零停机重新索引¶
https://blueprints.launchpad.net/searchlight/+spec/zero-downtime-reindexing
此特性能够实现从 API 用户角度来看的无缝零停机资源数据重新索引。
问题描述¶
- 作为 searchlight API 的用户,我们期望以下特性
索引与源数据保持最新和一致
索引可用
我们不受 searchlight 服务更新和升级的影响
- 作为部署者,我们期望以下特性
我们可以推出服务升级并使用新数据更新索引
我们可以在不出现停机的情况下使索引恢复一致性
我们可以根据性能需求调整服务部署
我们可以轻松部署新的/修补的插件
我们可以更改数据映射并重新索引数据
背景¶
ElasticSearch 文档存储并索引到“索引”中(想象一下)。索引是一个逻辑命名空间,它指向主分片和副本分片,文档在这些分片中被复制。分片是单个 Apache Lucene 实例。分片分布在集群中的节点中。API 用户仅与索引交互,并且不暴露给内部机制,这些机制由 ElasticSearch 基于管理员的配置输入进行管理。
某些操作只能在索引创建时完成,例如更改分片数量、更改数据索引方式等。除了更改数据之外,重新填充与源服务数据失去一致性的索引,从头开始做比确定数据中的差异更容易。因此,数据和索引应该设计成可以随时重新索引,而不会中断 API 用户。重新索引发生在服务使用期间,仍然在 ElasticSearch 中索引新的文档。
在 Searchlight 0.1.0 中,我们允许每个插件通过 searchlight-api.conf 文件中的配置指定应存储数据的位置的索引。默认情况下,所有插件都将其数据存储在“searchlight”索引中。之所以选择这个作为起点,是因为资源实例数据的总索引数据量被认为在与小型部署的基于日志的索引相比非常小,但这可能因被索引的资源类型和部署规模而大相径庭。
重申一下,Searchlight 0.1.0 中的所有资源类型(插件或搜索)都将 ElasticSearch 索引硬编码在其中。这种硬编码功能阻止 Searchlight 在 ElasticSearch 中执行智能操作。直接向用户暴露索引通常不被用户社区或 ElasticSearch 推荐。相反,他们建议使用别名。API 用户可以使用别名与索引完全相同的方式,但可以更改别名以透明地指向不同的索引。这允许在索引之间无缝迁移,从而满足上述所有用例。
别名的概念在 ElasticSearch 指南 [1] 中有深入的描述。
提议的变更¶
有了这个蓝图,我们将使插件和搜索不再了解物理 ElasticSearch 索引。相反,我们将引入“资源类型组”的概念。资源类型组是 ElasticSearch 中作为一个单元处理的一组资源类型。所有 Searchlight 用户都将处理资源类型组,而不是像索引或别名这样的低级 ElasticSearch 细节。资源类型组将对应于由 Searchlight 创建和控制的 ElasticSearch 别名。
searchlight-api.conf 文件中的插件配置将不再指定索引名称。相反,插件将指定它选择成为成员的资源类型组。插件知道它属于哪个资源类型组很重要。当资源类型组的一个成员执行某些操作时,需要对组中的所有成员执行该操作。稍后会有更多细节。
现在用户已经移除了 ElasticSearch 的内部机制,我们可以处理零停机重新索引。基本思想是按需创建新的索引,填充它们,但以一种对 API 用户和 Searchlight 监听进程都透明的方式在 ElasticSearch 别名中使用实际使用的索引。
