This work is licensed under a Creative Commons Attribution 3.0
Unported License.
http://creativecommons.org/licenses/by/3.0/legalcode
Erasure Code 支持¶
本文档是一个持续更新的文档,随着团队对设计进行迭代,因此这里的细节反映了当前的思考,但可能会随着开发进展而改变。团队使用 Trello 来跟踪更实时的讨论和活动,这些细节和想法会记录在此文档中。
Trello 讨论板可以在此 链接 找到。主要的剩余任务由一个数字标识,该数字可以在相应的 Trello 卡片中找到。未完成的任务列在每个章节的末尾。随着本文档的更新和/或 Trello 卡片的完成,请务必同时更新这两个地方。
WIP 修订历史
- 7/25,更新了元图片,明确对象元数据是系统级的,重做重构器部分
- 7/31,添加了对 Trello 卡片的追溯性,通过章节编号和编号的任务项,添加了许多章节
- 8/5,更新了中间件部分,容器同步部分,删除了 3.3.3.7 作为重复项,重构部分,创建通用的代理节点接口,部分 PUT hency 在 obj sysmet patch 上,与 trello 同步
- 8/23,基于 8/22 的电话会议,对重构器部分进行了许多更新。同时添加了关于 PUT 时不删除的注释(在相关情况下),并更新了引用已关闭 Trello 卡片的章节
- 9/4,在重构器部分添加了关于并发性的章节
- 10/7,重构器部分更新 - 很多
- 10/14,更多重构器部分更新,两阶段提交介绍 - 审查中的一些拼写错误
- 10/15,来自面对面审查的一些澄清,以及对之前称为两阶段提交的内容的更大的重措/实现更改
- 10/17,关于 .durable 的一些澄清说明
- 11/13:重要提示:重构器的几个方面正在被重做;该部分将尽快更新
- 12/16:重构器更新,一些小的更新贯穿全文。
- 2/3:重构器更新
- 3/23:快速清理,使内容与当前实现保持一致
- 4/14:Ec 已合并到 master 分支。此规范的某些部分不再是设计的权威,请查看 master 上的代码和用户文档。
1. 摘要¶
EC 在 Swift 中作为存储策略实现,请参阅 文档 以获取有关存储策略的完整详细信息。
EC 支持影响使用 EC 策略创建的容器的数据的许多代码路径和后台操作,但所有这些对集群用户来说都是透明的。除了充分利用存储策略框架外,EC 设计还将更新存储策略类,以便新的策略(如 EC)将是通用基本策略类的子类。主要的代码路径(PUT/GET)已更新,以适应编码/解码与复制的不同需求,并且一个新的守护进程,EC 重构器,执行复制过程的复制器的等效工作。其他主要的守护进程在很大程度上保持不变,因为 EC 的另一个关键概念是 EC 片段(见下面的术语部分)被大多数服务视为常规对象,从而最大限度地减少对现有代码库的影响。
Swift 代码库不包含执行实际数据编码和解码所需的任何算法;这留给外部库。利用存储策略架构可以在每个容器的基础上实现 EC,并且对象环仍然提供 EC 数据片段的放置。尽管存在一些与 EC 策略相关的操作的独特代码路径,但 Swift 依赖于外部 Erasure Code 库来执行低级别的 EC 函数。使用外部库可以实现最大的灵活性,因为那里有大量的选项,每个选项都有其自身的优缺点,这些优缺点因用例而异。
2. 问题描述¶
EC 的主要目标是通过提供使用更少的磁盘空间来保持相同或更好的持久性水平,来降低与大量数据相关的存储成本(包括运营成本和资本成本)。有关此声明的更多详细信息,请参阅此 研究。
EC 不打算取代复制,因为它可能不适合所有使用模型。我们预计会进行充分表征的性能和网络使用权衡,一旦有足够的代码到位就可以收集经验数据。当前的思考是,通常所说的“冷存储”是 EC 作为持久性方案的最常见/合适的用途。
3. 拟议的更改¶
3.1 术语¶
“片段”一词已经用于描述 EC 过程的输出(一系列片段),但我们需要在此定义其他一些关键术语,然后再深入研究。如果不特别注意一致使用正确的术语,很容易很快感到困惑!
- 片段:不要与 SLO/DLO 对该词的使用混淆,在 EC 中,我们将一系列连续的 HTTP 数据块缓冲起来,然后再执行 EC 操作,称为一个片段。
- 片段:数据和奇偶校验“片段”是在将擦除编码转换应用于片段时生成的。
- EC 存档:EC 片段的串联;对于存储节点,它看起来像一个对象
- ec_k:EC 数据片段的数量(k 通常在 EC 社区中用于此目的)
- ec_m:EC 奇偶校验片段的数量(m 通常在 EC 社区中用于此目的)
- 数据块:通过线路接收到的 HTTP 数据块(不用于描述任何 EC 特定操作)
- 持久:原始数据可用(无论是否重建)
- 仲数:保证所需的容错能力所需的最小数量的数据 + 奇偶校验元素,即数据元素的数量加上所选擦除编码方案所需的最小数量的奇偶校验元素。例如,对于 Reed-Soloman,所需的最小奇偶校验元素数量为 1,因此 quorum_size 要求为 ec_ndata + 1。由于并非每个擦除编码方案所需的奇偶校验元素数量都相同,请参阅 PyECLib 以获取 min_parity_fragments_needed()
