据包。
OVS-DPDK 使用多个轮询模式驱动程序 (PMD) [4] 来执行实际的数据包处理,并且每个队列被分配给一个 PMD。如果 DPDK 使用 libnumactl 和 CONFIG_RTE_LIBRTE_VHOST_NUMA=y [5] 编译,则此分配具有 NUMA 感知,并且队列将被分配到与以下两者相同的 NUMA 节点:
队列来自的物理网络接口,对于
dpdk接口与
dpdkvhostuser或dpdkvhostuserclient接口关联的一个或多个 NUMA 节点
如果存在多个队列(即多队列),则分配是按队列完成的,以确保单个 PMD 不成为瓶颈。如果给定 NUMA 节点存在多个 PMD(通常是这种情况),则分配将以轮询方式完成。如果不存在本地(从 NUMA 本地性意义上讲)PMD 来服务队列,则队列将被分配给远程 PMD。
那么,让我们进一步构建上述示例,并将这种 NUMA 亲和性纳入其中。我们假设有两个 NUMA 节点,虚拟机和 NIC 都分布在这些节点之间。这给我们带来了如下情况
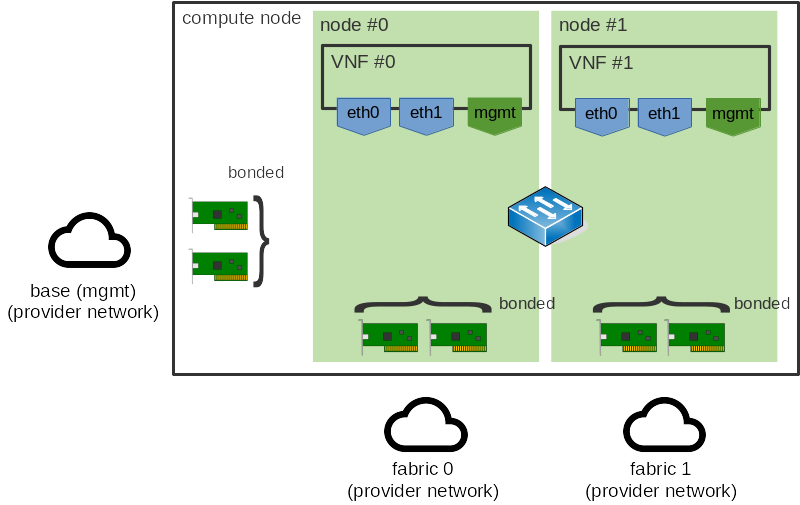
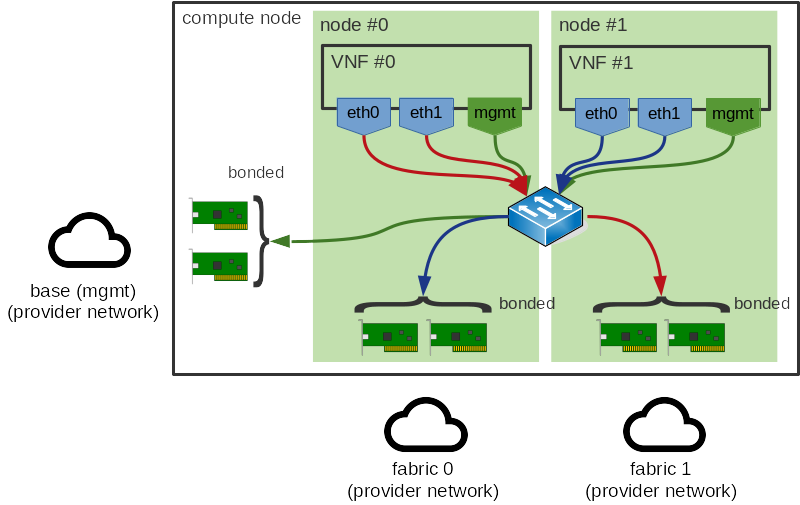
我们想要避免的是跨 NUMA 节点的流量。我们不特别关心 VM <-> VM 流量(稍后会对此进行说明),因此这种流量可能如下所示
注意
在 OVS-DPDK 中,出站流量(VM -> Phy)并不昂贵,因为从虚拟机队列中提取数据包的 PMD 位于与虚拟机队列相同的 NUMA 节点上。同时,由于 DMA,写入物理网络接口队列是高效的。但是,返回路径成本更高,因为无法从 DMA 中受益地将数据包排队到虚拟机队列。
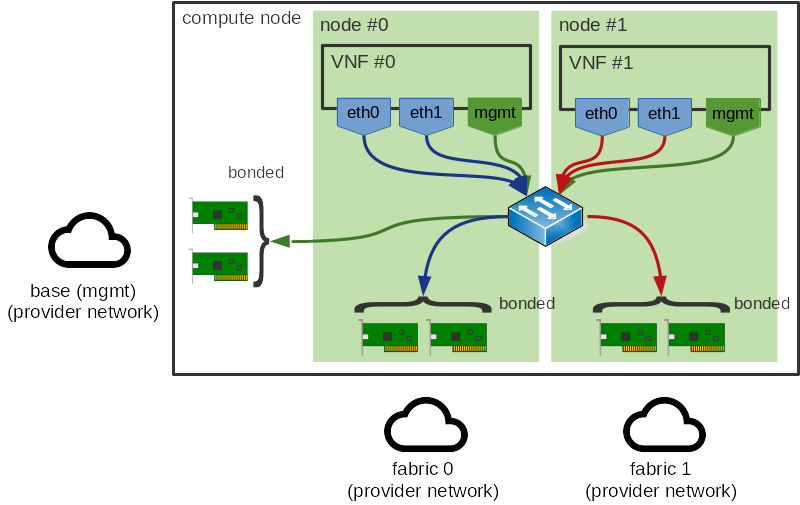
这是问题的根本原因:显然,虚拟机应该与它正在使用的 NIC 位于同一个 NUMA 节点上,如下所示。这是我们希望通过本规范解决的问题。
用例¶
作为用户,我希望确保我能够充分利用高度优化的高性能 vSwitch 解决方案
作为操作员,我不想恢复到像动态调整 vcpu_pin_set 这样的自定义解决方法,只是为了满足我的客户所要求的性能。
提议的变更¶
由于我们希望提供适用于多种网络后端的通用解决方案,因此该解决方案应建立在 neutron 及其概念之上。neutron 不会公开像 Open vSwitch 桥接器这样的内容,而是提供网络对象,如网络、子网和端口。端口对我们没有特别的帮助,因为我们不是直接将给定端口附加到虚拟机。相反,我们将使用网络,或者更具体地说,使用物理 NIC 的网络。有两种类型的网络 技术 在起作用:flat 和 VLAN,也称为 L2 physical 或 non-tunneled 网络,以及 GRE 或 VXLAN,也称为 L3 tunneled 网络。
注意
其他机制,例如 OPLEX(思科专有),通过使用非默认 Neutron 后端也受支持。这些在本规范的范围内被认为是不相关的。我们还认为不提供外部网络连接的 local 超出了范围。
注意
此处讨论的网络 技术 与 neutron 提供的网络 类型 不同,例如 provider 网络 [6] [7] 和 tenant 网络 [8] [9],并且与可用的 架构 不同,例如 pre-created networking 或 self-serviced networking。网络 类型 和 架构 更侧重于 谁 可以配置给定网络(用户用于租户网络,管理员用于两者)以及 在哪里 找到该配置(对于提供者网络,通常是配置文件,但管理员可以显式覆盖此配置)。下表说明了这一点。
