This work is licensed under a Creative Commons Attribution 3.0
Unported License.
http://creativecommons.org/licenses/by/3.0/legalcode
容器分片¶
包含你的蓝图的 URL
https://blueprints.launchpad.net/swift/+spec/container-sharding
swift 当前的一个限制是容器数据库。SQLite 数据库存储容器内所有对象的名字。随着容器中对象数量的增长,数据库文件的大小也会增长。这会导致更高的延迟,因为文件大小和对单个文件的读取,可以通过使用容器分片来改进。
在过去一年中,已经涵盖了一些 POC,最新的 POC 使用分布式前缀树,虽然效果很好(保持顺序和添加无限分片),但在上次黑客马拉松(奥斯汀八月)上,发现它需要太多的请求。在较小或负载不高的集群中,这可能没问题,但与运行高负载集群的用户交谈,这种方法只会增加他们的问题。此方法的代码可以在 https://github.com/matthewoliver/swift/ 的 sharding_trie 分支中找到。
在黑客马拉松上的讨论之后,我们决定尝试一种类似但更简单的方法。我称之为枢轴范围方法。这个 POC 正在 sharding_range 分支上进行。
https://github.com/matthewoliver/swift/tree/sharding_range
问题描述¶
用于表示容器的 SQLite 数据库存储容器中包含的所有对象的名字。随着容器中对象数量的增长,数据库文件的大小也会增长。由于这种行为,当前对于存储大量对象在单个容器中的集群的建议是确保容器数据库存储在 SSD 上,以减少访问大型数据库文件的延迟。
在之前版本的规范中,我研究了我们可以用来分片容器的不同方法。这些是
- 路径哈希(部分幂)
- 一致哈希环
- 分布式前缀树(trie)
- 枢轴/分割树(枢轴范围)
在 SFO Swift 黑客马拉松上关于 SPEC 的讨论中,分布式前缀树(trie)成为领先者。最近在奥斯汀黑客马拉松上,前缀 trie 方法虽然有效,但会导致更多的请求,并且在更大的高负载集群上,实际上可能会导致比解决的问题更多的问题。决定尝试一种类似但简化的方法,我称之为枢轴(或分割)树方法。这个版本的规范将涵盖这个内容。
当我们谈论分割容器中的对象时,我们只是谈论容器元数据,而不是对象本身。
基本思想¶
基本且简化的想法很简单。首先,要启用容器分片,请通过 PUT 或 POST 传入一个“X-Container-Sharding: On” X-Header
curl -i -H 'X-Auth-Token: <token>' -H 'X-Container-Sharding: On' <url>/<account>/<container> -X PUT
一旦启用,当容器变得太满时,比如达到 100 万个对象。找到一个枢轴点(中间项),这将用于分割容器。此分割将创建 2 个额外的容器,每个容器包含 1/2 的对象。配置参数 shard_container_size 确定容器在被分片之前可以达到的大小(默认为 100 万)。
