TripleO 分离控制平面与计算/存储支持¶
https://blueprints.launchpad.net/tripleo/+spec/split-controlplane
本文档介绍了一种部署模式的支持,在这种模式下,控制平面节点被部署,然后可以独立地添加计算/存储节点批次。
问题描述¶
目前 tripleo 在单个 heat 堆栈中部署所有服务,适用于所有角色(节点组)。这对于小型到中型部署来说效果很好,但对于非常大的环境,将节点批次分开是有益的,例如,在部署数百/数千个计算节点时。
当部署相对静态的控制平面,然后根据需求扩展添加计算节点批次时,可扩展性可以得到提高。每次扩展操作更新所有角色的所有节点开销很大,虽然通过从 heat 部署的服务器到配置下载和 ansible 的配置分离在一定程度上缓解了这个问题,但使模块化部署更容易,在需要将部署扩展到非常大的环境时是有益的。
降低风险 - 经常有请求避免在添加计算或存储容量时更新控制平面节点,模块化部署使这更容易实现,因为无需修改控制平面节点即可添加计算节点。
本文档无意涵盖实现模块化部署的所有可能方式,而是概述了需求并概述了我们需要考虑的接口,以实现这种灵活性。
提议的变更¶
概述¶
为了实现增量更改,我假设我们仍然可以通过现有架构部署控制平面节点,例如,Heat 部署节点/网络,然后我们使用配置下载通过 ansible 配置这些节点。
要部署计算节点,我们有几种选择
部署多个“仅计算”heat 堆栈,这将通过配置下载生成 ansible playbook,并使用来自控制平面堆栈的一些输出数据。
通过 mistral 部署其他节点,然后通过 ansible 配置它们(今天这仍然需要 heat 生成 playbook/inventory,即使它是一个临时堆栈)。
通过 ansible 部署节点,然后通过 ansible 配置它们(同样,使用我们今天可用的配置下载机制,我们需要 heat 生成配置数据)。
上述内容没有考虑“纯 ansible”解决方案,因为我们首先需要为所有可组合服务模板创建 ansible 角色等效项,而这项工作超出了本文档的范围。
范围和阶段¶
概述中列出的三项涵盖了一种增量方法,第一阶段是实现第一项。虽然此项增加了对 Heat 的额外依赖,但仅是为了允许使用现有功能来实现所需的功能。在未来的阶段,需要解决对 Heat 的任何额外依赖,并且在第一阶段所做的任何更改都应尽可能少,并侧重于 heat 堆栈之间的参数暴露。概述中其他项目的实施可能跨越多个 OpenStack 开发周期,并且可能需要在未来的规范中解决更多详细信息。
如果部署者能够执行以下简单场景,则此规范将作为更大功能的第 1 阶段实现
使用一个控制平面网络部署单个 undercloud
创建一个名为 overcloud-controllers 的 Heat 堆栈,其中包含 0 个计算节点
创建一个名为 overcloud-computes 的 Heat 堆栈,控制器可以使用它
使用控制器的 API 在从 overcloud-computes Heat 堆栈部署的计算节点上启动实例
在上述场景中,大部分工作涉及暴露 heat 堆栈之间的正确参数,以便控制节点能够像使用外部服务一样使用计算节点。这类似于 TripleO 提供模板,其中外部 Ceph 集群的属性可被 TripleO 用于配置使用外部 Ceph 集群的服务(如 Cinder)。
上述简单场景可以在没有网络隔离的情况下实现。在更复杂的 workload 站点与控制站点场景中,如以下部分所述,网络流量将不会通过控制器路由。如何管理该部署场景的网络方面需要在单独的规范中解决,并且总体工作量可能跨越多个 OpenStack 开发周期。