- 完全持久:所有 EC 存档都已写入并可用
3.2 关键概念¶
- EC 是一个具有其自身环和可配置参数集的存储策略。EC 环的副本数是为所选 EC 方案配置的总数据加奇偶校验元素数。
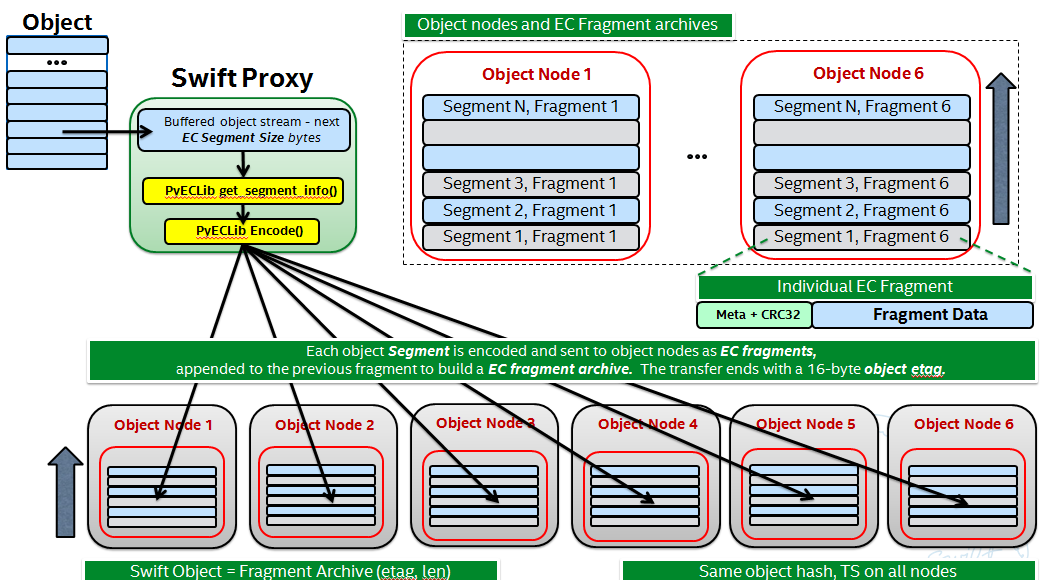
- 代理服务器缓冲一定数量的传入数据,然后通过 PyECLib 对其进行编码,我们称之为对象的“片段”。
- 代理将编码的片段的输出分发到从 EC 环获取的各种对象节点,我们称这些为片段的片段
- 每个片段都携带用于 PyECLib 的不透明元数据
- 对象元数据用于存储关于片段和对象的元数据
- “EC 存档”存储在磁盘上,是片段的附加
- EC 存档容器元数据包含关于原始对象的信息,而不是 EC 存档
- 这是一个 50,000 英尺的概述
3.3 主要更改区域¶
依赖项/要求
请参阅结尾的模板部分
3.3.1 存储策略类
feature/ec 分支修改了实例化策略的方式,以支持新的 EC 策略。
Trello 本节的任务
3.3.1.2:使仲数成为基于策略的函数(已实现)
3.3.2 中间件
中间件保持不变。对于大多数中间件(例如,SLO/DLO),代理将传入对象碎片化这一事实是透明的。但是,对于列表端点,情况就有点不同了。列表端点的调用者将获得所有片段的位置。调用者将无法使用此信息重新组装原始对象,但是节点位置对于某些应用程序仍然可能是信息。
3.3.3 代理服务器
最初,似乎不需要对代理进行重大重构以适应 EC,但这并不意味着现在不是审查可能有哪些选择的好时机。讨论包括
- 我们是否应该考虑传入请求和与后端服务器通信之间更清晰的界限?是的,这样做有意义。Trello 卡片跟踪这项工作,并在下面的部分中介绍。
- 是否应该重构 PUT 路径,仅仅因为它很大而且难以理解?机会性重构有意义,但没有感觉到将 EC 工作的一部分与 PUT 的完全重构结合起来是有意义的。是的!这正在积极进行中。
- 我们是否应该考虑不同的控制器(例如“EC 控制器”)?嗯,可能吧……是的,这正在积极进行中。
以下总结了支持 EC 的代理更改
TODO:目前 Trello 上正在进行讨论,这些讨论会影响这两个流程
- PUT 的基本流程
- 代理向对象服务器打开 (ec_k + ec_m) 个后端请求
- 代理缓冲 HTTP 数据块,直到最小片段大小(从 1MB 开始定义)
- 代理将组装好的片段馈送到 PyECLib 的 encode() 以获取 ec_k + ec_m 个片段
- 代理将 (ec_k + ec_m) 个片段发送到对象服务器,以附加到先前的集合
- 然后代理继续使用下一组 HTTP 数据块
- 对象服务器存储的对象是 EC 存档(其内容是编码片段的串联)
- 对象元数据更改:对于“etag”,我们存储 EC 存档对象的 md5sum,而不是非 EC 情况,在这种情况下我们存储整个对象的 md5sum
- 在获得仲数响应和一些最小(2)数量的提交确认后,响应客户端
- 在接收到提交消息(MIME 会话的一部分)后,存储节点将 0 字节数据文件作为时间戳 .durable 存储,用于相应的对象
- 代理 HTTP PUT 请求处理更改
- 根据策略类型拦截 EC 请求
- 验证环副本计数与 (ec_k + ec_m) 是否一致
- 计算 EC 仲数大小以进行 min_conns
- 调用 PyEClib 以对大小为 client_chunk_size 的对象数据块进行编码,以生成 (ec_k + ec_m) 个 EC 片段。
- 将数据块 EC 片段排队以写入节点
- 引入多阶段提交会话
- GET 的基本流程
- 代理向对象服务器打开 ec_k 个并发后端请求。请参阅 Trello 卡片 3.3.3.3
- 代理将 1) 验证成功的连接数 >= ec_k 2) 检查对象服务器响应的可用片段存档版本相同。 3) 如果未找到足够的数据,则继续从移交节点 (ec_k + ec_m) 搜索。请参阅 Trello 卡片 3.3.3.6
- 代理从前 ec_k 个片段存档并发读取。
- 代理将内容缓冲到片段,直到最小片段大小。
- 代理将组装好的片段馈送到 PyECLib 的 decode() 以获取原始内容。
- 代理将原始内容发送到客户端。
- 然后代理继续使用下一段内容。
代理 HTTP GET 请求处理更改
TODO - 添加高级流程
部分 PUT 处理
注意:Trello 上正在积极进行中。
当先前的 PUT 由于任何原因而失败,并且无论如何将响应发送到客户端,对象服务器上都可能存在各种场景,这些场景需要代理决定该怎么做。请注意,由于对象服务器不会返回没有匹配的 .durable 文件的 .data 文件,因此除非同时发生部分 PUT 和重新平衡(或移交场景),否则代理无法获得不可重建的数据。以下是代理在解释其响应时混合情况的基本规则