所有在分割时创建的新容器都存在于基于用户帐户的单独帐户命名空间中。这意味着用户只会看到 1 个容器,我们称之为根容器。分片后的命名空间是
.sharded_<account>/
已被分割的容器不再持有对象元数据,因此一旦新容器变得持久,就可以删除它们(除了根容器)。根容器,像任何其他分割容器一样,在其对象表中,但是它有一个新的表来存储枢轴/范围信息。可以使用此信息轻松快速地确定元数据应该位于何处。
枢轴(分割)树、范围和 Swift 分片¶
我们在选择分片技术时的一个决定性因素是保持一致的顺序很重要,前缀树是一个好的解决方案,但我们需要更简单的方法。从概念上讲,我们可以将容器在对象列表中的枢轴点(中间对象)上分成两部分,将结果前缀树变成更基本的二叉树。在这个新 POC 的初始版本中,我们有一个名为 PivotTree 的类,这是一个具有我们需要的额外智能的二叉树。但随着开发进行,维护完整的树变得更加复杂,我们只存储枢轴节点(为了节省空间)。确定属于树的一部分的边界(用于错位对象检查,见下文)变得相当复杂。我们后来决定再次简化设计并存储一个范围列表(像百科全书一样),它仍然像二叉树一样表现(搜索算法),但也大大简化了 Swift 中的分片部分。
pivot_tree 版本仍然存在(虽然不完整)在 pivot_tree 分支中。
枢轴树与枢轴范围¶
让我们从一张图片开始,这就是枢轴树的工作方式
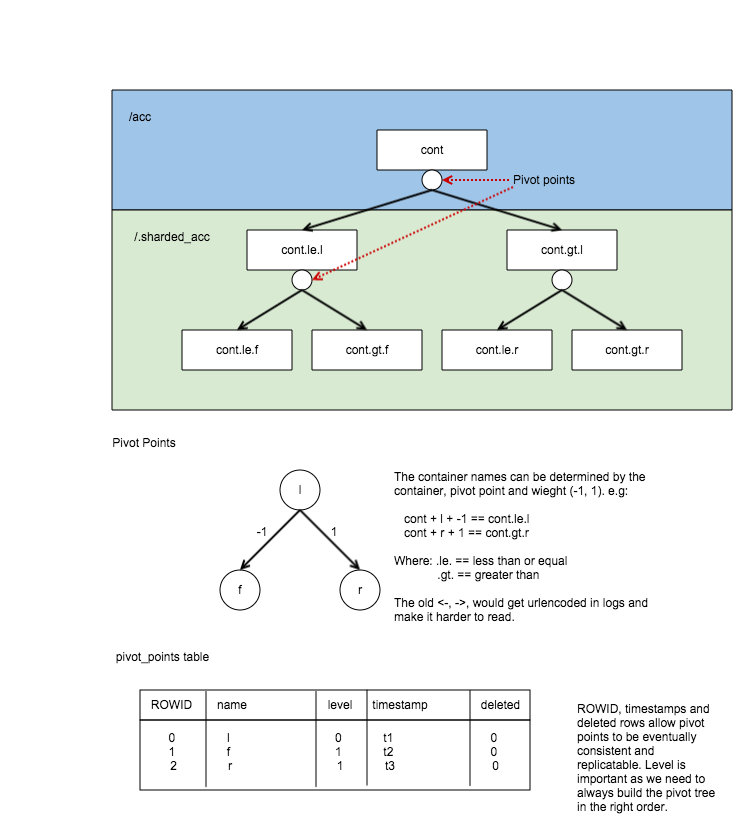
这里,容器下方的圆圈代表容器枢轴的点,因此你可以看到枢轴树。
这张图片是我在上次规范中使用的,也演示了分片容器的命名方式以及它们在 DB 中的存储方式。
查看pivot_points来自上图的表,你可以看到原始容器‘/acc/cont’已被分割了几次
- 首先,它在‘l’处枢轴,这将创建 2 个新的分片容器(cont.le.l 和 cont.gt.l)。
- 其次,容器 /.sharded_acc/cont.le.l 在枢轴‘f’处分割,创建 cont.le.f 和 cont.gt.f。
- 最后,cont.gt.l 容器也分割在‘r’处枢轴,创建 cont.le.r 和 cont.gt.r。
由于它本质上是一棵二叉树,我们可以仅使用枢轴表中的 3 个枢轴推断这额外的 6 个容器的存在。枢轴树的级别也存储在枢轴中,以便我们确保在需要时正确构建树。
树在数据库中存储的方式基本上是一个列表,并且需要构建树。在范围方法中,我们只是使用一个范围列表。引入了一个相当简单的 PivotRange 类,它具有使范围搜索和二叉搜索算法简单的各种方法。
这是相同数据存储在 PivotRanges 中的示例
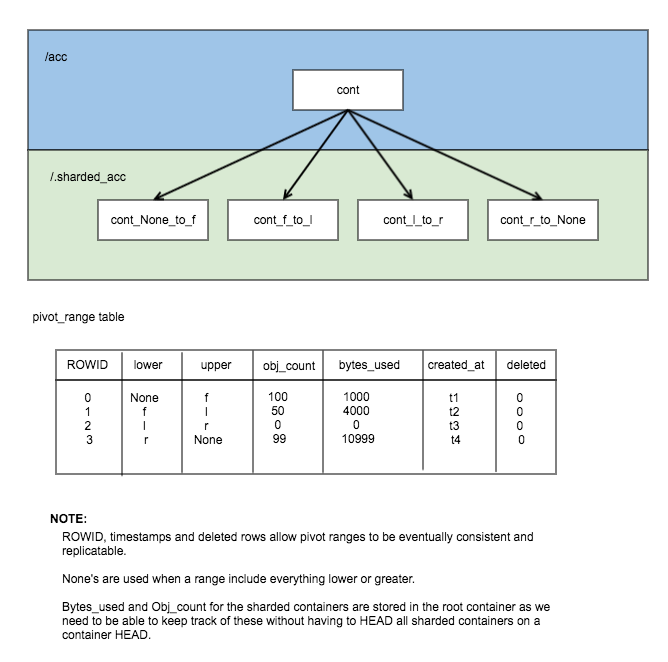
如你从这个图中看到的,表中的记录更多,但它得到了简化。
数据库中存储的 bytes_used 和 object_count 看起来可能令人困惑,但这是为了让我们跟踪这些统计信息在根容器中,而无需访问每个节点。容器分片器将在访问容器时更新这些统计信息。这使分片容器的统计信息略微正确并最终一致。
所有用户和系统元数据仅存储在根容器中。分片容器仅持有帮助分片器完成其工作并能够审计容器的一些元数据
- X-Container-Sysmeta-Shard-Account - 这是原始帐户。