我们不会直接向 API 用户暴露别名。我们将使用资源类型映射来透明地将 API 请求定向到正确的别名。在实现此蓝图时,我们可能会选择仍然通过插件 API 暴露一个“索引”。暴露一个“索引”可能允许其他开源 ElasticSearch 库(基于索引)仍然可以工作。目前我们没有使用这些库中的任何一个,但我们可能不想排除将来使用它们。
Searchlight 内部将为每个资源类型组管理两个别名。注意:拥有这两个别名是实现零停机索引的关键变化。
API 别名
监听/同步别名
别名的名称将从配置文件中的资源类型组名称派生。具体如何处理将留给实现来决定。例如,我们可以将“-listener”和“/Sync”-search”附加到资源组类型名称,以获取这两个别名。
API 别名将指向单个“活动”索引,并且仅在索引完全准备好为 API 用户提供数据后才会切换。完全准备好意味着新索引是旧索引的超集。这允许透明地将传入请求切换到新索引,而不会中断 API 端用户。
监听别名将一次指向 1…* 个索引。监听只需知道它必须对提供的别名执行 CRUD 操作。监听一次更新多个索引的事实对监听来说是透明的。其好处是监听者不需要提供任何额外的管理 API,因为 ElasticSearch 会自动处理这些问题。
searchlight-manage index sync 的算法将更改为以下内容
在 ElasticSearch 中创建一个新的索引。任何索引映射更改现在都完成,在索引使用之前。
将新索引添加到监听者的别名。此时,监听者的别名指向多个索引。新索引现在“活动”并接收数据。监听者接收的任何数据都将发送到两个索引。
使用多个索引的别名存在一个问题 [2]。这个问题是这种情况是不允许的!在这种情况下,我们将捕获异常并在这一步中单独写入两个索引。有关详细信息,请参阅下面的“实现说明”子部分。
从与旧索引关联的每个资源类型到 ElasticSearch 中新索引的大量转储数据。
上述多个索引的问题也适用于此处。
- 以原子方式切换 API 别名以指向新索引。
我们将使用带有 remove/add 命令的 actions 命令在同一个 actions API 调用中。ElasticSearch 将其视为原子操作。[2]
{ "actions" : [ { "remove" : { ...} }, { "add" : " {...} } ] }从监听者的别名中删除旧索引。
从 ElasticSearch 中删除旧索引。我们不希望索引永远存在。我们可以弄清楚何时不再使用索引,然后删除它(异步任务、一种内部引用计数等)。如果这最终变得过于繁琐,我们可以重新考虑此操作。
- 注意事项
此算法假定我们可以处理乱序事件。有关详细信息,请参阅下文。
在重新同步过程中,监听者会将任何新的文档添加到两个索引中。
监听者将始终使与 API 别名关联的 ElasticSearch 索引保持最新。
在 API 别名切换后,监听者将使旧索引保持最新,以最大程度地减少任何竞争条件。
所有这些的一个关键方面是批量索引器和所有通知处理程序必须仅在拥有最新数据时才更新文档。这由一个单独的错误处理 [3]。此外,Searchlight 监听器和索引必须开始在已删除的文档中设置 TTL 字段,而不是立即删除它们。此功能在 ES 删除日志蓝图 [4] 中涵盖。
我们正在操作一个资源类型组作为一个整体。我们需要确保重新索引整个资源类型组,而不是组中的单个资源类型。例如,考虑资源类型组由 Glance 和 Nova 组成的情况。当 Searchlight 收到重新索引 Glance 的命令时,Searchlight 也需要重新索引 Nova。否则,新索引将不会包含以前的 Nova 对象。如果 Nova 没有重新索引,新索引将是不完整的。