If I have all of one timestamp, feed to PyECLib
If PYECLib says OK
I'm done, move on to next segment
Else
Fail the request (had sufficient segments but something bad happened)
Else I have a mix of timestamps;
Because they all have to be recosntructable, choose the newest
Feed to PYECLib
If PYECLib says OK
Im done, move on to next segment
Else
Its possible that the newest timestamp I chose didn't have enough segments yet
because, although each object server claims they're reconstructable, maybe
a rebalance or handoff situation has resulted in some of those .data files
residing elsewhere right now. In this case, I want to look into the
available timestamp headers that came back with the GET and see what else
is reconstructable and go with that for now. This is really a corner case
because we will restrict moving partitions around such that enough archives
should be found at any given point in time but someone might move too quickly
so now the next check is...
Choose the latest available timestamp in the headers and re-issue GET
If PYECLib says OK
I'm done, move on to next segment
Else
Fail the request (had sufficient segments but something bad happened) or
we can consider going to the next latest header....
区域支持
对于 EC 的至少初始版本,不建议 EC 方案跨越单个区域,既没有进行性能验证,也没有进行功能验证。
Trello 本节的任务
* 3.3.3.5: CLOSED
- 3.3.3.9:多阶段提交会话
为了帮助解决本地数据文件清理问题,为 EC PUT 操作引入了多阶段提交方案(上述最后几个步骤)。实现将通过 MIME 文档进行,以便为每个 PUT 代理和存储节点之间进行会话。这为我们提供了处理 PUT 的能力,并确保我们拥有“本质”的两阶段提交,基本上让代理在确认所有集合中的片段存档都已提交后,将信息传达给存储节点。请注意,我们仍然需要仲数的数据元素才能完成会话,然后才能向客户端发出状态信号,但我们可以放宽该要求,以便只需要 2 个确认即可成功完成提交阶段。重构器部分将对此进行更多说明。
现在存储节点在成功的持久化PUT操作后,拥有一个廉价的指标,用于指示给定对象的最后一个已知的持久化碎片存档集合。 重建器也将参与管理`.durable`文件,要么传播它,要么在重建后创建它。 `.ts.durable`文件的存在意味着,对于对象服务器来说,“存在一组在时间戳`ts`时持久化的`ts.data`文件”。 更多细节和`.durable`文件的用例请参见重建器部分。 请注意,会话的提交阶段完成也是对象服务器开始立即删除该对象的较旧时间戳文件的信号(对于EC,它们在PUT时不会立即删除)。 这至关重要,因为我们不希望在存储节点从代理收到确认之前删除较旧的对象,通过多阶段会话,其他节点已经着陆了足够的副本以达到法定数量。
在GET端,这意味着存储节点将返回带有匹配的`.durable`文件的TS,即使它具有较新的`.data`文件。 如果在一个节点上存在没有`.durable`文件的`.data`文件,但另一个节点同时拥有`.data`和`.durable`文件,则代理可以自由使用`.durable`时间戳序列,因为集合中只有一个`.durable`文件就表明对象具有完整性。 如果存在一系列没有`.durable`文件的`.data`文件,它们最终将被重建器删除,因为它们将被认为是无法重建的部分垃圾(回想一下,需要2个`.durables`才能确定PUT操作成功)。