- X-Container-Sysmeta-Shard-Container - 这是原始容器。
- X-Container-Sysmeta-Shard-Lower - 此容器的范围下限。
- X-Container-Sysmeta-Shard-Upper - 此容器的范围上限。
枢轴点¶
枢轴点是容器中的中间对象。由于 Swift 最终是一致的,所有容器都可能处于变化中,因此它们可能没有相同的枢轴点来分割。因此,需要某物做出决定。在 POC 的初始版本中,这将是容器分片器的工作之一。而且这样做很简单。它将查询容器的每个主副本,询问他们认为枢轴点是什么。分片器将选择具有最多对象的容器(它将如何做到这一点将在容器分片器部分中详细说明)。
container/backend.py 中有一个新方法get_possible_pivot_point它执行你所期望的,通过使用查询数据库来查找容器的枢轴点
SELECT name
FROM object
WHERE deleted=0 LIMIT 1 OFFSET (
SELECT reported_object_count / 2
FROM container_info);
此枢轴点放置在 container_info 中,因此现在可以轻松访问。
PivotRange 类¶
现在我们正在存储一个范围列表,并且如你可能从初始图片中记得的那样,我们只存储该范围的下限和上限。我们有一个使处理范围变得简单的类。
该类非常基本,它存储时间戳、下限和上限。为了对字符串或另一个 PivotRange 进行检查,_contains_、_lt_、_gt_ 和 _eq_ 已被覆盖。
该类还包含一些额外的辅助方法
- newer(other) - 是否比另一个范围更新。
- overlaps(other) - 此范围是否与另一个范围重叠。
PivotRange 类位于 swift.common.utils 中,并且那里还有一些其他辅助方法
- find_pivot_range(item, ranges) - 找到一个项目属于范围列表中的哪个范围。
- pivot_to_pivot_container(account, container, lower=None, upper=None, pivot_range=None) - 给定根容器帐户和容器以及下限和上限或只是一个 pivot_range,生成所需的分片名称。
获取 PivotRanges¶
有两种获取 PivotRanges 列表的方法,这取决于你在 swift 中的位置。最简单和最明显的方法是使用 ContainerBroker 中的一个新方法 build_pivot_ranges()。
第二个是要求容器提供一个枢轴节点列表,而不是对象。这是通过向容器服务器发送一个简单的 GET 请求,并发送 nodes=pivot 参数来完成的
GET /acc/cont?nodes=pivot&format=json
然后你可以构建一个 PivotRange 对象列表。可以在 _get_pivot_ranges 方法中看到如何执行此操作,该方法位于容器分片器守护程序中。
对对象路径的影响¶
代理¶
就代理而言,没有任何变化。对象将始终使用根容器进行哈希,因此不需要移动对象数据。
对象服务器和对象更新器¶