CLI 必须支持手动 searchlight-manage 命令以及自动切换。例如
删除特定资源类型组的指定或当前索引/别名。
为指定的资源类型组创建一个新的索引。
完成时自动切换 API 和监听别名(默认 - 是)。
完成时自动删除旧索引(默认 - 是)。
提供一个状态命令,以便可以看到进度。* 按资源类型列出所有别名和索引及其状态 * 可以从 GUI 或单独的 CLI 并发使用以监视进度。
此更改会影响
列出插件的插件 API
API
监听器
批量索引器
CLI
图示示例¶
为了进一步阐明蓝图,我们将转向一系列图像并节省数千字。图像显示了 Searchlight 在一系列操作期间的状态。
对于此示例,我们有三种资源类型:Glance、Nova 和 Swift。有两个资源类型组。第一个组 RTG1 包含 Glance 和 Nova。与 RTG1 关联的两个别名是“RTG1-sync”,用于插件监听器,以及“RTG1-query”,用于插件搜索。第二个组 RTG2 包含 Swift。与 RTG2 关联的两个别名是“RTG2-sync”,用于插件监听器,以及“RTG2-query”,用于插件搜索。
图 1:初始状态
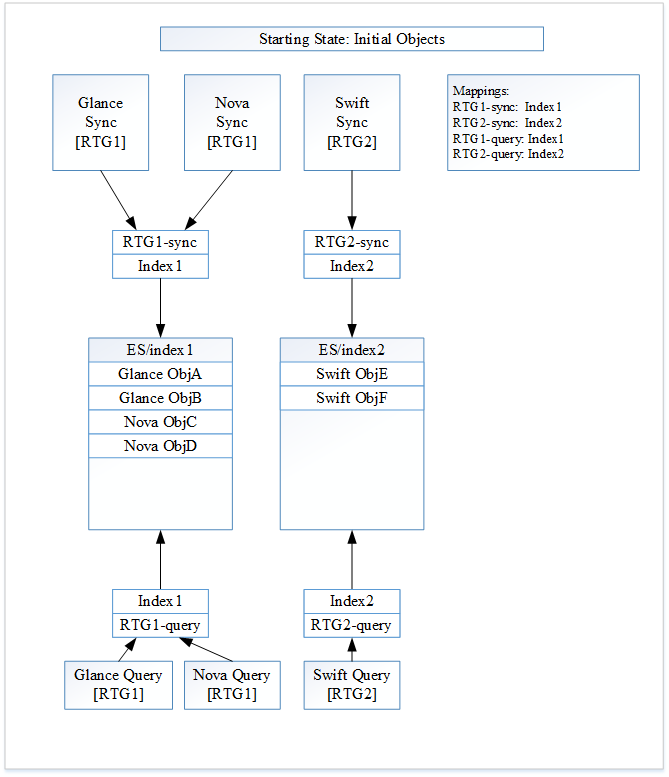
首先,Searchlight 将创建 ElasticSearch 索引“Index1”,供 RTG1 使用。ElasticSearch 别名“RTG1-sync”和“RTG1-query”被创建,并且都将与索引“index1”关联。接下来,Searchlight 将创建 ElasticSearch 索引“Index2”,供 RTG2 使用。ElasticSearch 别名“RTG2-sync”和“RTG2-query”被创建,并且都将与索引“Index2”关联。
Glance 现在创建了两个文档“Glance ObjA”和“Glance ObjB”。Nova 创建了两个文档“Nova ObjC”和“Nova ObjD”。这四个新文档对于第一个资源类型组现在已被索引。它们将被索引到别名“RTG1-sync”并最终进入索引“Index1”。
Swift 现在创建了两个新文档“Swift ObjE”和“Swift ObjF”。这两个新文档对于第二个资源类型组现在已被索引。它们将被索引到别名“RTG2-sync”并最终进入索引“Index2”。
图 1 显示了 Searchlight 的当前状态。
将针对“RTG1-query”进行 Glance 搜索。转到“Index1”,它将返回“Glance ObjA”、“Glance ObjB”、“Nova ObjC”和“Nova ObjD”。将针对“RTG2-query”进行 Swift 搜索。转到“index2”,它将返回“Swift ObjE”和“Swift ObjF”。
图 2:显式 Glance 重新同步
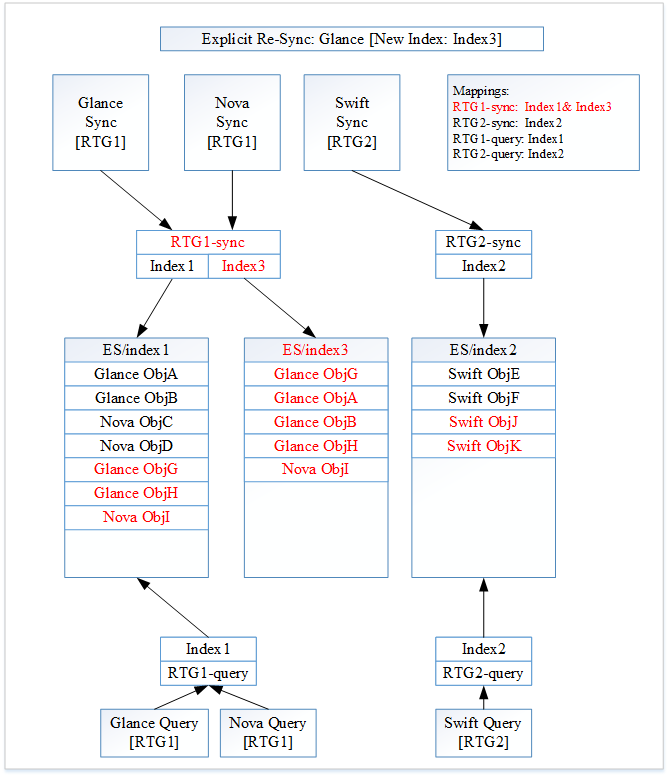
图像 1 中的所有更改都以红色突出显示。
Searchlight 收到 Glance 的重新索引命令。重新同步后,Glance 创建了两个新文档“Glance ObjG”和“Glance ObjH”。Nova 创建了一个新文档“Nova ObjI”。Swift 创建了两个新文档“Swift ObjJ”和“Swift ObjK”。
Searchlight 将创建一个新的 ElasticSearch 索引“Index3”。由于 Glance 正在重新同步,因此新索引与 RTG1 关联。Searchlight 现在将“Index1”和“Index3”都与别名“RTG1-sync”关联。由于新索引“Index3”尚未成为索引“Index1”的超集,因此我们现在不会更改 RTG1 搜索别名“RTG1-query”。它目前保持不变。