常用名称 |
用户可配置? |
L2(非隧道) |
L3(隧道) |
|---|---|---|---|
提供者网络 |
否 |
是 |
否 |
租户网络 |
是 |
是(不常见) |
是(常见) |
本规范的重点是 技术,因为这些技术决定了流量如何从计算节点流出,这是我们在此关注的主要问题。
- 物理网络
物理网络,或 physnet,通过使用任意标签来标识。在 Open vSwitch (OVS) ML2 驱动程序的情况下,这些标签映射到包含物理接口的给定 OVS 桥接器,使用
[ovs] bridge_mappingsneutron 配置选项。例如openvswitch_agent.ini¶[ovs] bridge_mappings = provider:br-provider
这将把 physnet
provider映射到 OVS 桥接器br-provider。预计此桥接器将包含一个逻辑接口(您可以使用绑定 NIC 提供故障转移)。Linux Bridge ML2 驱动程序存在类似的配置选项:[linux_bridge] physical_interface_mappings。- 隧道网络
具有隧道覆盖的网络,或隧道网络,也可能提供外部网络连接。可能有许多隧道网络,但主机上应该只有一个逻辑接口(您可以使用绑定 NIC 提供故障转移)来处理这些网络的流量。此接口使用
[ovs] local_ipneutron 配置选项进行配置。例如openvswitch_agent.ini¶[ovs] local_ip = OVERLAY_INTERFACE_IP_ADDRESS
这将导致所有 VXLAN 或 GRE 流量使用与
OVERLAY_INTERFACE_IP_ADDRESS对应的 IP 的接口。Linux Bridge ML2 驱动程序为 VXLAN 流量存在类似的配置选项:[vxlan] local_ip。此驱动程序不支持 GRE 流量。
物理网络和隧道网络都可以在同一主机上使用。考虑到所有这些,我们提出以下更改。
更改¶
配置选项¶
我们建议添加一个新的配置选项和多个动态生成的配置组。
配置选项
[neutron] physnets将列出您希望提供 NUMA 亲和性的所有 physnet。配置组
[neutron_tunnel]将允许配置隧道网络。只需要一个配置组即可,因为所有隧道网络都必须共享一个逻辑接口。此组将包含单个配置选项numa_nodes,其中列出隧道网络绑定的主机 NUMA 节点。多个
[neutron_physnet_$PHYSNET]配置组,每个$PHYSNET在[neutron] physnets中,将允许配置这些 physnet。每个配置组将包含一个配置选项numa_nodes,其中列出绑定到使用此 physnet 的网络的宿主 NUMA 节点。
这些组将全部动态生成,这是必需的,因为 [neutron_physnet_$PHYSNET] 中 $PHYSNET 的值是任意的,只能从 [neutron] physnets 中相应的数值中识别出来。
这将导致如下配置文件
[neutron]