对象服务器和对象更新器(async-pending)需要一些额外的智能,因为它们需要更新正确的分片。在当前的 POC 实现中,这些守护程序实际上不需要了解分片,它们只需要知道如何处理容器服务器响应 HTTPMovedPermanently(301)的情况,如下面的图片所示
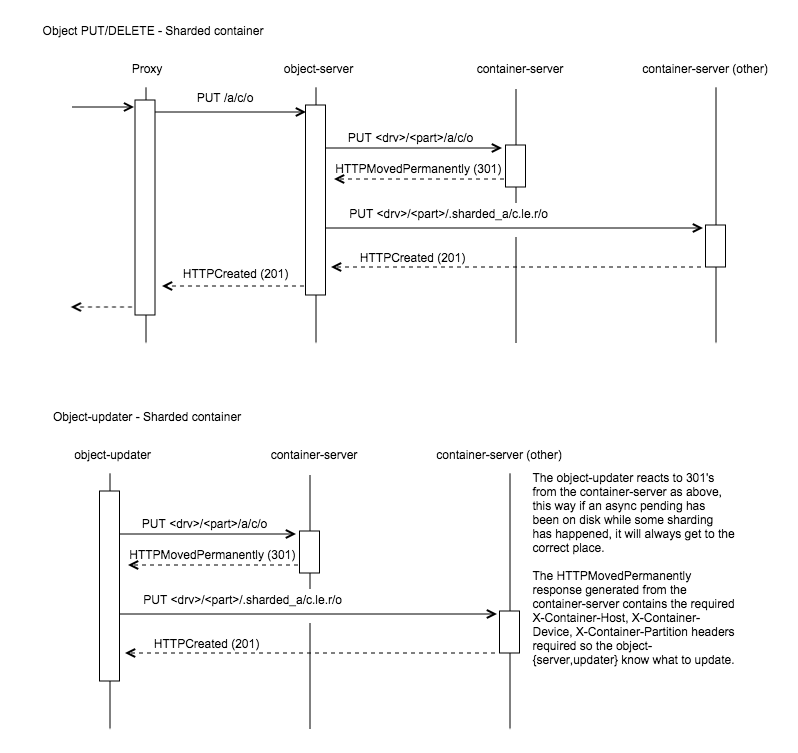
这是通过让容器服务器在响应中设置对象服务器和对象更新器所需的 X-Container-{Host, Device, Partition} 标头来实现的。只有添加了一个新的主机到标头中,容器服务器通过选择位于与自身相同索引的新的分区的主节点来确定哪个主机。这有助于阻止我称之为请求风暴的情况。
对容器路径的影响¶
PUT/POST¶
这些不受影响。所有容器元数据都将存储在根容器中。
GET/HEAD¶
GET 和 HEAD 变得更加复杂。HEAD 需要返回容器上的 bytes_used 和 object_count 统计信息。根容器没有任何对象,因此我们需要
- 访问每个分片节点并构建统计信息...这非常昂贵;或者
- 建立一种定期更新统计信息的机制,并且它们可以滞后一点。
选择了后者,POC 将每个分片的统计信息存储在根 pivot_ranges 表中,该表将在每次分片传递期间更新(见下文)。
在 GET 上,需要额外的请求来命中叶节点以收集和构建对象列表。我们可以在代理或容器服务器上进行这些额外的请求,两者都有其优点和缺点
在代理
- 优点:这具有从代理发出新请求的优势,能够探测和构建响应。
- 缺点:需要将根容器的枢轴树(或仅叶子)传回代理。由于这棵树可能会增长,即使只传回叶子,也需要将树放在主体中(如使用分布式前缀树的最后一个 POC 实现的那样)或在多个标头中。
- 缺点:代理需要合并从命中的容器服务器的响应,这意味着需要理解 XML 和 json。虽然可以通过调用 format=json 并将容器服务器的 create_listing 方法移动到更全局的东西(如 utils)来解决这个问题。
在容器服务器
- 优点:无需将根容器的枢轴节点(或仅叶子)传递,因为所有操作都将发生在访问根容器的代理的情况下。
- 优点:在容器服务器上发生意味着我们可以对分片容器调用 format=json,然后使用根容器的 create_listing 方法来干净地处理任何格式。
- 缺点:由于发生在容器服务器上,需要注意请求。我们不想在访问每个叶容器时发送额外的副本请求。否则,我们可能会产生一种请求风暴。
POC 当前正在使用容器服务器,使代理保持分片感知自由(这很酷)。
DELETE¶
Delete 具有与 GET/HEAD 相同的选项,它可以在代理或容器服务器上运行。但一般思路是
- 收到一个 DELETE 请求
- 在应用到根容器之前,先应用到分片。
- 如果全部成功,则删除根容器。
容器删除尚未在 POC 中实现。
代理基础控制器有很多很棒的代码来处理法定数量和最佳响应,如果我们把 DELETE 代码放在容器中,我们需要复制它或者进行重大重构。这不太好,但可能是最好的选择。
另一方面,在代理中拥有分片 DELETE 代码会使代理意识到分片……这不太酷……但绝对会使删除代码_更_简单。
所以问题是: 分片删除代码应该放在哪里?