请注意,本节/trello卡片的意图是涵盖代理和存储节点上的多阶段提交实现,但它不涵盖重建器对`.durable`文件所做的操作。
关于`.durable`文件的一些关键点
- `.durable`文件意味着“此文件的匹配`.data`文件在某个地方拥有足够的碎片存档,已提交,可以重建对象”
- 代理服务器在GET或HEAD操作中永远不会知道对象服务器上`.data`文件的存在,除非它具有匹配的`.durable`文件
- 对象服务器永远不会返回没有匹配`.durable`文件的`.data`文件
- 唯一处理没有匹配`.durable`文件的`.data`文件的组件是重建器
- 当代理执行GET操作时,它只会收到存在足够数量的碎片存档以供重建的存档
3.3.3.8:创建代理->节点的通用接口
注意:这不会作为EC工作的一部分发生
创建一个允许对a/c/s节点进行抽象访问的通用模块,不仅可以清理大量的代理IO路径,还可以防止EC的引入进一步复杂化PUT路径。 考虑一个接口,该接口允许代理代码执行对后端节点的通用操作,而无需考虑协议。 建议在此处更新提议的API并进行审查,并且认为它可以与现有的EC代理工作并行完成(没有依赖关系,这项工作足够小,可以合并)。
3.3.3.6:对象覆盖和PUT错误处理
这里需要的是一种机制来确保我们可以处理部分写入失败。 注意:在两种情况下,客户端都会收到失败,但是如果没有额外的更改,每个保存EC碎片存档的存储节点实际上都会有一个孤儿。
- 写入的节点少于法定数量
- 满足法定数量,但并非所有节点都已写入
在两种情况下,都对代理和对象服务器上的PUT和GET有影响。 此外,重建器在此处也发挥作用,清理由此方案产生的旧EC存档(有关详细信息,请参见重建器)。
高级流程
- 如果正在存储EC存档碎片,对象服务器不应删除较旧的`.data`文件,除非它具有带有匹配`.durable`文件的新的文件。
- 当对象服务器处理GET请求时,它需要将包含`.data`文件的所有可用时间戳的标头发送到代理
- 如果代理确定可以使用最新的时间戳重建对象(可以达到法定数量),则继续
- 如果无法达到法定数量,找到可以达到法定数量的时间戳,关闭现有连接(除非该请求的主体是找到的时间戳),并建立新的连接以请求特定的时间戳
- 在GET操作中,对象服务器需要支持请求特定的时间戳(例如?timestamp=XYZ)
Trello 本节的任务
* 3.3.3.1: CLOSED
* 3.3.3.2: Add high level GET flow
* 3.3.3.3: Concurrent connects to object server on GET path in proxy server
* 3.3.3.4: CLOSED
* 3.3.3.5: Region support for EC
* 3.3.3.6 EC PUTs should not delete old data files (in review)
* 3.3.3.7: CLOSED
* 3.3.3.8: Create common interface for proxy-->nodes
* 3.3.3.9: Multi-Phase Commit Conversation
3.3.4 对象服务器
TODO - 添加高级流程
Trello 本节的任务
* 3.3.4.1: Add high level Obj Serv modifications
* 3.3.4.2: Add trailer support (affects proxy too)
3.3.5 元数据
注意:代码中其中一些元数据名称不同……
额外的元数据是EC设计中的一部分,分布在几个不同的区域
- 新的元数据作为每个“碎片”引入,对Swift不透明,由PyECLib用于内部目的。
- 新的元数据作为系统对象元数据引入,如图所示
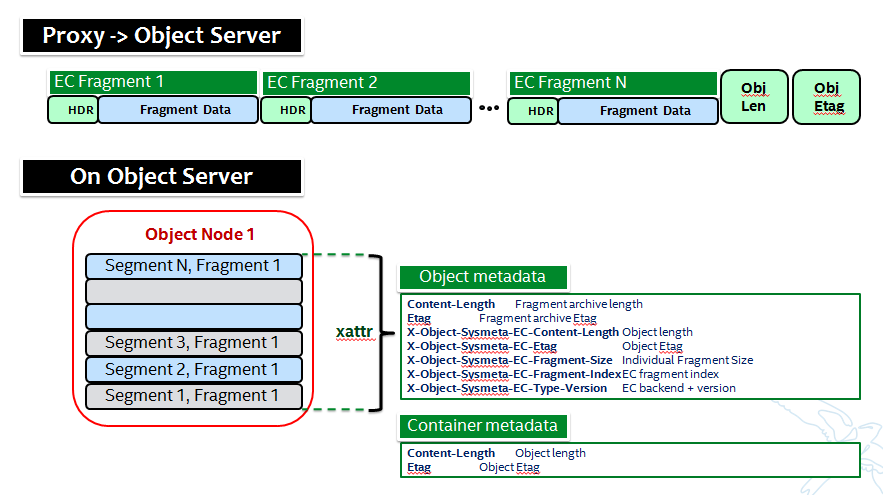
对象元数据需要作为系统元数据存储。
Trello 本节的任务
* 5.1: Enable sysmeta on object PUT (IMPLEMENTED)
3.3.6 数据库更新
我们不需要/不希望每个参与EC集合的存储节点都发送容器更新,实际上,在没有任何额外更改的情况下,这就是它的工作方式,有关详细信息,请参见代理PUT路径中的`_backend_requests()`。
3.3.7 重建器
概述
重建器设计中的关键概念是
- 关注最常发生的使用场景
- 从磁盘驱动器故障中恢复
- 再平衡
- 环更改和可逆交接情况
- 位腐烂
- 重建发生在EC存档级别(对于审计或重建,无法查看碎片级别)
- 高度利用ssync来了解需要哪些EC存档(需要一些ssync修改,考虑将动词REPLICATION重命名为,因为ssync现在可以以不同的方式同步)
- 对现有复制器框架、审计器、ssync的最小更改
- 作为新的重建器守护程序实现(从复制器中大量重用),因为会有一些差异,并且我们希望为重建器提供单独的日志记录和守护程序控制/可见性