在 Glance 重新同步期间,以前的 Glance 文档“Glance ObjA”和“Glance ObjB”被索引到“Index3”。RTG1 的新文档(“Glance ObjG”、“Glance ObjH”和“Nova ObjI”)被索引到别名“RTG1-sync”。这些文档最终进入“Index1”和“Index3”。
RTG2 的新文档(“Swift ObjJ”和“Swift ObjK”)被索引到别名“RTG2-sync”。这些文档最终进入“Index2”。
图 2 显示了 Searchlight 的当前状态。
将针对“RTG1-query”进行 Glance 搜索。转到“Index1”,它将返回“Glance ObjA”、“Glance ObjB”、“Nova ObjC”、“Nova ObjD”、“Glance ObjG”、“Glance ObjH”和“Nova ObjI”。将针对“RTG2-query”进行 Swift 搜索。转到“index2”,它将返回“Swift ObjE”、“Swift ObjF”、“Swift ObjJ”和“Swift ObjK”。
此图显示了一个微妙的要点,即需要一起重新同步资源类型组中的所有资源类型,而不是仅仅重新索引组中的单个资源类型。例如,考虑资源类型组由 Glance 和 Nova 组成的情况。当 Searchlight 收到重新索引 Glance 的命令时,Searchlight 也需要重新索引 Nova。否则,新索引将不会包含以前的 Nova 对象: “Nova ObjC”和“Nova ObjD”。如果 Nova 没有重新索引,新索引将是不完整的。切换到此新索引时将是不完整的。
图 3:隐式 Nova 重新同步
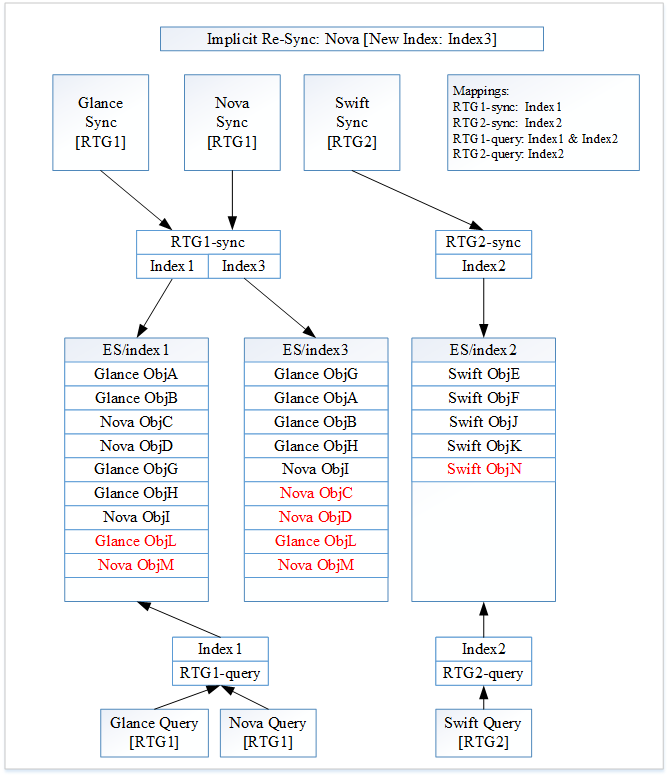
图像 2 中的所有更改都以红色突出显示。
Searchlight 启动了 Nova 的隐式重新同步,因为 Nova 是 RTG1 的成员。所有别名都已正确设置,因此不需要更改它们。重新同步后,Glance 创建了一个新文档“Glance ObjL”。Nova 创建了一个新文档“Nova ObjM”。Swift 创建了一个新文档“Swift ObjN”。
在 Nova 重新同步期间,以前的 Nova 文档“Nova ObjC”和“Nova ObjD”被索引到“Index3”。RTG1 的新文档(“Glance ObjL”和“Nova ObjM”)被索引到别名“RTG1-sync”。这些文档最终进入“Index1”和“Index3”。
RTG2 的新文档(“Swift ObjN”)被索引到别名“RTG2-sync”。此文档最终进入“Index2”。
Searchlight 尚未确认 Nova 重新同步完成。因此,“RTG1-query”尚未更新。
图 3 显示了 Searchlight 的当前状态。
将针对“RTG1-query”进行 Glance 搜索。转到“Index1”,它将返回“Glance ObjA”、“Glance ObjB”、“Nova ObjC”、“Nova ObjD”、“Glance ObjG”、“Glance ObjH”、“Nova ObjI”、“Glance ObjL”和“Nova ObjM”。将针对“RTG2-query”进行 Swift 搜索。转到“index2”,它将返回“Swift ObjE”、“Swift ObjF”、“Swift ObjJ”、“Swift ObjK”和“Swift ObjN”。
图 4:RTG1 重新同步完成