复制器变更¶
容器复制器(以及根据需要 db_replicator)已更新,以复制和同步 pivot_range 表。
Swift 最终一致性,这意味着在某个时刻,我们将拥有一个未分片的容器副本与一个已分片的容器副本,并且由于最终一致性,未分片容器中的某些对象可能实际存在,需要合并到较低分片中。目前的想法是,一个分片容器在其叶子节点中保存所有对象。使根容器和分支容器的对象表为空,这些非叶子节点也不会在对象列表时被查询。所以计划是
- 将未分片容器中的对象同步到根/分支容器的对象表中。
- 让容器分片器将对象复制到正确的分片。(注意,处理分片中的错位对象是分片器的任务)
待处理和合并项¶
POC 的这个版本将利用上一个 POC 的复制变更。至少在 POC 期间,它们是足够的。container/backend.py 中的 merge_items 方法已被修改为意识到 pivot_points。也就是说,传递给它的项目列表现在可以包含对象和 pivot_nodes 的混合。将在待处理/pickle 文件格式中添加一个新标志,称为 record_type,在解 pickle 现有 pickle/pending 文件时默认为 RECORD_TYPE_OBJECT。Merge_items 将根据 record_type 将其排序为 2 个不同的列表,然后相应地插入、更新、删除所需的表。
TODO - 更详细地解释这一点,也许添加一个或两个图表。
容器复制变更¶
由于 Swift 是一个最终一致性系统,我们需要确保在复制容器数据库时,这不仅复制对象表中的项目,还复制 pivot_points 表中的节点。大多数数据库复制代码是 db_replicator 的一部分,它是帐户和容器复制的父类,因此是共享的。POC 中的当前解决方案是添加一个 _other_items_hook(broker) 钩子,该钩子在容器复制器中被覆盖,以从 pivot_range 表中获取项目,并以 items 格式返回,以便传递到 merge_items。
但是有一个注意事项,那就是当前钩子会从 pivot_points 表中获取所有对象。没有指针/同步点。pivot_point 的数量应该保持相对较小,至少与对象数量相比是这样。
注意
我们正在使用 other_items 钩子,但这可能会改变,一旦我们开始分片帐户。在这种情况下,我们可以简单地更新 db_replicator 以正确地复制范围列表。
容器分片器¶
容器分片器将在所有容器服务器节点上运行。在一段时间后,它将解析所有共享容器,在每个容器上
- 审计容器
- 处理任何错位项目。也就是说,应该属于不同范围容器的项目。
- 然后我们检查容器的大小,当我们执行以下_之一_时
- 如果容器足够大并且尚未定义 pivot 点,则确定一个 pivot 点。
- 如果容器足够大并且已定义 pivot 点,则对其进行拆分(pivot)。
- 如果容器足够小(稍后章节),则它将缩小。
- 如果容器不太大或太小,则保持不变。
- 最后,容器的 object_count 和 bytes_used 将发送到根容器的 pivot_ranges 表。
如上所述,分片是一个两阶段过程,在第一次分片传递中,容器将获得一个 pivot 点,下次传递时将被分片(拆分)。缩小甚至更复杂,这也是一个两阶段过程,但我不想在这里使这个初步介绍过于复杂。有关更多详细信息,请参阅下面的缩小部分。
审计¶
分片器将执行基本的审计,只需确保当前分片的范围存在于根的 pivot_ranges 表中。如果它是根容器,则检查是否存在任何重叠或缺失的范围。
以下真值表来自旧的 POC 规范。我们需要更新它。
根引用 父引用 结果 no no 隔离容器 是 no 修复父引用 no 是 修复根引用 是 是 容器没问题
错位对象¶
错位对象是指位于错误分片中的对象。如果它是分支分片(已拆分的分片),则对象表中的任何内容都是错位的,需要处理。在叶子节点上,只需一个快速的 SQL 语句就可以找到所有位于 pivot 的错误一侧的对象。现在我们使用范围,很容易确定应该和不应该在范围内的对象。