physnets = physnet0,physnet1
[neutron_physnet_physnet0]
numa_nodes = 0
[neutron_physnet_physnet1]
numa_nodes = 0,1
[neutron_tunnel]
numa_nodes = 1
其中
[neutron] physnets一个字符串列表,对应于此主机上配置的所有 neutron 提供者网络 physnet 的名称。
[neutron_physnet_$PHYSNET]一个选项部分,对应于
[neutron] physnets中定义的一个 physnet。这反过来具有以下键numa_nodes与此后端关联的 NUMA 节点的整数列表。它被定义为列表,以适应跨 NUMA 绑定和多路径路由。如果为空,则 physnet 没有分配 NUMA 亲和性。
注意
具有主动-主动跨 NUMA 节点绑定的智能 vSwitch 可以将 VM 接口的 NUMA 亲和性作为输入,用于选择绑定对的哈希,以确保主机间流量没有跨 NUMA 流量。或者,一个愚蠢的 vSwitch 可以使用 OpenFlow 多路径操作和一些其他的 Open vSwitch 花哨来将 MAC 亲和性设置为 NUMA 本地绑定对,通过硬编码 os-vif 来实现。这不在本规范的范围内。
[neutron_tunnel]与
[neutron_physnet_$PHYSNET]相同,但用于隧道网络使用的接口。
如前所述,主机可以使用 physnet 网络、隧道网络或两者的组合。因此,并非所有配置值都必须在给定主机上指定。
此配置将由编排工具在部署时生成,就像常规主机网络配置一样生成。这是因为识别任意网络的 NUMA 亲和性是一个复杂的问题,其复杂性随着网络和 VNFs 的设计而增加。编排工具负责配置物理 NIC 如何被各种 neutron 网络使用,并且只需稍加工作就可以将其扩展到包括 NUMA 亲和性(例如,通过结合来自诸如 ethtool 之类的工具的信息与来自 sysfs 的信息)。
对于具有 physnet 和定义的 [neutron_physnet_$PHYSNET] 组以及所有隧道网络(假设定义了 [neutron_tunnel])的网络,将提供 NUMA 亲和性。这将存储在主机的 NUMACell 对象中。如果某个网络未在任何此类选项中定义,则不会提供 NUMA 亲和性。与其他提供 NUMA 亲和性的设备一样,即 PCI 或 SR-IOV [10] 设备,尝试启动实例可能会在许多情况下失败。这些情况将在后面描述。
网络 API 客户端¶
nova中的网络API客户端当前提供了一个方法,create_pci_requests_for_sriov_ports [11],用于检索启动实例时请求的每个端口的physnets和VNIC类型信息,目的是为SRIOV端口创建PCI请求。这将变得更加通用,并扩展为获取任何请求网络的隧道状态信息。这些信息将存储(但不持久化)在一个新的对象中,InstanceNUMANetworks,供后续使用。
注意
与现有的SR-IOV功能一样,这只会处理与physnet关联的整个网络的情况,而不是网络的某个片段。
调度¶