- 列表中节点仅对其邻居采取行动,关于重建(节点不与所有其他节点通信)
- 一旦放置了一组EC存档,碎片索引与主分区列表中节点的索引的匹配/排序必须为交接节点使用保持
- EC存档以其碎片索引编码在文件名中
重建器框架
当前实现的想法是,重建器作为自己的守护程序运行,以便它具有独立的日志记录和控制。 它的结构大量借鉴了复制器。
重建器需要与复制器不同地做一些事情,除了显而易见的EC功能之外。 主要区别是
- 不再存在同步或回退的2个作业处理器,而是存在一个作业预处理器,用于确定需要做什么,并且一个作业处理器执行所需的操作
- 仅与分区列表中的左侧和右侧节点同步(不与所有节点同步)
- 对于回退,与根据其持有的碎片索引确定的尽可能多的节点同步;节点的数量将等于其持有的唯一碎片索引的数量。 它将使用这些索引作为主节点列表中的索引来确定要同步的节点。
节点/索引配对
以下是一些有助于解释为什么对于刚刚提到的两种操作,节点/碎片索引配对如此重要的场景。
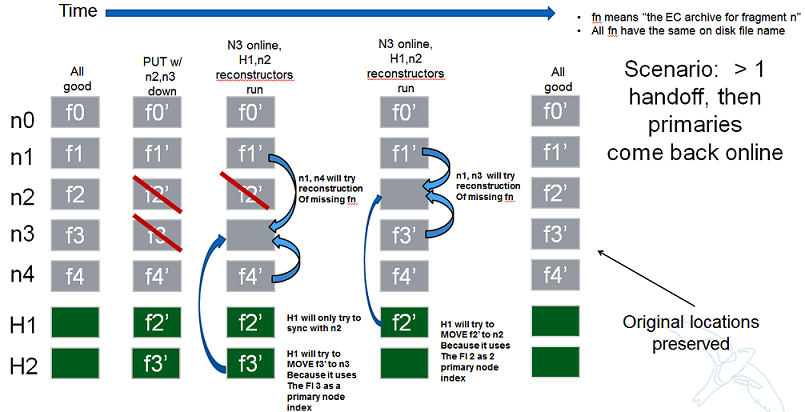
下一个场景
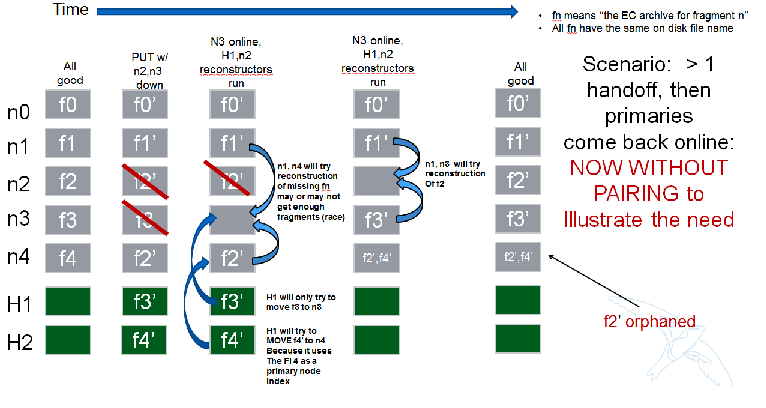
碎片索引文件名编码
现在每个存储策略都必须包含一个转换函数,diskfile将使用该函数来构建存储在磁盘上的文件名。 这是重建器出于几个原因所必需的。 一方面,它允许我们将不同索引的碎片存档存储在同一个存储节点上。 这在理想情况下不是这样,但在某些情况下是可能的。 如果没有不同EC存档文件的唯一文件名,我们可能会在某些场景中用索引n的存档覆盖索引m的存档。
复制策略的转换函数只是NOP。 对于重建,索引在`.data`扩展名之前附加到文件名。 存储索引为5的碎片的示例文件名如下所示
1418673556.92690#5.data
Diskfile重构
为了更干净地适应EC的一些低级别磁盘存储需求(文件名、`.durable`等),diskfile引入了一些额外的分层,允许需要EC特定更改的函数被隔离。 TODO:在此处添加详细信息。
重建器作业预处理
由于任何给定的后缀目录可能包含多个碎片索引数据文件,因此重建器需要采取的措施并不像复制器那样简单,即同步或回退数据。 因此,对于重建器来说,分析每个部分/后缀/碎片索引需要做什么,然后安排由单个作业处理器执行的一系列作业(而不是像复制器那样必须清除同步和回退场景)会更有效。 预处理器正在查看的主要场景是
- 部分目录与所有FI匹配本地节点索引,在这种情况下,一切都应该在正确的位置,我们只需要比较哈希并同步(如果需要),在这里我们与我们的合作伙伴同步
- 部分目录与一个本地和混合其他目录,在这里我们需要与我们的合作伙伴同步,其中FI匹配本地id,所有其他目录都与他们的主节点同步,然后被杀死
- 部分目录没有本地FI,只有其他一个或多个,在这里我们只与存在的FI同步,没有人,然后所有本地FA都被杀死
因此,作业处理器收到的作业的主要元素包括一个确切要与谁交谈的列表,哪些后缀目录不同步以及要关注哪个碎片索引。 此外,该作业包括由ssync和重建器在需要时用于删除源节点上`.data`文件的信息。
重建行为
可以认为重建类似于复制,但中间多了一步。 重建器被硬编码为使用ssync来确定缺少什么以及另一方需要什么,但是,在将对象发送到网络之前,需要从剩余的碎片中重建它,因为本地碎片只是一个不同的碎片索引,而不是另一端请求的索引。
因此,ssync中存在用于EC基于策略的钩子。 一种情况是基本的重建,从高级别来看,它看起来像这样
- 询问PyECLib哪些节点需要联系以收集其他EC存档以执行重建
- 建立到目标节点的连接,并向ssync提供一个DiskFileLike类,ssync可以从中流式传输数据。 此类中的读取器将从节点收集碎片并使用PyECLib重建每个段,然后再将数据返回给ssync
本质上,这意味着数据在执行重建的节点上以每段为基础进行缓冲,并且每个段都是动态重建的,并通过ssync_sender发送。
下图显示了启用重建的ssync更改。 请注意,此处未涵盖几个实现细节,这些细节涉及确保使用正确的碎片存档索引、正确设置重建对象的元数据、在回退后删除文件/后缀目录等。
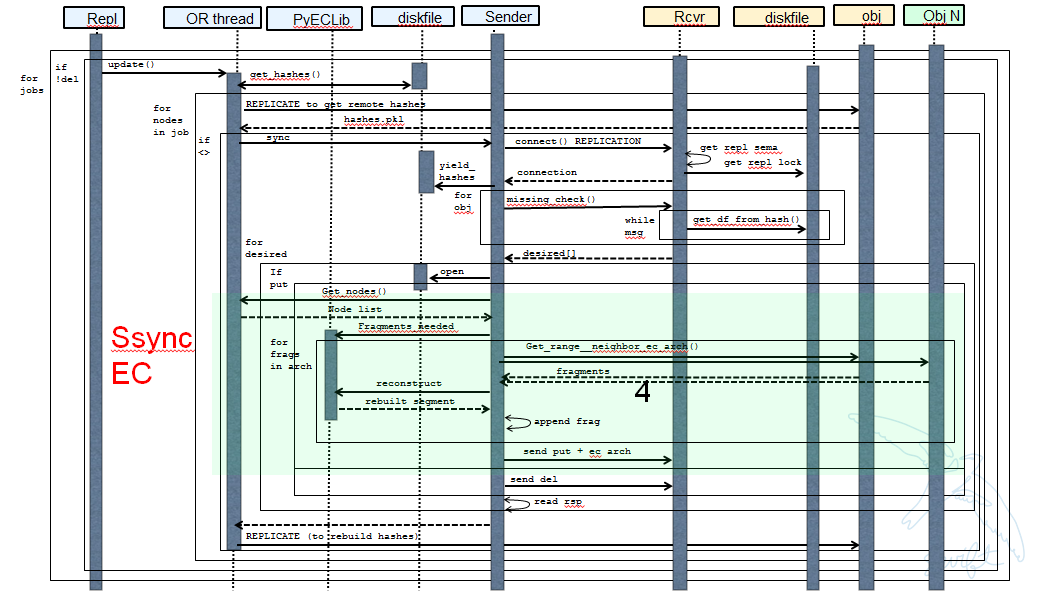
重建器本地数据文件清理
注意:本节已过时,需要清理。 不要阅读……
对于重建器,清理与复制略有不同,因为出于PUT一致性原因,对象服务器将保留以前的`.data`文件(如果存在),以防最新的PUT未在法定数量的节点上成功完成。 这给复制器处理清理旧文件带来了许多场景
a) 假设PUT成功(收到提交),重建器需要删除本地节点上较旧的时间戳。 可以通过检查TS.data和TS.durable文件名在本地检测到。 任何早于TS.durable的TS.data都可以删除。
b) 假设达到法定数量或更多,`.durable`文件没有到达某些节点,重建器将检测到这一点(不同的哈希,进一步检查显示存在本地`.durable`文件和远程匹配ts文件,但没有远程`.durable`),并简单地将`.durable`文件推送到远程节点,基本上复制它。