分片器使用容器协调器/复制器的创建本地手递交分区数据库、加载它,然后使用复制将其推送到需要去的地方的方法。
拆分(增长)¶
为了简单起见,POC 使用分片器来确定和拆分。它以一个我已经提到过的两阶段过程来完成。在每次分片传递中,都会检查本地到此容器服务器的所有分片容器。在每次检查中,都会审计容器并处理任何错位项目。完成后,只有以下_之一_操作发生,然后分片器移动到下一个容器或完成其传递
- 阶段 1 - 确定 pivot 点:如果容器中的对象足够多,足以保证拆分并且尚未确定 pivot 点,那么我们需要找到一个,它通过
- 首先找到本地容器认为的最佳 pivot 点及其对象计数(它可以从 broker.get_info 获取这些信息)。
- 然后查询其他主节点以获取他们最佳的 pivot 点和对象计数。
- 我们比较结果,对象最多的容器获胜,如果平局,则首先报告获胜对象计数的容器获胜。
- 在本地和所有节点上将 X-Container-Sysmeta-Shard-Pivot 设置为获胜的 pivot 点。
- 阶段 2 - 在 pivot 点上拆分容器:如果存在 X-Container-Sysmeta-Shard-Pivot,那么我们
- 在提交拆分之前,询问其他主节点并确保达到法定数量(replica / 2 + 1),他们同意相同的 pivot 点。
- 如果我们达到法定数量,那么就可以安全地拆分。在这种情况下,我们
- 本地创建新容器
- 填充它们,同时本地删除对象
- 复制所有容器并更新根容器的更改。(删除旧范围,并添加 2 个新范围)。
注意
在拆分容器时删除对象时使用的 timestamp 与现有对象相同,但使用 Timestamp.internal 偏移量递增。允许较新的对象/元数据版本不被压制。注意这一点,以防它与 fast post 工作 acoles 正在进行的工作冲突……我将在峰会上问他。
- 什么都不做。
缩小¶
事实证明,缩小(当它们变得太小时将容器合并回去)比分片(增长)更复杂。
在分片时,我们至少拥有所有需要分片的对象都在我们所在的容器服务器上。在缩小的时候,我们需要找到一个范围邻居,它很可能位于其他地方。
所以 POC 当前做什么?目前它是另一个两阶段过程。虽然在编写此 SPEC 更新时,我认为这可能需要成为一个三阶段过程,因为我们可能需要一个初始状态来让 Swift 知道某事将要发生。
那么缩小是如何工作的,很高兴你问。首先,缩小发生在分片传递循环期间。如果容器的项目太少,那么分片器将查看是否可以缩小容器。这从阶段 1 开始
- 阶段 1:
- 确定容器是否真的有足够少的对象,即达到阈值以下(见下文)的法定数量。
- 检查邻居,看看是否可以缩小/合并在一起,这同样需要获得法定数量。
- 如果可能,与最小的邻居合并。
- 本地创建一个新的范围容器。
- 设置两个容器上的一些特殊元数据。
- X-Container-Sysmeta-Shard-Full: <邻居>
- X-Container-Sysmeta-Shard-Empty: <此容器>
- 将对象合并到元数据完整容器(邻居)中,更新本地容器。
- 复制并更新根容器的范围表。
- 让错位对象和复制来完成剩下的工作。
- 阶段 2 - 在另一个邻居所在的存储节点上(完整容器),当分片器击中它时
- 获得法定数量,元数据仍然是它所说的……虽然如果不是,可能为时已晚)。
- 在手递交分区中本地创建一个新容器。
- 用所有数据加载(因为我们想正确地命名容器),同时本地删除)。
- 将范围更新发送到根容器。
- 删除两个旧容器并复制所有三个容器。
我看到的潜在额外阶段可能很重要,那就是仅将元数据设置为阶段 1,让 Swift 的其余部分知道某事将要发生。设置的元数据是 Swift 在需要缩小感知区域中检查的内容。
足够小¶
好的,这些都很好,但是容器和足够小的邻居有多小?