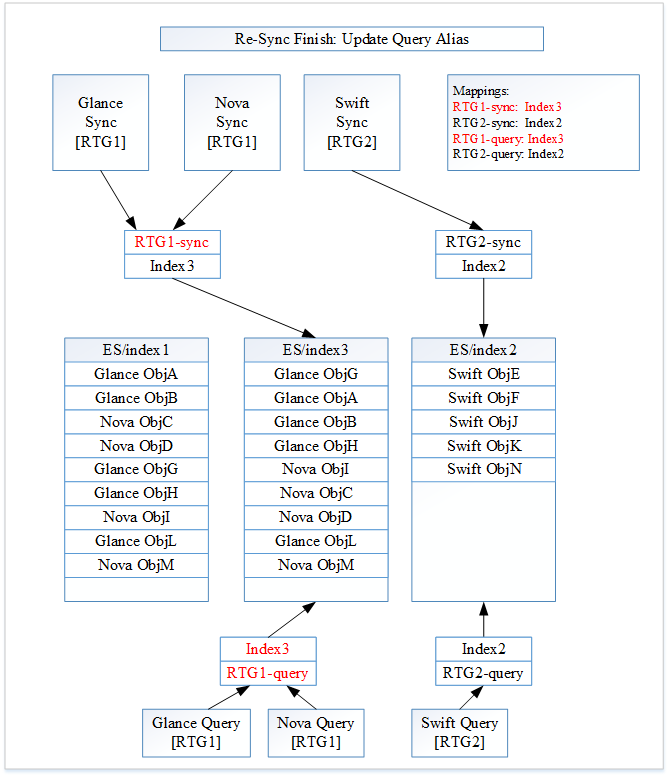
图像 3 中的所有更改都以红色突出显示。
RTG1 内的所有资源类型都已完成重新同步。Searchlight 现在将更新 RTG1 搜索别名“RTG1-query”。别名“RTG1-query”现在将与索引“Index3”关联。更新 RTG1 搜索别名后,Searchlight 将更新 RTG1 插件监听器别名“RTG1-sync”。别名“RTG1-sync”现在将与索引“Index3”关联。
别名更新需要按照这个顺序进行,以处理在修改别名时,新的 RTG1 文档被索引的边缘情况。如果我们首先修改 RTG1 插件监听器别名,那么新的文档将仅被索引到索引“Index3”。但是搜索仍然会访问索引“Index1”,从而遗漏新索引的文档。
图 4 显示了 Searchlight 的当前状态。
Glance 搜索将在“RTG1-query”上进行。访问“Index3”,它将返回“Glance ObjA”、“Glance ObjB”、“Nova ObjC”、“Nova ObjD”、“Glance ObjG”、“Glance ObjH”、“Nova ObjI”、“Glance ObjL”和“Nova ObjM”。Swift 搜索将在“RTG2-query”上进行。访问“index2”,它将返回“Swift ObjE”、“Swift ObjF”、“Swift ObjJ”、“Swift ObjK”和“Swift ObjN”。
Searchlight 的内部状态是正确的、连贯的,并且已准备好继续。在未来某个时间,我们将能够完全删除 Index1。
实现说明¶
实现说明 #1:多个索引¶
仔细查看 ES 别名文档 [2] 后,有一个警告隐藏在其中:“索引到指向多个索引的别名是一个错误。” 糟糕。现在,将额外索引添加到别名并让重新索引顺利进行,这种简单的解决方案将不起作用。ElasticSearch 将抛出“ElasticsearchIllegalArgument”异常并返回 400(错误请求)。
插件需要意识到这个异常并做出反应。通过实验,ElasticSearch 将返回此错误
{"error":"ElasticsearchIllegalArgumentException[Alias [test-alias] has more than one indices associated with it [[test-2, test-1]], can't execute a single index op]","status":400}
从这个错误消息中,我们获得了实际的索引。提取索引名称后,插件将能够完成任务。插件现在将迭代每个实际索引进行索引,而不是使用别名。这种情况仅适用于别名中存在多个索引的情况(即重新同步的情况)。在不重新同步时,插件将不会收到此异常。
我们需要在解析错误消息时小心。如果错误消息发生变化,这可能是一个危险的区域。捕获异常和解析消息应该尽可能灵活。
实现说明 #2:不兼容的更改¶
需要解决触发重新索引的逻辑中的一个边缘情况。有时索引之间发生了不兼容的更改。例如,添加了一个新的插件,或者服务的文档以不兼容的方式更改了(不同的 ElasticSearch 映射)。在任何这些情况下,我们需要能够处理这些更改并无缝地推出它们。
- 处理这些情况的一些可能选项包括
禁用对旧索引的重新索引。
运行两个监听器,一个理解旧索引,另一个理解新索引。
备选方案¶
方案 #1¶
一个替代的使用场景如下所示
对 v1/search/plugins 的查询将更改为,为每种类型列出的索引实际上是别名(API 用户不知道这一点)。