c) 如果PUT仅部分完成,但仍然能够获得法定数量,重建器首先需要重建对象,然后将EC存档推送到所有参与节点都拥有一个,然后它可以删除本地节点上较旧的时间戳。 一旦对象被重建,就会创建一个TS.durable文件并提交,以便每个存储节点都有一条关于最新持久化集合的记录,就像多阶段提交在PUT中工作一样。
d) 如果PUT仅部分完成并且没有获得法定数量,则无法进行重建。 因此,重建器需要删除这些文件,但还必须有一个年龄因素来防止其删除正在进行的PUT。 这应该是默认行为,但如果管理员可能希望出于某种原因保留部分内容(例如,更轻松的DR),则可以覆盖它。 无论如何,记录发生这种情况都有很大意义。 当重建器尝试重建时,它注意到它没有特定TS.data的TS.durable,并且获得足够的409错误,以至于它无法向PyECLib提供足够的数据进行重建(它需要提供它获得的内容,而PYECLib会告诉它是否不够)。 是否删除`.data`文件,以某种方式标记它,以便我们停止尝试重建还有待确定。
重建器再平衡
当前的想法是,这里不需要任何特殊处理,除了交接回退部分中描述的更改之外。
重建器并发
重建器有2个并发方面需要考虑
- 守护程序的并发
这意味着对于重建器来说与复制器相同,即用于“更新”和“更新删除”作业的GreenPool的大小。
- 分区重建的整体并行性
关于节点间通信,我们已经讨论过重建器不能简单地检查其邻居以确定它应该对其当前运行采取什么行动(如果有的话),因为它需要知道整个条带的状态(不仅仅是一个或两个其他EC存档的状态)。
但是,我们不希望它实际对所有其他节点采取行动。 换句话说,我们希望检查每个节点以查看是否需要重建,并且如果需要,我们不希望尝试对合作伙伴节点进行重建,而是对其左侧和右侧的邻居进行重建。 这将最大限度地减少重建争用,同时仍然提供冗余来解决EC存档的重建。
如果一个节点(HDD)发生故障,那么每个分区将有 2 个伙伴参与该节点的重建工作。例如,如果我们有 6 个主节点,并且节点 1 的 HDD 发生故障。我们只想让节点 0 和 2 将作业添加到它们本地的重建器,即使当它们调用 obj_ring.get_part_nodes(int(partition)) 获取条带的其他成员列表时,它们会返回 6 个节点。本地节点将根据其在节点列表中的位置决定是否添加重建作业。
通过这样做,我们最大限度地减少了重建冲突,但仍然使所有 6 个节点能够参与故障 HDD 的重建工作,因为分区将分布在所有节点之间。因此,发生故障的 HDD 节点可能会有其他所有节点并行地将重建的 EC 归档推送到手递手节点,每个分区最多有 2 个节点争夺重建其归档。
下图说明了上述示例。
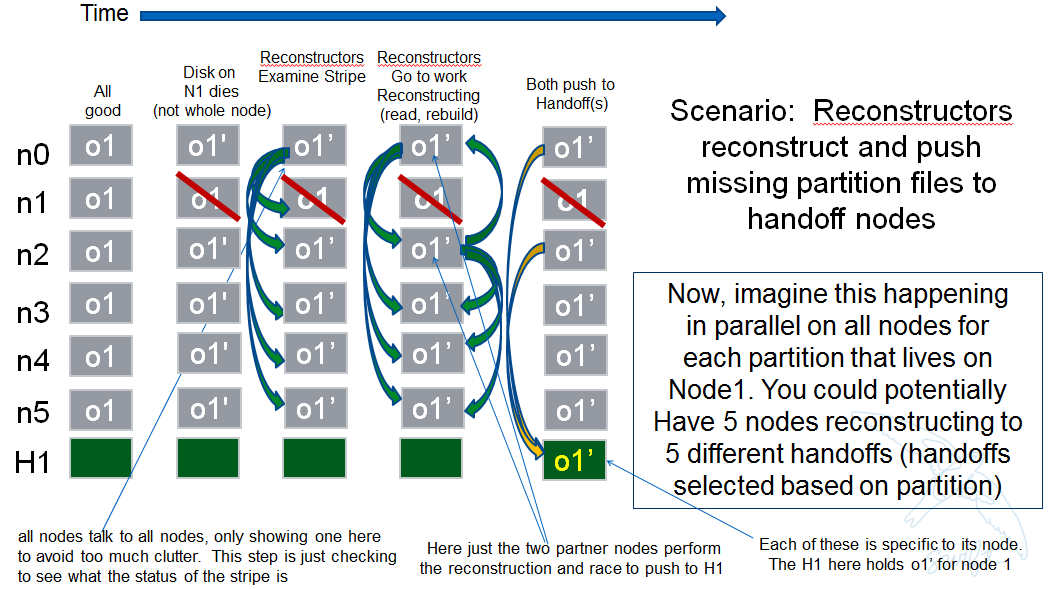
场景
以下一系列图片更完整地说明了各种场景。我们将针对重建器的主要功能使用这些场景,我们将定义这些功能为
- 重建器框架(守护进程)
- 重建(根据规范序列图的 Ssync 更改)
- 重建器本地数据文件清理
- 再平衡
- 交接恢复(将数据移回主节点)
待办事项:一旦为上述主要领域提出了设计,就将其映射到下面的场景以确保完整性。

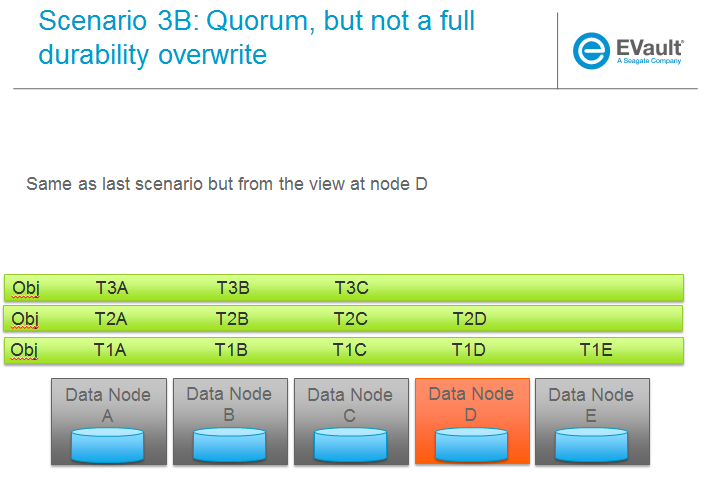
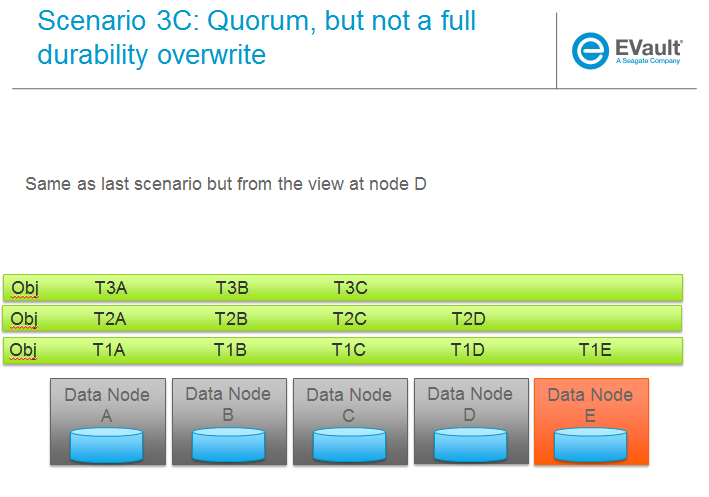

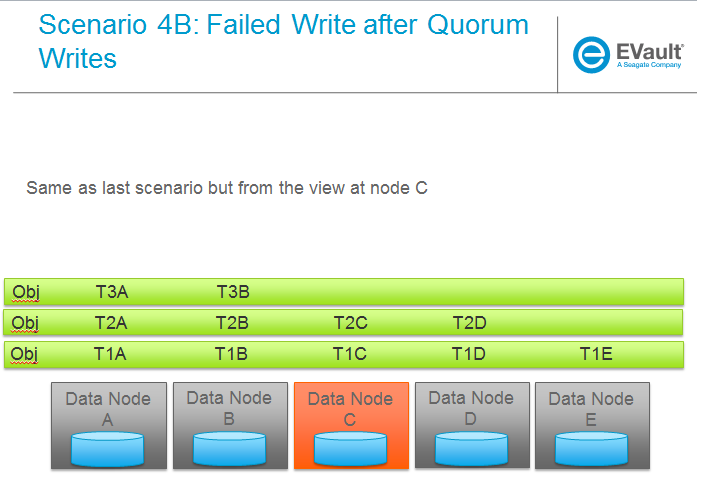



Trello 本节的任务
* 3.3.7.1: Reconstructor framework
* 3.3.7.2: Ssync changes per spec sequence diagram
* 3.3.7.3: Reconstructor local data file cleanup
* 3.3.7.4: Node to node communication and synchrinozation on stripe status
* 3.3.7.5: Reconstructor rebalance
* 3.3.7.6: Reconstructor handoff reversion
* 3.3.7.7: Add conf file option to never delete un-reconstructable EC archives
3.3.8 审计器
由于审计器已经基于每个存储策略运行,因此与 EC 没有相关的特定审计器更改。每个 EC 归档看起来像一个常规对象,并且从审计器的角度被视为一个常规对象。因此,如果审计器在 EC 归档中发现位腐烂,它只需将其隔离,EC 重建器将像复制器处理复制策略一样处理剩余部分。由于隔离目录已经按策略隔离,EC 归档有自己的隔离目录。
3.3.9 性能
有很多考虑、计划、测试、调整、讨论等等,等等要做。
Trello 本节的任务
* 3.3.9.1: Performance Analysis
3.3.10 环