除了配置更改之外,我们需要开始将存储在新对象InstanceNUMANetworks中的请求phynets和tunneled networks列表,作为RequestSpec对象的一个字段。该字段不会持久化到数据库中。我们需要这些信息,以便在主机上进行调度时使用它来构建实例的NUMA拓扑,但不需要在之后存储它。我们还需要扩展NUMATopologyFilter返回的limits字典,以包含有关网络的信息。这是必要的,以便我们在计算节点上的claim阶段有东西可以引用。在两种情况下,缓存的信息都需要在发生移动操作时更新。
虚拟化驱动程序¶
目前只有libvirt驱动程序支持此功能所需的NUMA亲和性功能的全部范围。虽然其他驱动程序,特别是Hyper-V,支持一些NUMA功能,但这些功能与客户NUMA拓扑相关,而不是将vCPU进程放置在主机NUMA节点上。在numa_fit_instance_to_host中找到的NUMA拟合代码将被更新,以使用新的InstanceNUMANetworks对象,并使用它来确定要使用的主机NUMA节点。 InstanceNUMANetworks对象将从RequestSpec对象或调度程序限制中构建,并由调用此函数的调用者传递。
潜在问题¶
如上所述,这是一个很难合理解决的问题,因此,需要一些特殊解决方法来处理许多情况。第一种情况是来自不同NUMA节点的物理NIC被绑定。这不会破坏整个系统,但预期性能会很差。这种情况也会出现在SR-IOV中,通常是因为
操作员配置错误
操作员不关心最佳性能
操作员希望通过在NIC上分散工作来提供弹性,并且无法或不愿使用来自同一NUMA节点的两个NIC
鉴于我们无法确定这是有意为之还是无意为之,我们已将numa_nodes定义为列表,而不是单个整数。这将允许我们捕获绑定NIC的组合NUMA亲和性。
第二种情况是具有复杂的多NIC配置的客户。大多数VNFs使用多个接口,其中一些将用于VM管理接口(SSH、日志记录、SNMP等),而其余的将用于实际的数据平面接口。NUMA亲和性对前者无关紧要,因此我们可以忽略这些,但是,如果后者端口具有不同的亲和性,则可能无法确定自然的NUMA亲和性。如下所示
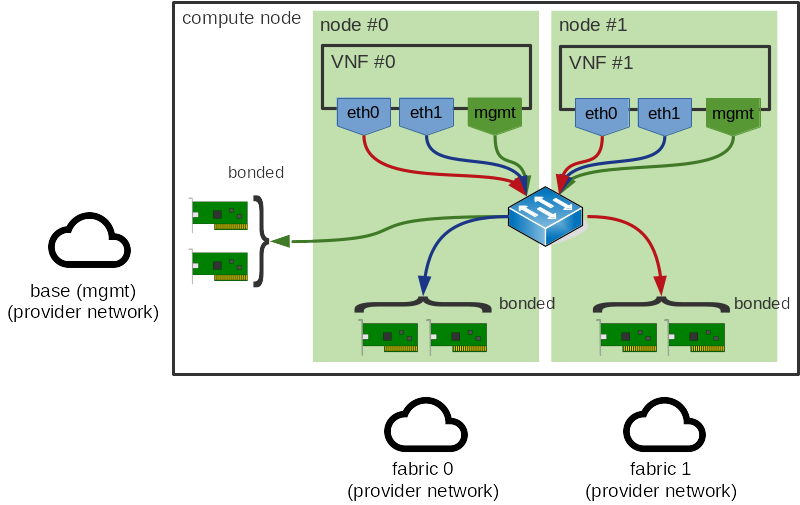
这种情况也发生在PCI和SR-IOV设备中,在这里,与这些设备一样,我们期望用户定义多节点客户拓扑,或者避免为非数据平面接口指定NUMA亲和性。
第三种情况是VM到VM流量。当前的NFV部署通常不关心VM到VM流量,因为极不可能将两个相关的VNFs有意地放置在给定的主机上。因此,VM到VM流量不在此规范的范围内。
第四种也是最后一种情况是附加到创建实例后的接口。需要NUMA亲和性的接口必须在创建实例时请求,并且在此之后附加的任何接口将不会应用NUMA亲和性。这是为了限制此功能的范围,并且将在未来的规范中解决,但是,可以对附加新接口后的resize操作或类似操作使用,以获得这些接口的NUMA亲和性。
备选方案¶
有多种可能的解决方案来解决这个问题,复杂程度各不相同。
我们可以将静态后端-NUMA映射存储在neutron中,并将其作为VIF请求的一部分传递。由于neutron负责所有网络相关的事情,将此信息存储在nova中可能看起来违反了这两个服务之间的关注点分离。但是,这只是部分正确的。虽然neutron负责创建网络元素,例如端口和桥接,但nova负责将它们连接到实例。这不会让nova参与实际创建底层网络元素,而是它现在将存储有关所述元素的其他元数据。将此配置移动到neutron会使事情变得复杂,但收益却很少。