searchlight-manage index sync CLI 将更改为支持以下功能
重新索引当前索引,而不迁移别名(与 0.1.0 无变化)。
删除特定类型或当前索引。
- 为指定的资源类型创建一个新索引。
使用后缀编号模式指定名称或自动生成名称。
联系并停止所有监听器,停止处理指定类型的传入通知。
完成时自动切换别名(默认 - 否?)。
完成时自动删除旧索引(默认 - 否?)。
联系并启动所有监听器,处理指定类型的传入通知。
按需将别名切换到新索引。
以上所有内容都必须考虑单个别名中的 1 … * 索引。
所有监听器进程现在必须支持一个管理 API,以便它们能够停止处理指定资源类型的通知。没有此功能,在填充新索引时将仍然存在竞争条件。例如,如果填充所有 Nova 服务器实例需要 N 秒,那么从向 Nova 发送数据请求到数据更新之间将存在时间延迟。因此,在填充新索引时应禁用通知,然后在重新启用。
方案 #2¶
此方案探讨了一种避免“在索引时别名中存在多个索引”异常的方法,如“实现说明”子部分所述。
想法是,与其在 Sync 别名中拥有两个索引,在搜索别名中拥有一个索引,不如反转别名中的索引使用情况。现在我们考虑在将多个索引添加到搜索别名时,只将一个索引保留在 sync 别名中。
当我们启动重新同步时,我们创建一个新索引。我们将 sync 别名更新为指向此新索引,替换旧索引。由于 sync 别名中只有一个索引,我们不会收到 ElasticsearchIllegalArgument 异常。我们还将新索引添加到搜索别名。
此时,搜索别名仅包含新索引,而搜索别名包含旧索引和新索引。当发生搜索时,它将找到旧文档以及任何新文档。
此替代方案的主要问题是,在重新同步期间,搜索将找到许多重复项。旧索引中的所有文档最终都将被添加到新索引中。为了可用,我们需要找到一种过滤掉这些重复项的方法。对过滤想法的初步调查导致被认为过于脆弱和容易出错的解决方案。因此,这个想法被包含在替代方案的底部。
未来增强¶
优化
使用 ElasticSearch 索引同步功能,而不是让每个资源类型执行手动重新索引。ElasticSearch 没有本地重新同步命令,但可以使用“scan and scroll”和 ElasticSearch Bulk API 来实现。 [5] 需要仔细考虑此优化。只有当我们绝对确定旧 ElasticSearch 索引是连贯且完整的时,才会执行此操作。
参考资料¶
- [1] 别名的概念在此处进行了深入描述
https://elastic.ac.cn/guide/en/elasticsearch/guide/current/index-aliases.html
- [2] ES 如何处理别名在此处描述
https://elastic.ac.cn/guide/en/elasticsearch/reference/1.7/indices-aliases.html
- [3] 所有 searchlight 索引更新都应在更新任何文档之前确保最新
- [4] ES 删除日志蓝图
https://blueprints.launchpad.net/searchlight/+spec/es-deletion-journal
- [5] ES scan and scroll 在此处讨论
https://elastic.ac.cn/guide/en/elasticsearch/reference/current/search-request-scroll.html ES Bulk API 在此处讨论: https://elastic.ac.cn/guide/en/elasticsearch/reference/current/docs-bulk.html