我认为这里唯一真正要做的事情是使重新平衡能够一次移动一个分区的一个以上的副本。在我看来,EC 方案存储在 swift.conf 中,而不是环中,并且放置和设备管理不需要任何更改来适应 EC。
我们还希望清理环工具,使用“节点”而不是“副本”一词,以避免与 EC 混淆。
Trello 本节的任务
* 3.3.10.1: Ring changes
3.3.11 测试
由于这些测试并不总是基于每个补丁显而易见(或可能),(因为它们依赖于其他补丁),我们需要记录我们希望确保在代码支持它们后涵盖的场景。
3.3.11.1 探测测试
这个 Trello 卡片有一个很好的测试场景起始列表,随着设计的进展,应该添加更多。
3.3.11.2 功能测试
至少从一开始,我们认为只需要将 EC 策略设置为默认值并运行现有的功能测试(并确保它自动执行)。
Trello 本节的任务
* 3.3.11.1: Required probe test scenarios
* 3.3.11.2: Required functional test scenarios
3.3.12 容器同步
容器同步假定使用副本。在当前设计中,从 EC 策略同步容器只会将一个片段归档发送到远程容器,而不是重建的对象。
因此,容器同步需要更新为使用内部客户端,而不是仅会获取片段归档的直接客户端。
Trello 本节的任务
* 3.3.12.1: Container synch from an EC containers
3.3.13 EC 配置助手工具
包含在 Swift 中的脚本,以帮助确定最佳 EC 方案以及 swift.conf 中的参数应该是什么。
Trello 本节的任务
* 3.3.13.1: EC Configuration Helper Tool
3.3.14 SAIO 更新
我们希望确保 SAIO 环境易于用于 EC 开发和实验。就像我们对策略所做的那样,一旦我们决定它看起来像什么,我们将更新文档和脚本。
现在让我们从 8 个总节点(4 个服务器)和 4+2+2 方案(4 个数据,2 个奇偶校验,2 个交接)开始。
Trello 本节的任务
* 3.3.13.1: SAIO Updates (IMPLEMENTED)
3.4 替代方案¶
这种设计是“代理中心”的,这意味着所有 EC 都是“在线”完成的,当我们接收/发送数据进出集群时。另一种设计可能是“存储节点中心”的,在这种设计中,代理实际上不知道 EC 工作,新的守护进程会根据规则将数据从 3x 移动到 EC 方案,这些规则可以包括对象年龄和大小等因素。对这两种方案进行了大量的讨论,但最终选择了前者,原因如下
EC 是 CPU/内存密集型的,而“代理中心”更符合提供商计划/已经部署其 HW 基础设施的方式。
在代理端拥有更多智能,而在存储节点端拥有更少智能,更符合 Swift 的总体架构原则。
后一种方法仅限于“离线”EC,这意味着数据始终必须经过“复制”过程才能成为擦除编码,这对于许多应用程序来说不够实用。
前者提供“在线”以及“离线”功能,允许应用程序首先将数据存储在复制策略中,然后在稍后将该数据复制到不同的容器以进行 EC。对于允许应用程序控制数据持久性策略,还有其他方法/想法,这里没有涵盖,但被认为可以使用此方案,从而使其更加容易。
替代重建器设计
一个替代的但被拒绝的提案被归档在 Trello 上。
被拒绝提案的关键概念是
在片段级别(子段)执行审计,以避免使工作单元成为 EC 归档。这将减少重建网络流量。
今天,审计器隔离整个对象,对于片段级别的重建,我们需要一个额外的步骤来识别归档中哪个片段是坏的,并可能将其隔离在不同的位置,以防止在重建器完成之前删除归档。
今天,hashes.pkl 仅标识需要关注的后缀目录。对于片段级别的重建,重建器需要额外的信息,因为它不仅仅是在目录级别同步:需要知道后缀目录中哪个片段归档需要工作,需要知道归档中的哪个段索引是坏的,需要知道归档的片段索引(EC 归档在集合中的位置)。
在本地节点上执行重建,但通过新的动词保留推送模型,让远程节点通信重建信息。这将减少重建网络流量。这可能会导致本地节点重建流量过载,而不是使用所有参与分区的系统的所有计算能力。
替代重建器设计 #2
该设计提案利用 REPLICATE 动词,但为 EC 引入了一种新的 hashes.pkl 格式,为了便于阅读,将其命名为 ec_hashes.pkl。文件的内容将在稍后介绍,但基本上它需要包含任何节点为了遍历其数据并决定是重建、删除还是移动数据而需要知道的所有内容。因此,对于 EC,标准的 hashes.pkl 文件和/或对其进行操作的函数是不相关的。
ec_hashes.pkl 中的数据具有以下属性
- 需要跨所有节点同步
- 需要对任何给定对象哈希拥有完整的信息才能使其有效
- 可以为某些对象哈希完整,为其他对象哈希不完整
实现这一点有很多选择,从八卦方法到共识方案。建议的设计利用了这样一个事实:所有节点都可以访问一个公共结构和访问器函数,这些函数被假定为最终同步的,以便任何节点列表中的位置都可以用于选择以下两种需要节点-节点通信的操作之一的主节点:(1)ec_hashes.pkl 同步和(2)重建。