一个更精细的替代方案是在neutron中动态生成此信息,而不是在nova或neutron中硬编码它。可以通过新的扩展或类似方式公开此信息。这似乎需要部署者付出最少的努力,并且看起来是最明智的做法。但是,这也不是完美的。实施此功能需要更改neutron中的几乎每个后端,并且可能无法用于某些后端和某些复杂的配置。如前所述,我们在部署时可以访问有关整体网络设计的相关信息,并且放弃它以支持动态生成会给公式引入不必要的魔术。
我们可以全力以赴地从neutron侧进行放置,并开始存储有关neutron中各种后端的有关信息。然后nova可以使用这些信息来做出其调度决策。从技术上讲,这是最好的解决方案,因为它解决了这个问题以及许多其他问题,例如带宽感知调度以及在降落在该节点之前发现计算节点上可用的网络类型。但是,我们目前没有明确的故事来对placement中的NUMA资源进行建模[12]。鉴于我们目前面临的租户数据平面性能问题,这似乎是不可行的。但是,这并不意味着我们无法在未来将这些信息迁移到placement。这在都柏林Rocky PTG期间讨论过[13]。
OpenDaylight (ODL)使用存储在OVS(如桥接映射)中的每个主机配置,然后由ODL读取并填充到Neutron DB中作为伪代理。我们可以将NUMA:physnet亲和性存储在每个主机的网络上,最终将其传播到nova的VIF请求。但是,这对于租户网络不可行,因为主机的NUMA拓扑对租户不可见。此外,这依赖于网络后端的特定功能,这些功能可能不适用于其他后端。
最后,这是核选项,我们可以简单地接受在NFV空间中做出自动调度决策很困难的事实,并且最好将此委托给另一个系统。为此,我们可以简单地公开一个“在此主机NUMA节点上部署”旋钮,并让用户自行操作。这将简化我们的生活并满足这些用户的需求,但它明显不符合云的理念,并且不太可能获得任何吸引力。
数据模型影响¶
将添加一个新的对象NUMANetworkInfo来存储与主机NUMA节点关联的网络信息。它将映射到父NUMACell对象,使用network_info字段,并将在调度和声明期间用于与请求的网络进行比较。
将添加一个新的对象InstanceNUMANetworks来存储有关实例请求或附加的网络是physnets还是tunneled networks的信息。它们将由create_pci_requests_for_sriov_ports函数的更通用的版本填充。它们不会被持久化,而仅仅存储为一种从API获取此信息到调度程序用于过滤的方式。
REST API 影响¶
无。
安全影响¶
无。
通知影响¶
无。
其他最终用户影响¶
无。
性能影响¶
由于额外的NUMA亲和性检查,调度实例的时间会略微增加。但是,某些vSwitch解决方案(例如OVS-DPDK)的网络性能将提高高达100%。
其他部署者影响¶
部署工具需要增强,以便在部署时配置新的配置选项。
开发人员影响¶
此更改将需要对调度程序进行更改,但只有libvirt驱动程序才能提供正确调度这些请求所需的所有NUMA亲和性功能。其他驱动程序,特别是Hyper-V,目前不提供足够的对主机NUMA信息的了解,因此无法以有意义的方式将此更改合并到其中。如果将来发生这种情况,则需要扩展驱动程序以使用配置选项和请求规范属性。
升级影响¶
需要为每个nova-compute服务nova.conf文件创建新的配置选项。此外,需要运行任何数据库迁移。