对于本文档涵盖的实施阶段,计算节点将在部署期间由 Ironic 通过与控制器节点相同的配置网络进行 PXE 启动。在这些计算节点上启动的实例可以连接到计算节点可以直接访问的提供程序网络。或者,这些计算节点可以部署为物理访问托管覆盖网络的网络。生成的 overcloud 应该与计算节点作为 overcloud Heat 堆栈的一部分部署的 overcloud 相同。因此,控制器和计算节点将运行它们通常运行的相同服务,无论部署是在两个 undercloud Heat 堆栈之间拆分。控制器和计算节点上的服务可以组合到多个服务器上,但确定组合的限制超出了第一阶段的范围。
示例用例场景:Workload 站点与控制站点¶
此功能的一个应用包括部署单独的 workload 站点和控制站点。控制站点提供管理和 OpenStack API 服务,例如 Nova API 和 Scheduler。Workload 站点提供 workload 仅需的资源,例如具有直接服务 workload 网络流量而不回路由到控制站点的可用区中的 Nova 计算资源。虽然在管理实例方面,控制站点和 workload 站点之间会有额外的延迟,但没有理由认为 workload 本身在运行后无法充分执行,并且每个 workload 站点将具有更小的足迹。
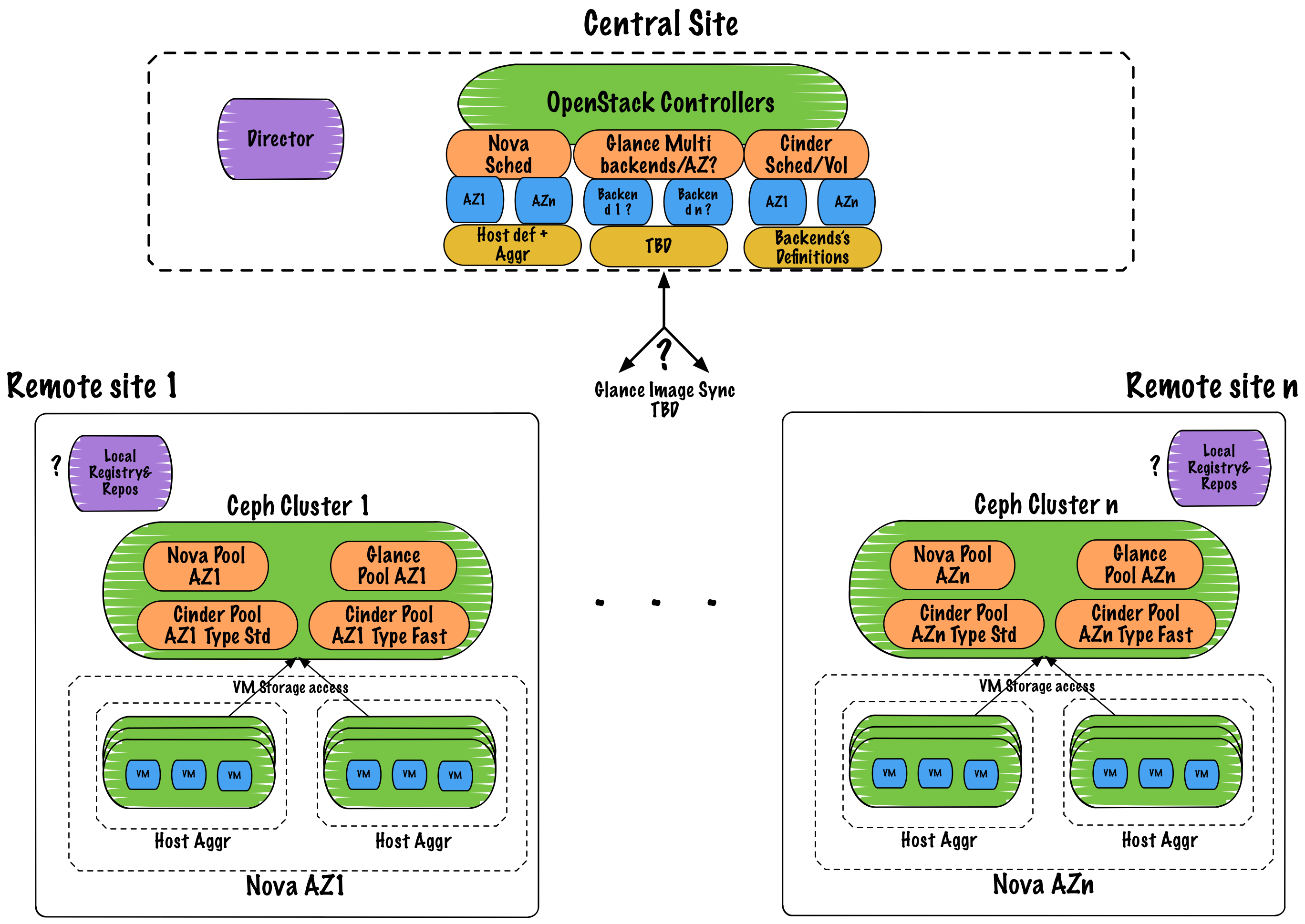
此场景包含在本规范中作为该功能的示例应用。本规范不旨在解决运行单独的控制站点和 workload 站点的所有细节,而只是描述提议的功能,部署独立的控制平面和计算节点,如何构建在 TripleO 中简化此类站点部署的未来版本。
替代方案¶
替代概述中概述的增量更改包括在 ansible 中重新实现服务配置,以便无需依赖现有的 heat+ansible 架构即可通过 playbook 配置节点。目前正在进行这项工作,例如将服务部署到 k8s 的 ansible 角色,但本规范主要关注找到一种临时解决方案,使我们当前的架构能够扩展到非常大的部署。
安全影响¶
诸如密码之类的潜在敏感数据需要在控制平面堆栈和仅计算部署之间共享。鉴于 undercloud 的仅管理员性质,我认为这没问题。
其他最终用户影响¶
用户将拥有更多灵活性和控制权,可以灵活地选择如何扩展其部署。这包括在示例用例场景中提到的单独的控制站点和 workload 站点。
性能影响¶
潜在地更好的可扩展性性能,尽管假设每次扩展都是串行化的,则总时间可能会增加。
其他部署者影响¶
无
开发人员影响¶
可以从一个 undercloud 部署多个 overcloud Heat 堆栈,但如果 TripleO 工具链的某些部分假设单个 Heat 堆栈,则可能需要更新它们。
实现¶
负责人¶
- 主要负责人
shardy
- 其他指派人
gfidente fultonj
工作项¶
概念验证,展示了如何使用已经着陆的补丁 [1] 和通过覆盖 EndpointMap 来部署独立的控制平面和计算节点
如果覆盖 EndpointMap 存在问题,请重新处理 all-nodes-config 以输出“所有节点”hieradata 和 vip 详细信息,以便它们可以跨堆栈使用
确定每个堆栈中缺少哪些数据,并提出补丁以将缺失的数据暴露给需要它的每个堆栈
修改概念验证以支持通过与控制器节点 heat 堆栈分离的 heat 堆栈添加单独的最小 ceph 集群(mon、mgr、osd)。
完善数据在每个堆栈之间共享的方式,以改善用户体验
更新文档以包含新部署方法的示例
回顾并编写后续规范,涵盖下一阶段所需的详细信息
依赖项¶
无。
测试¶
理想情况下,将执行可扩展性测试以验证这项工作可扩展性方面。对于第一阶段,将手动测试为启用“范围和阶段”下描述的简单场景所做的任何更改,并且现有的 CI 将确保它们不会破坏当前功能。后续阶段中实施的更改可以添加 CI 场景。
文档影响¶
部署文档需要更新,以涵盖拆分控制平面环境的配置。