ec_hashes.pkl 同步
在任何给定时间,从 get_part_nodes() 返回的节点集中将有一个节点充当 ec_hashes.pkl 信息同步的主节点。重建器在每次遍历开始时,将使用欺凌式算法选举哈希主节点。当每个重建器启动一个遍历时,它将向所有节点发送一个选举消息,这些节点的节点索引低于它。如果无法连接到这些节点,则它假定哈希主节点的角色。如果任何较低索引的节点回复,则它继续使用当前遍历,根据其 ec_hashes.pkl 中的当前信息处理其对象。这种类似于欺凌的算法实际上无法防止 2 个主节点同时运行(例如,节点 0-2 都可以关闭,因此节点 3 作为主节点启动,然后其中一个节点恢复,它也会启动哈希同步过程)。请注意,这不会导致功能问题,只是有点浪费,但可以避免实施更复杂的共识算法,这被认为不值得付出努力。
主节点的作用将是
- 向集合中的所有其他节点发送 REPLCIATE
- 合并结果
- 向所有其他节点发送 REPLICATE 的新变体
- 节点合并到其 ec_hashes.pkl 中
这样,通常一个节点会向 n 个其他节点发送 2 个 REPLICATE 动词,每次重建器遍历 2(n-1) REPLICATE,即 O(n),而复制为 O(1),其中 3 个节点会发送 2 个消息,每次遍历总共 6 个消息。请注意,主节点在收集节点 pkl 文件后进行合并与节点在接收主版本后进行合并之间存在明显的区别。当主节点合并时,它仅使用有关发送节点的新信息更新主副本。当节点从主节点合并时,它仅更新有关所有其他节点的信息。换句话说,主节点仅对有关该节点本身的信息感兴趣,而任何给定节点仅对了解其他所有节点感兴趣。稍后会详细介绍这些合并规则。
在任何给定时间,节点上的 ec_hashes.pkl 文件都可能处于各种状态,不要求即使由主节点发送了同步集,参与节点也必须检查同步版本。每个对象哈希在 ec_hashes.pkl 中都将包含指示该特定条目是否同步的信息,因此,在重建器运行的特定遍历中,解析 ec_hashes.pkl 文件并仅找到一些百分比 N 的同步条目,其中 N 从 100% 开始下降,因为对本地节点进行了更改(添加对象、隔离对象)。稍后将在定义文件格式后提供一个示例。
ec_hashes 数据结构
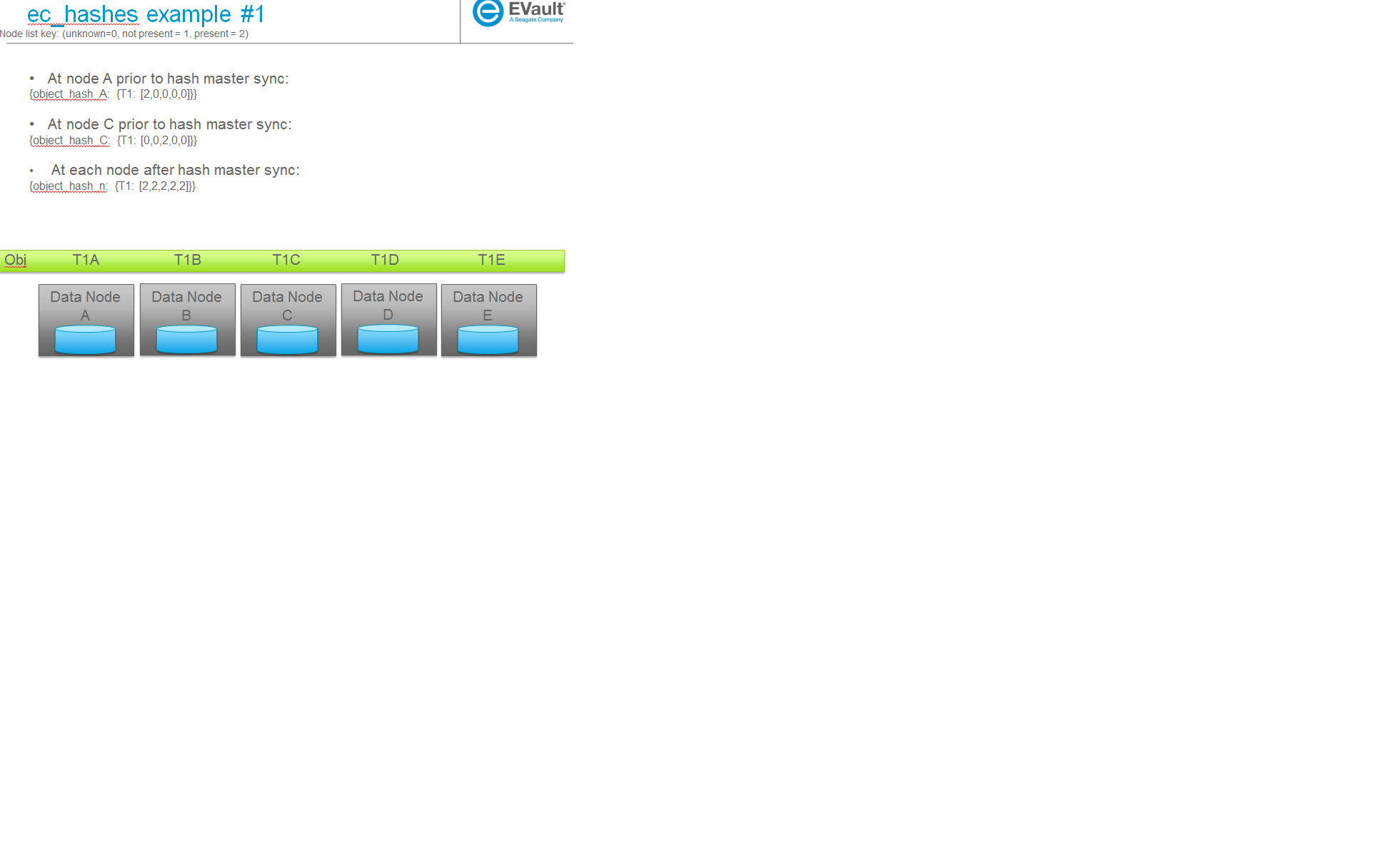
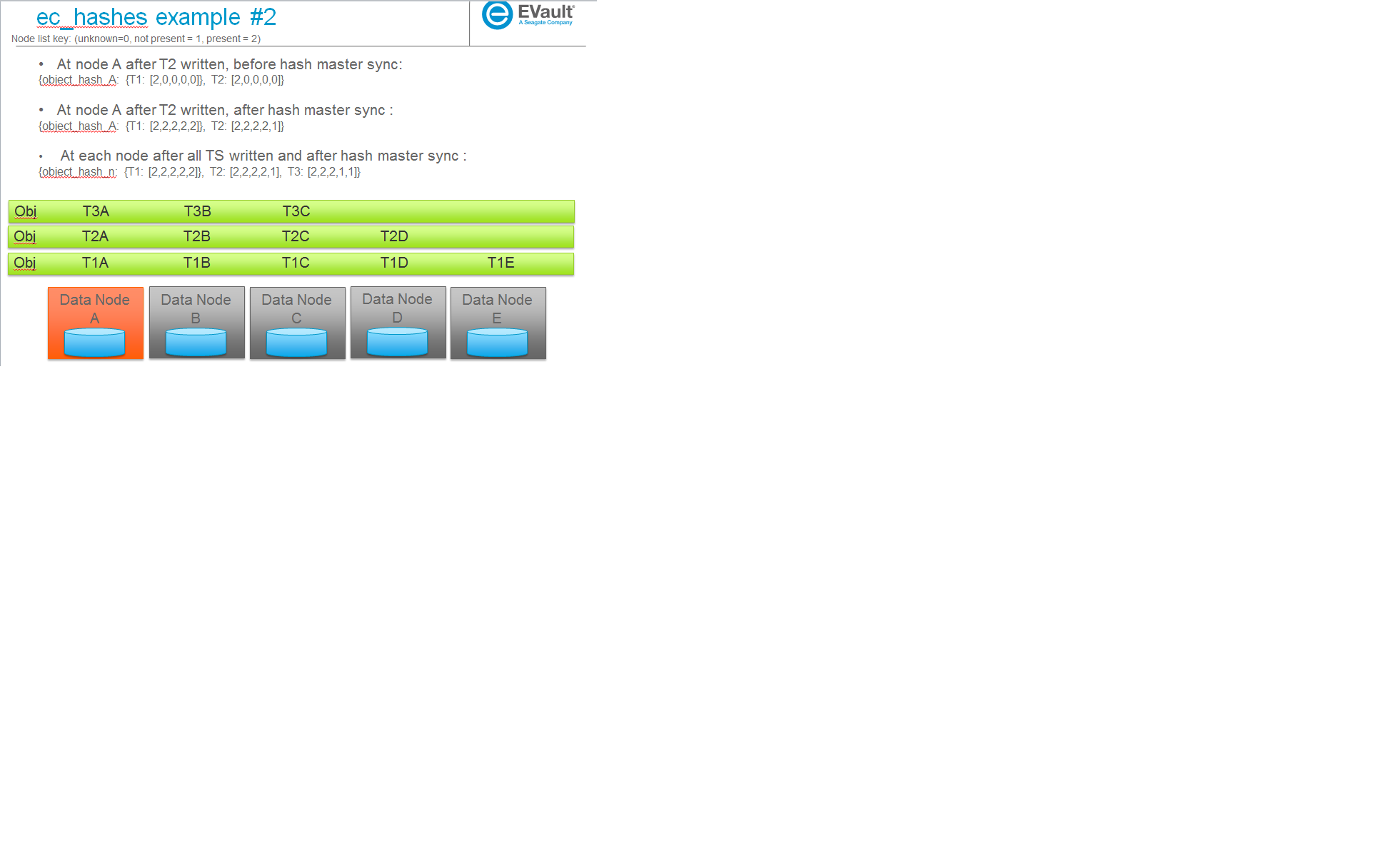
- {object_hash_0: {TS_0: [node0, node1, ...], TS_n: [node0, node1, ...], ...},
- object_hash_1: {TS_0: [node0, node1, ...], TS_n: [node0, node1, ...], ...}, object_hash_n: {TS_0: [node0, node1, ...], TS_n: [node0, node1, ...], ...}}
其中 nodeX 采用未知、不存在或存在的值,以便解析其本地结构的重建器可以确定对象一个对象的基础上的 TS 文件存在于哪些节点上,它缺少哪些节点或它是否对该 TS 具有不完整的信息(该 TS 的节点值标记为未知)。请注意,虽然此文件格式将包含每个对象的信息,但一旦本地节点看到有关该条目的所有其他节点的信息,本地节点就会从文件中删除对象。因此,该文件不会包含系统中的每个对象的一个条目,而是包含一个瞬态条目,用于每个对象,而该对象正在被接受到系统中(验证其与 EC 的一致性)。
新的 ec_hashes.pkl 受到几个潜在写入者的影响,包括哈希主节点、其自身的本地重建器、审计器、PUT 路径等,因此将使用 hashes.pkl 今天使用的相同锁定。以下说明了 ec_hashes.pkl 的持续更新
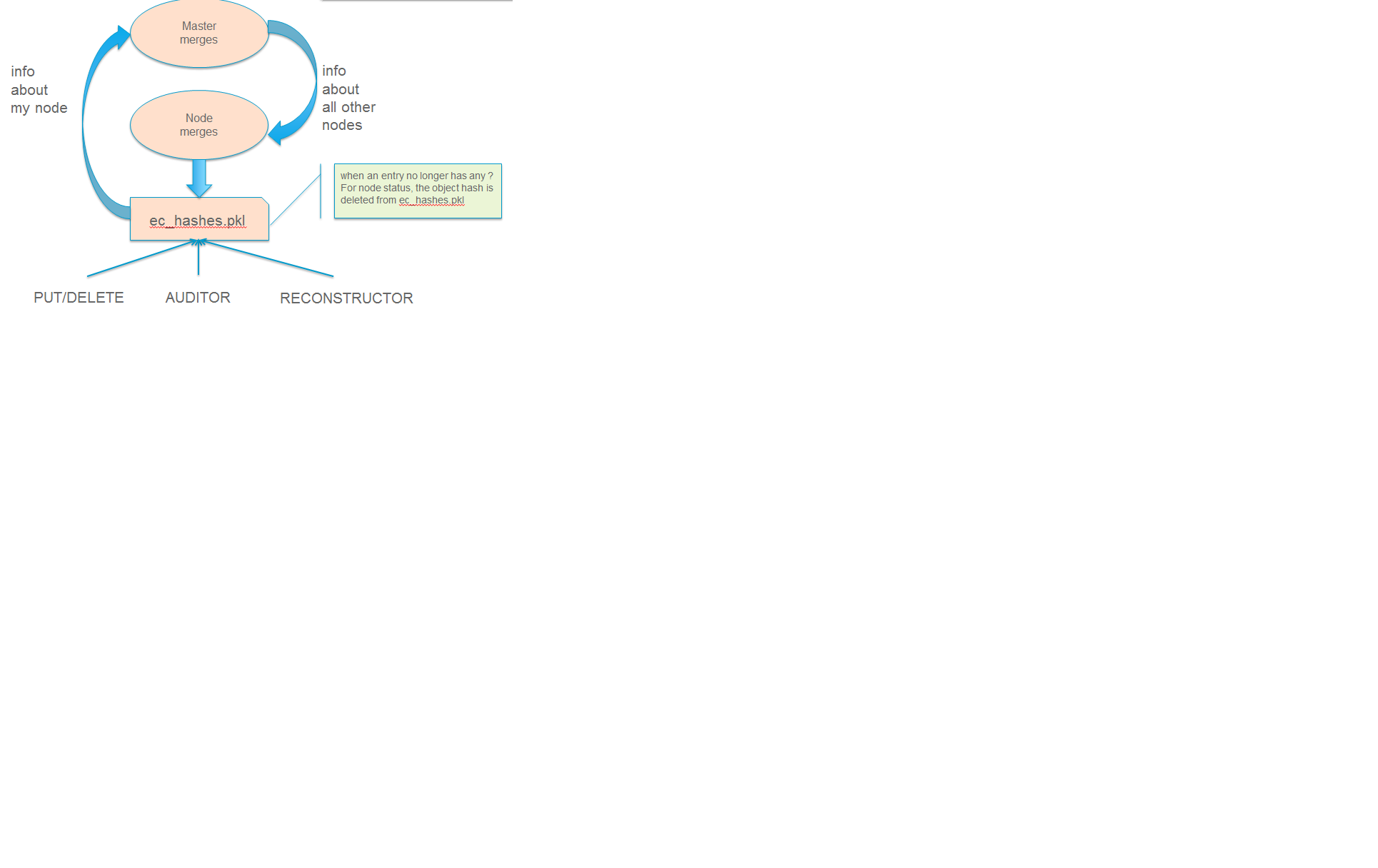
当 ec_hashes.pkl 文件更新时,适用以下规则
作为更新本地主文件与任何单个节点文件的哈希主节点:(回想一下这里的目标是使用有关传入节点的信息更新主节点)
- 数据永远不会被删除(即,如果对象哈希或 TS 键存在于主文件中,但不存在于传入字典中,则该条目保持不变)
- 可以添加数据(如果对象哈希或 TS 键存在于传入字典中,但不存在于主文件中,则会添加它)
- 当键匹配时,仅影响传入数据中的 TS 列表中的节点索引,并且该数据在主文件中被传入信息替换
作为合并来自主节点的非主节点:(回想一下这里的目标是让此节点了解集群中的其他节点)
- 一旦所有节点都被标记为存在,就会删除对象哈希
- 可以添加数据,与上述相同
- 当键匹配时,仅影响传入数据中的 TS 列表中的其他索引,并且该数据将被传入信息替换
一些示例
以下是一些示例场景(稍后用于帮助解释用例)及其相应的 ec_hashes 数据结构。
4. 实现
负责人¶
有几个关键贡献者,torgomatic 是核心赞助商
工作项¶
请参阅 Trello 讨论板
仓库¶
使用 Swift 仓库
服务器¶
N/A
DNS 条目¶
N/A