缩小已在容器分片器配置部分添加了 2 个新的配置参数
- shard_shrink_point - shard_container_size(默认 1 百万)的百分比,容器被认为足够小可以尝试缩小。默认值为 50(注意没有 % 符号)。
- shard_shrink_merge_point - shard_container_size 的百分比,在合并 2 个容器后容器需要低于此值。默认值为 75。
这些只是我从空气中挑选的数字。但是可以调整。想法是,采用默认值,当容器小于 shard_container_size 的 50% 时,分片器将查看是否有任何邻居,当其对象计数加到自身时小于 shard_container_size 的 75%,然后与它合并。如果找不到对象计数加到自身小于 75% 的邻居,那么我们无法缩小,容器将保持原样。
分片感知¶
新的问题是现在需要缩小感知。否则,我们可能会陷入困境
- 容器 GET - 需要知道它是否击中了一个缩小 empty 容器,以查看缩小 full 容器中的空容器的元数据。
- 分片或缩小不应触碰处于缩小状态的容器。也就是说,它是空容器或完整容器。
- 分片器的错位对象 - 缩小完整容器显然看起来像它有很多不属于范围的对象,因此错位对象需要了解这种状态,否则我们会有一些问题。
- 容器服务器 301 重定向 - 我们需要确保在找到 301 响应中要更新的所需容器时,如果它碰巧是一个空容器,我们需要重定向到完整容器。(或者我们不这样做,也许这无关紧要?)。
- 容器分片删除 - 空容器现在没有对象,可以删除。当我们删除容器时,所有元数据都会丢失,包括空和完整元数据……这可能会导致一些有趣的问题。(这尚未实现,请参阅删除问题)
分片的空间成本或真空¶
当我们拆分时,当前我们
- 在手递交分区中本地创建 2 个新容器。
- 将对象拆分到新容器中,同时保留其时间戳。同时通过将 deleted 设置为 1 并将时间戳设置为对象时间戳 + 偏移量来删除正在拆分的容器中的对象。
- 复制所有三个容器。
注意
也许一个好的妥协是,而不是拆分并完全填充 2 个新容器然后复制,也许更聪明的方法是创建新容器,填充它们一点(shard_max_size),然后复制,冲洗,重复。
我们将 deleted = 1 时间戳设置为现有对象的时间戳 + 偏移量,因为可能有一个容器在那里与更新的对象记录不同步,我们想保留它。在这种情况下,它将覆盖拆分容器中的已删除对象,然后通过分片器的错位项目方法移动到新的分片容器。
我们在这里遇到的问题是,这意味着分片容器,尤其是非常大的容器,会占用_很多_磁盘空间。要分片一个容器,我们需要由于将对象插入到新容器中_并且_它们仍然存在于原始容器中并设置了 deleted 标志,因此需要将磁盘上的大小翻倍。
我们要么接受这个限制……要么尝试在分片时将磁盘上的大小降至最低。另一个选择是
- 在手递交分区中本地创建 2 个新容器。
- 将对象拆分到新容器中,同时保留其时间戳。同时删除原始对象(DELETE FROM)。
- 复制所有三个容器。
在这里,在第二个选项中,我们可能需要试验多久需要进行一次清理,否则即使我们使用 DELETE FROM,磁盘上的数据库大小仍有可能保持不变。此外,在这种情况下,旧容器与过时的副本同步,意味着所有在过时容器中的对象将被合并到旧(分割)容器中,所有这些都需要在合并项中进行修正。这也可能代价很高。
分片容器统计信息¶
正如您所料,如果我们简单地对根容器执行 HEAD 操作,bytes_used 和 object_count 统计信息将返回 0。这是因为在分片后,根容器在其对象表中没有任何对象,它们已经被分片移走了。
上次以非常缓慢和昂贵的方式将 HEAD 传播到每个容器分片,然后汇总结果。这_非常_昂贵。