实现¶
负责人¶
- 主要负责人
stephenfinucane
- 其他贡献者
sean-k-mooney
工作项¶
添加对新配置选项和动态配置组的支持。
创建一个
NUMANetworkInfo对象。这将用于存储在nova.conf中提供的NUMA-网络配置,即任何physnets或tunneled networks是否与此单元关联。将
network_info字段添加到NUMACell对象,它将包含主机节点网络信息,形式为NUMANetworkInfo对象。这是必需的,以便nova-scheduler和nova-conductor可以在调度和声明期间访问此信息。创建一个
InstanceNUMANetworks对象。这将用于存储实例请求的网络是physnets还是tunneled属性的组合。使
create_pci_requests_for_sriov_ports更加通用。这可用于获取我们所需的大部分信息来填充新的InstanceNUMANetworks对象。将
numa_networks字段添加到RequestSpec对象,它将是API服务从对create_pci_requests_for_sriov_ports的调用生成的InstanceNUMANetworks对象。此信息将由NUMATopologyFilter用于过滤无法满足请求的主机。该字段不会被持久化,因为它仅在调度新实例时才需要由调度程序使用。修改
numa_fit_instance_to_host函数以接受新的numa_networks参数,该参数将是InstanceNUMANetworks的实例,并在构建NUMA拓扑时考虑这些参数。修改
NUMATopologyFilter以填充limits字典的numa_networks字段。这将使用RequestSpec.numa_networks的值构建的InstanceNUMANetworks实例填充。将InstanceNUMANetworks对象传递给numa_fit_instance_to_host。修改存储在
Instance.info_cache.network_info中的序列化模型,以包含类似于每个网络的physnet和tunneled字段的内容。这需要在任何移动操作期间进行声明。修改nova-conductor以从
Instance.info_cache.network_info字段构建InstanceNUMANetworks对象,该对象可用于填充任何移动操作的RequestSpec对象。修改计算节点上的声明方式,以考虑来自调度程序传递的
limits中的网络信息,以便在构建实例的NUMA拓扑时。
依赖项¶
无。numa-aware-live-migration需要支持具有任何CPU pinning和NUMA拓扑功能启用的实例的实时迁移。但是,鉴于目前所有NUMA用例的实时迁移都已损坏,因此缺乏对此特定NUMA用例的实时迁移支持不应被视为阻碍因素。
测试¶
与使用真实硬件的任何其他内容一样,这无法在上游CI中进行测试。相反,我们需要依赖单元测试、功能测试(硬件被模拟)以及下游或第三方CI来提供测试。
文档影响¶
该特性需要进行完整文档记录,不过我们可以免费获得配置文档(感谢 oslo_config.sphinxext)。
参考资料¶
历史¶
发布名称 |
描述 |
|---|---|
Rocky |
引入 |