我们在东京讨论过这个问题,解决方案是每隔一段时间更新计数。由于我们处理的是也进行了复制的容器分片,因此有很多计数需要更新,当它们都需要更新根容器中的单个计数时,情况变得复杂。
现在,pivot_ranges 表还存储了每个范围的“当前”计数和 bytes_used,由于每个范围代表一个分片容器,我们现在有了一个可以单独更新的地方
CREATE TABLE pivot_ranges (
ROWID INTEGER PRIMARY KEY AUTOINCREMENT,
lower TEXT,
upper TEXT,
object_count INTEGER DEFAULT 0,
bytes_used INTEGER DEFAULT 0,
created_at TEXT,
deleted INTEGER DEFAULT 0
);
当我们容器 HEAD 根容器时,我们只需要对列进行求和。这是 ContainerBroker 的 get_pivot_usage 方法使用一个简单的 SQL 语句所做的。
SELECT sum(object_count), sum(bytes_used)
FROM pivot_ranges
WHERE deleted=0;
已经完成了一些工作,以便能够更新这些 pivot_ranges,以便可以更新统计信息。您现在可以通过 container-server API 通过简单的 PUT 或 DELETE 来更新它们。pivot range API 允许您发送带有某些标头的 PUT/DELETE 请求来更新 pivot range,这些标头是
- x-backend-record-type - 必须是 RECORD_TYPE_PIVOT_NODE,否则它将被视为一个对象。
- x-backend-pivot-objects - 对象计数,前面带有 - 或 +(稍后会详细介绍)。
- x-backend-pivot-bytes - 范围使用的字节数,同样可以前面带有 - 或 +。
- x-backend-pivot-upper - 上限范围,下限范围是请求中对象的名称。
注意
我们使用 x-backend-* 标头,因为这些应该仅由 swift 的后端使用。
对象和字节可以选择性地以 ‘-‘ 或 ‘+’ 作为前缀,当它们这样做时,它们会相应地影响计数。
例如,如果我们想为对象数量定义一个新值,那么我们可以
x-backend-pivot-objects: 100
这将为范围的 object_count 统计信息设置值为 100。分片器在每次传递期间都以这种方式设置新的计数和字节数,以反映当前的世界状态,因为它知道当时最好。但是,API 允许请求
x-backend-pivot-object: +1
这将增加当前值。在这种情况下,新值为 101。‘-’ 将减少。
这个想法是,如果一个 Op 愿意在集群中牺牲更多的请求以获得更最新的统计信息,我们可以让对象更新器和对象服务器在添加或删除对象时发送 + 或 -。分片器会在计数略微不同步时纠正计数。
ContainerBroker 中的 merge_items 方法将在需要时将带有前缀的请求合并在一起 (+2 等)。
负责人¶
- 主要负责人
- mattoliverau
- 其他指派人
- blmartin
工作项¶
工作项目或任务 – 将该功能分解为实施它需要完成的事情。这些部分可能最终由不同的人完成,但我们主要试图了解实施的时间表。
仓库¶
不需要新的仓库。
服务¶
已创建一个 container-sharder 守护进程,用于在后台分片容器
文档¶
这是否需要文档更改? 是
如果是,哪些文档? 部署指南、API 参考、示例配置文件 (TBA) 这会影响开发人员的工作流程吗? 分片容器的限制,特别是对象顺序,如果指向分片容器,将影响 DLO 和现有的 swift 应用程序开发工具。
依赖项¶
TBA